Retro computers need websites to visit. That is what this project is all about. The mass recreation of websites from the GeoCities Archive that are compatible with older web browsers. More to follow…
What a great idea - a real trip down memory lane!
1 Like
Thanks @europlus - The first thing to take care of is the ability for users to make contact in case they do not want their old GeoCities website reactivated. Enter the Digital Millennium Copyright Act (DMCA), using this we will provide a web form for copyright takedowns. Edit: I have also added the ability to report any illegal content that may be present.
I haven’t had any forms on my website for a long time due to bots and not wanting to have Google reCAPTCHA. hCaptcha is a new one that has appeared and seems to work well. The form I am using is WPForms Lite (free) as it seems to do everything I need it to do.
With that out of the way I can work on the actual content. Yahoo! acquired GeoCities in mid-1999 and messed with the city’s structure. This is how GeoCities was structured, for the most part, up until Yahoo!'s acquisition.
Each neighbourhood could hold 9999 websites:
GeoCities got too popular and needed suburbs inside those cities:
After Yahoo! took over, people had the option to use their YahooID instead or even alongside:
So you could have:
Yahoo | Mail, Weather, Search, Politics, News, Finance, Sports & Videos and Yahoo | Mail, Weather, Search, Politics, News, Finance, Sports & Videos serving the same content. A bit messy. Then there’s case sensitivity and localisations.
That’s why I am only targeting the pre-Yahoo takeover sites operational at this stage. So far I have a very much incomplete staging area at http://geocities.mcretro.net. Only about six of the Athens suburbs are active.
Server-wise the main server (mcretro.net) is a headless Raspberry Pi 4 running Ubuntu Server with a reverse proxy to the staging server (geocities.mcretro.net) on a Raspberry Pi 3.

All era-sensitive testing is completed on a MiSTer FPGA running ao486 via Windows 95/98. It has roughly the performance of a 486DX-33 (No FPU though…). So far it does not like loading the directory listing of 9999 items in Athens very much.
Then there’s the modems. I’ve got two Banksia Wave SP56s. Internally the boards are BT134 REV B and REV F. The REV F is cool as ice when running, REV B is toasty.

We dial between two modems locally thanks to this wonderful guide. I’m using an Cisco SPA112 that I won in a raffle coupled with an Asterisk server. All the bleeps and bloops without the cost of dialling outside my home.
Among the next steps will be working out how to migrate the data from a Mac APFS (case-sensitive) partition to a linux ext4 (case-sensitive) partition that can be mounted with appropriate permissions for apache2 on the RPi3 web server.
5 Likes
Wowsers! Once I hit the modems, my head went 
Massive project, but I love the idea of not just bringing the sites back, but bringing so much authentic experience to it.
I’ve not played with a Mister, I keep getting intrigued but must admit cost has been a barrier.
Talk soon,
Sean
Here’s the details of the WOzFests I’m holding - feel free to join via Google Meet.
And I might even be able to have 10 attendees at WOzFest 22!
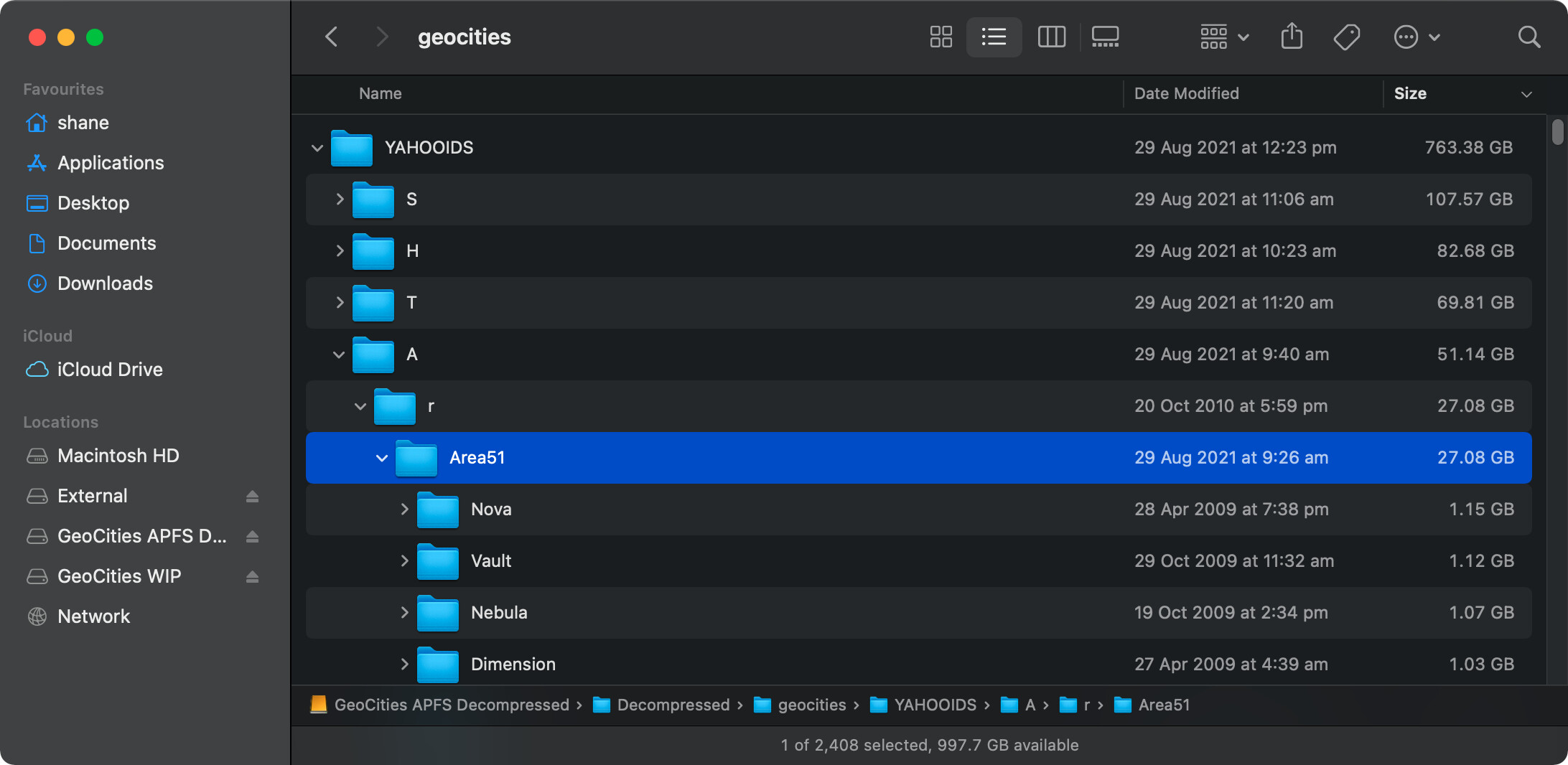
Here’s the type of structure we are dealing with. Just Area51 alone has over 1,000,000 files and weighs in at a hefty 27GB. It also contains suburbs such as Nova, Vault, Nebula, Dimension. The parent directory YAHOOIDS is a bit of mess as it contains account names. That’s one of the reasons I would like to see the easier neighbourhoods (pre-Yahoo!) dealt with first. Then I could potentially move on to the chaos Yahoo! created when took over GeoCities.

And the clone begins! We’re going from an APFS (case-sensitive) partition to an ext4 (case-sensitive) partition. The initial clone to create a backup to rotational media took over 60 hours. There’s almost 1TB of data here and so very many small files. I’ve since upgraded to a set of SSDs, which looks like it will have been a good investment.
I still need to work out the mounting parameters and whether overriding ownership for all files on a file-system (without actually modifying the file metadata stored on the filesystem) or if I should just make www-data the owner. It takes a loooong time to apply permissions though and I don’t doubt I’ll probably need to reclone the entire data set at some stage. Bindfs is one possible avenue to take, I’ll have to get reading into how it all works.
This project shouldn’t be completed before the end of October but we should have something to show. I had been working on the modems tying in with the MiSTer since April. Then I accidentally deleted my desktop in July and lots a whole heap of notes. My backup was a few weeks old, but much was lost. Thankfully MiSTer has also been progressing which allowed support of the FTDI’s FT232RL chipset along with Prolific PL2303 for connecting these serial modems over USB.
@europlus Re: The MiSTer - Space has always been a premium for me unfortunately. Having a MiSTer in place of a bunch of consoles makes sense for me. I was also amazed by the accuracy of the SNES core. One particular game that made me really notice the accuracy was a side-scrolling shmup, Earth Defense Force. At various points there’s too many sprites (bullets) for the SNES to handle. And the MiSTer replicated it perfectly. The accuracy coupled with the space saving form factor of the MiSTer made it a no-brainer! YMMV of course! ![]()
2 Likes
It’s amazing! It looks like I’ll be able to clone across from my APFS formatted drive with relative ease. However, I will still have to apply the following permissions once mounted, as it is an ext4 formatted drive:
- sudo chown www-data:www-data -R *
- sudo find . -type d -exec chmod 755 {} ;
- sudo find . -type f -exec chmod 644 {} ;
I guess I’ll just have to wait out the 32,000,000 files and directories! I’m using extFS for Mac by Paragon Software to copy between drives.
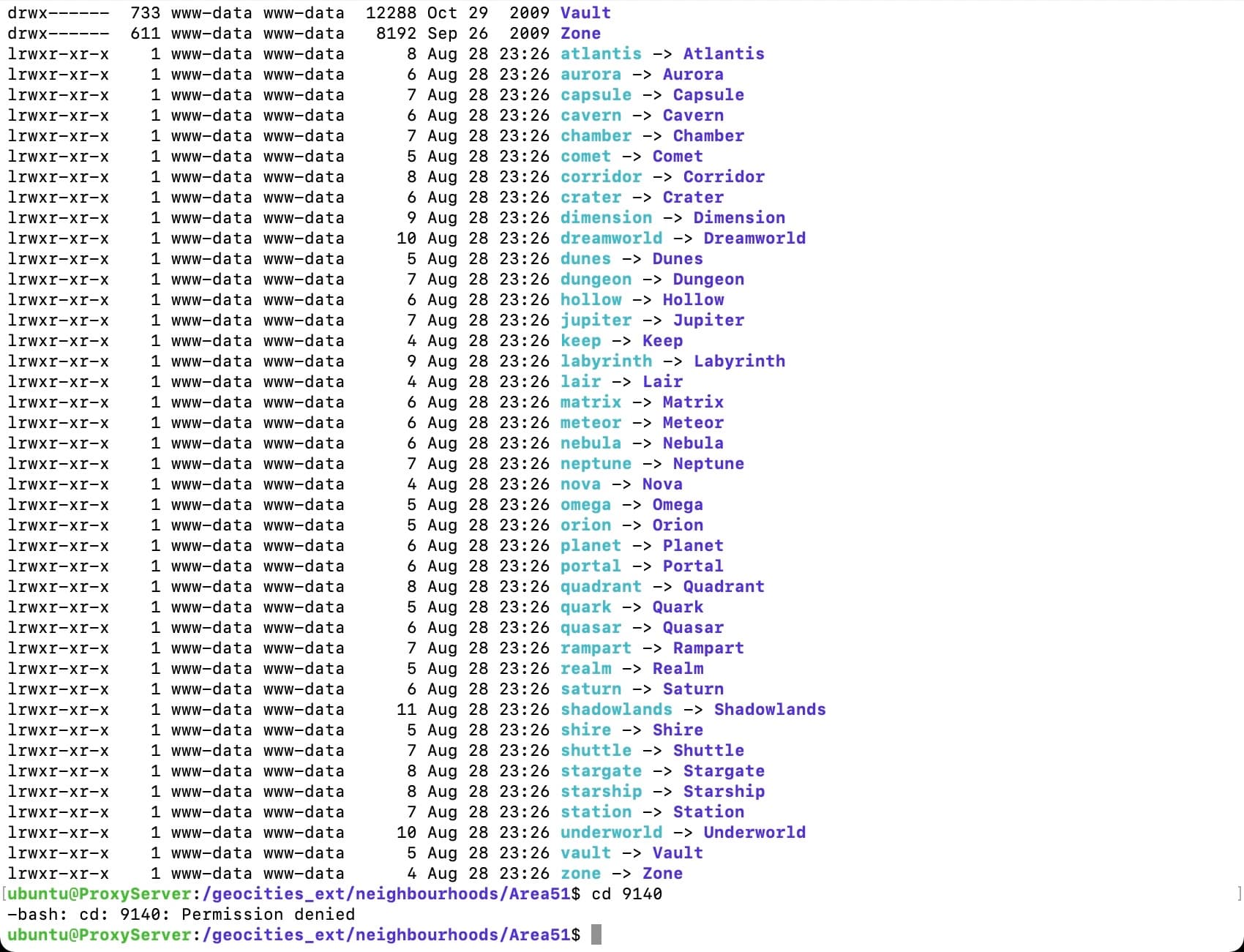
I am very glad to see that the symlinks survived. Now it’s on to trying to determine the best way to structure the drive. All the links in the table on https://geocities.mcretro.net/#Area51 should now be active - at least until I try copying more data to it.
2 Likes
I want to really just know how many times marquee features in these pages proportionally to today’s hefty 0.00001%
I don’t think I’ll be going down the bindfs route. It seems to introduce overheads without the benefits. At least not when using ext4 as the target filesystem. So I’ll mount the external hard drive straight into the /var/www/html folder with the following command:
sudo mount /dev/sdb2 /var/www/html/geocities
I had been considering mounting the drive as read only with:
sudo mount -oro,noload /dev/sdb2 /var/www/html/geocities
But then I wouldn’t be able to make any changes on the fly via samba. For reference this was the bindfs command that would have been used, just in case I change my mind down the road.
sudo bindfs -o create-with-perms=0644:a+X,force-group=www-data,force-user=www-data,create-for-user=www-data,create-for-group=www-data /media/geocities_ext/neighbourhoods /var/www/html/geocities
It looks like there’s a faster way to change permissions that I wasn’t aware of until today too.
cd /var/www
sudo chown www-data:www-data -R *
sudo chmod -R a=r,a+X,u+w .
That last line is a replacement for:
sudo find . -type d -exec chmod 755 {} \;
sudo find . -type f -exec chmod 644 {} \;
and then to unmount the partition and play with the data we just run:
sudo umount /var/www/html/geocities

Above is the list of the primary, “core”, neighbourhoods. Inside these are subfolders numbered up to 9999. Then there’s also “suburbs”, I guess inside these. Each containing up to… you guessed it 9999 subfolders. There’s around 470GB of data saved here, another ~250GB appears to be for individual account names. I am not touching that with a ten-foot-pole just yet.
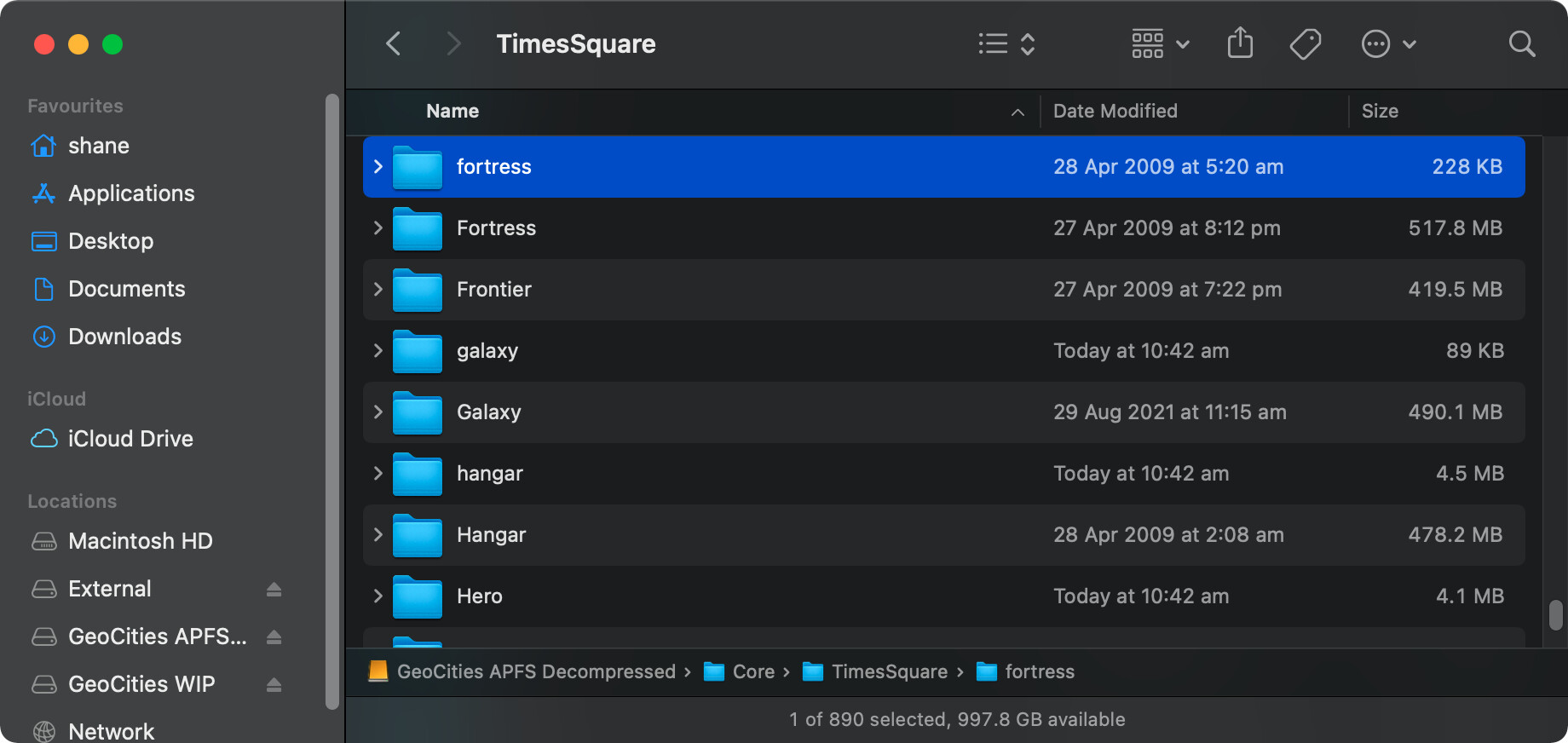
As you can see above though, there’s going to be some duplication of data. I need a tool which will be able to compare and merge if identical. Interestingly I have all core folders except Broadway. I guess someone didn’t like theatre!
I’ve been looking at diff for comparing based on md5sum, but it still seems too much work for little payoff. There might be an Apache2 module that helps with this, but first I’ll see what tools are available that are a little more user friendly. First up, Meld.
@DigitalRampage I suppose it depends on if the page was optimised for Netscape or Internet Explorer. ![]()
2 Likes

2 Likes
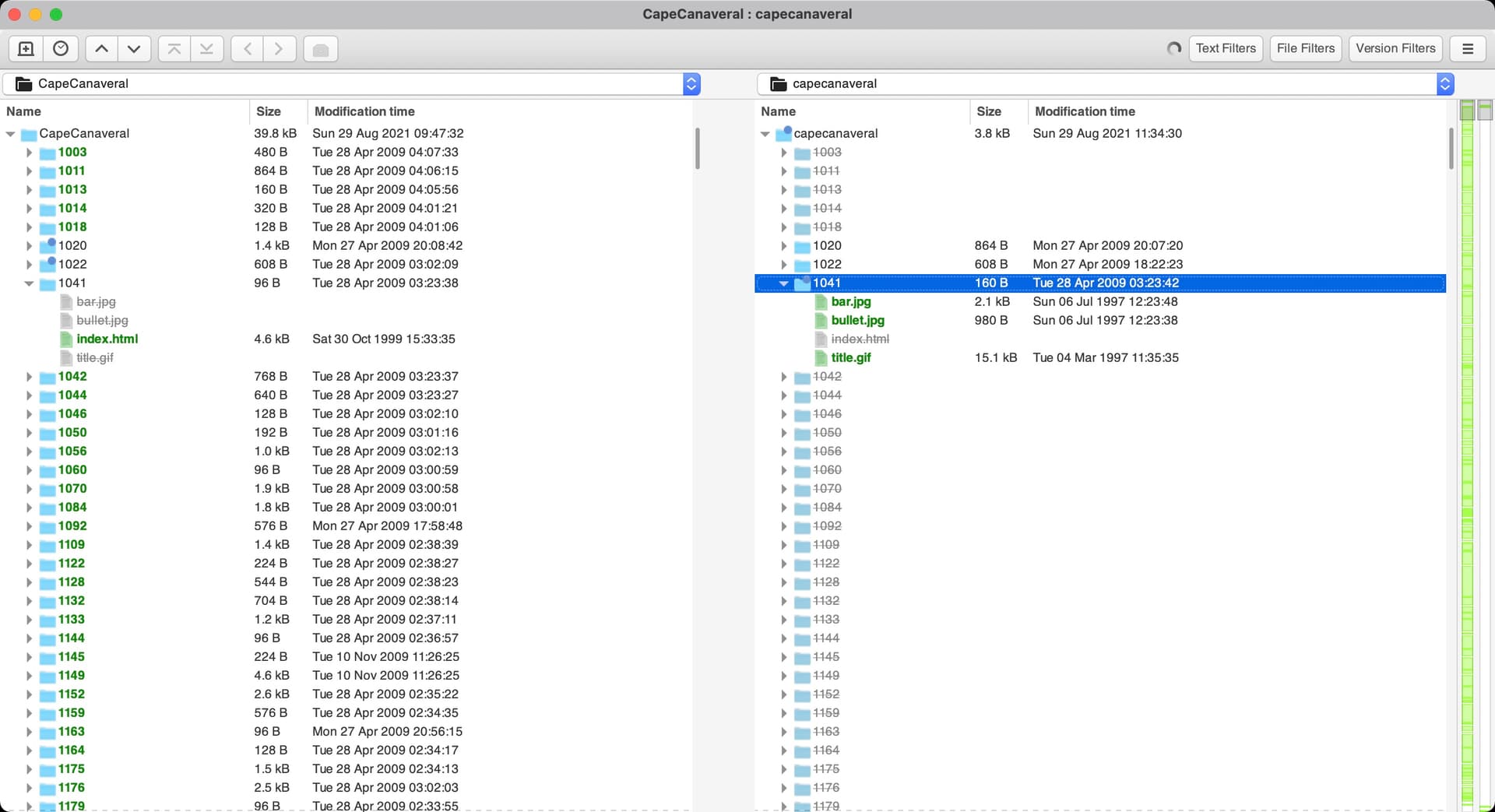
Meld wasn’t too bad, but seemed to be a little clunky and I couldn’t quite work out how to merge two directories including their subfolders. But it did give a great visual representation of the issues we are facing when it comes to case sensitivity. As you can see above we have CapeCanaveral on the left and capecanaveral on the right. Left has the index.html and the right has a few images (but no index file). A great example, unfortunately the learning curve looked to be a bit too steep for what I needed to do. Meld did not like scrolling very much. It might have been because it was an Intel binary running on M1.
Then I remembered, Carbon Copy Cloner might be ideal for this. Carbon Copy Cloner 6 seems to offer comparisons which are nice, but the SafetyNet feature didn’t work as I was expecting.
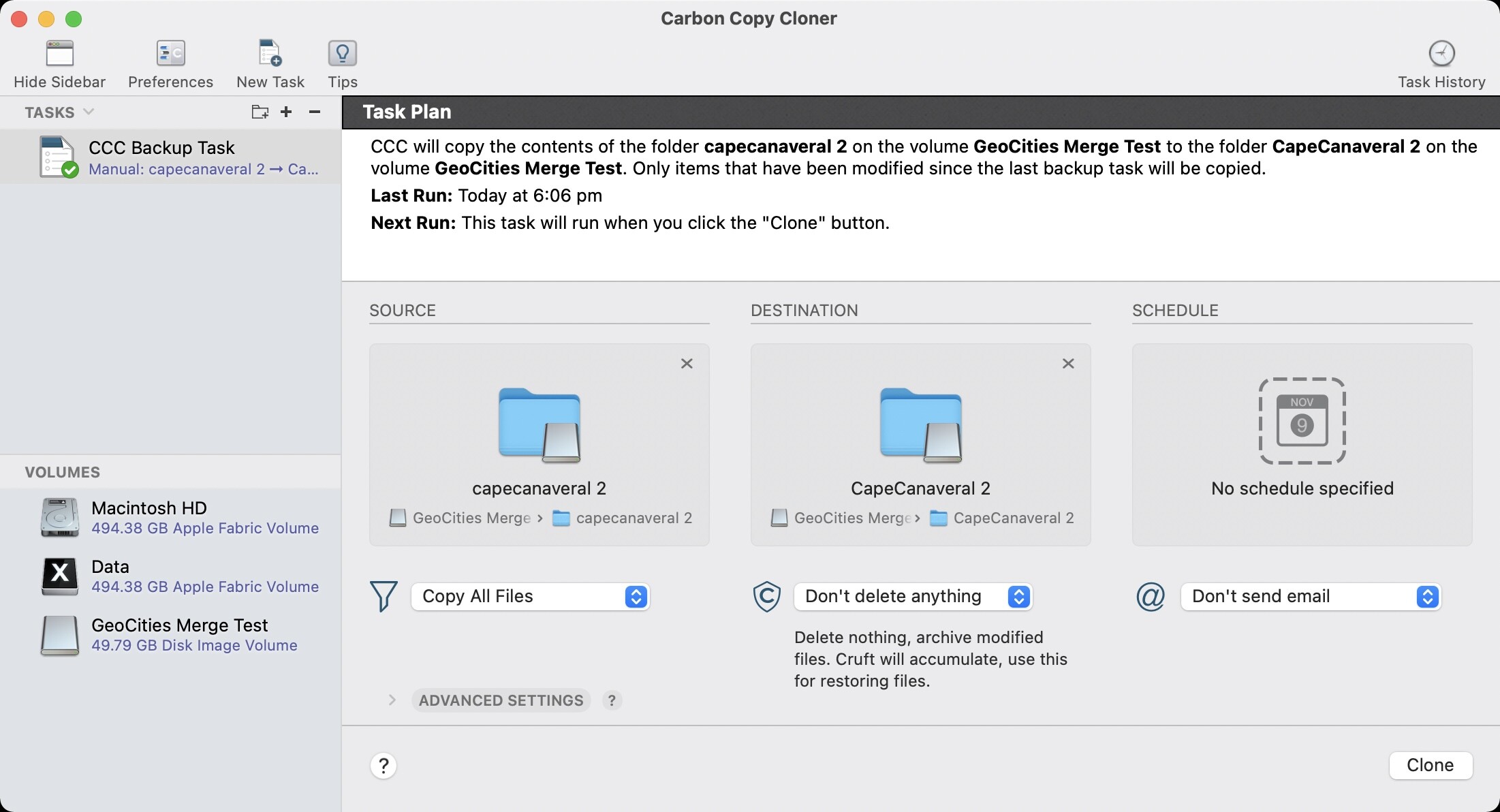
Downgraded to Carbon Copy Cloner 5 and it works well enough. I don’t know what changed under the hood between CCC 5 and CCC 6 as the settings all looked the eerily similar. We ended up with a “_CCC SafetyNet” which contained only the older of two files when compared side by side.
The SafetyNet appears to be the older files of duplicate data. These appear to be duplicated when CapeCanaveral/XXXX vs capecanaveral/XXXX were captured at different times at the end of GeoCities. A few hours here or a day there isn’t going to make a world of difference in the grand scheme of things here. I’ll hold onto these “_CCC SafetyNet” folders for now though, they don’t use much space. CCC5 gets a big tick of approval.


Beyond Compare was another program worth mentioning, it is very similar to Meld, but feels far more responsive and well built. As you can see the above interface is quite familiar looking but a little overwhelming when trying to decode; definitely one for the power users - not me.
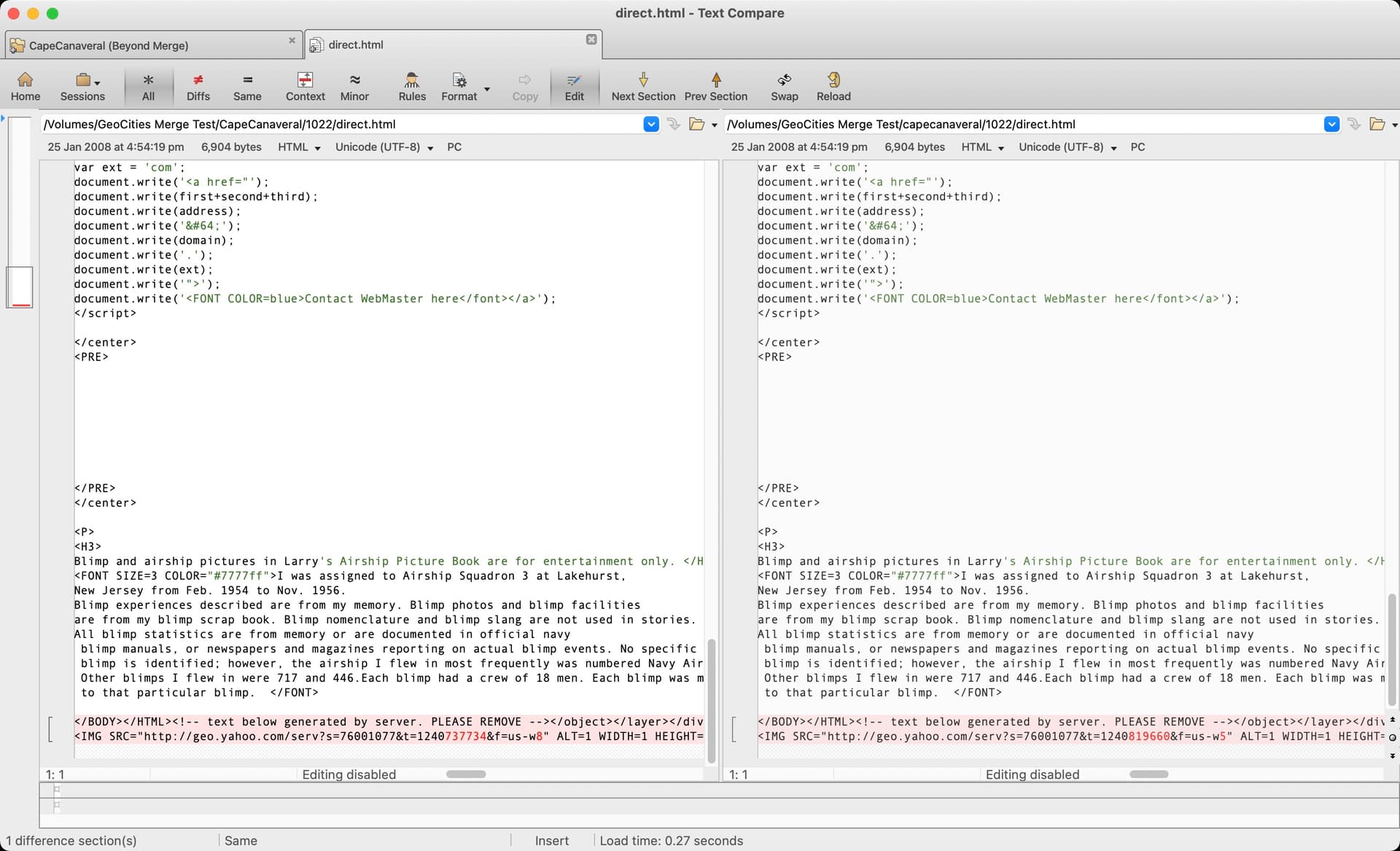
Above is another screenshot from inside Beyond Compare, and you can see the captured data from GeoCities varied by only a few bytes, in the red highlighted section, for some server generated text. This is why merging the case sensitive neighbourhoods is such a pain. “CapeCanaveral” and “capecanaveral” both had this html file scraped at separate times. It’s a miracle the Archive Team got what they did! ![]()
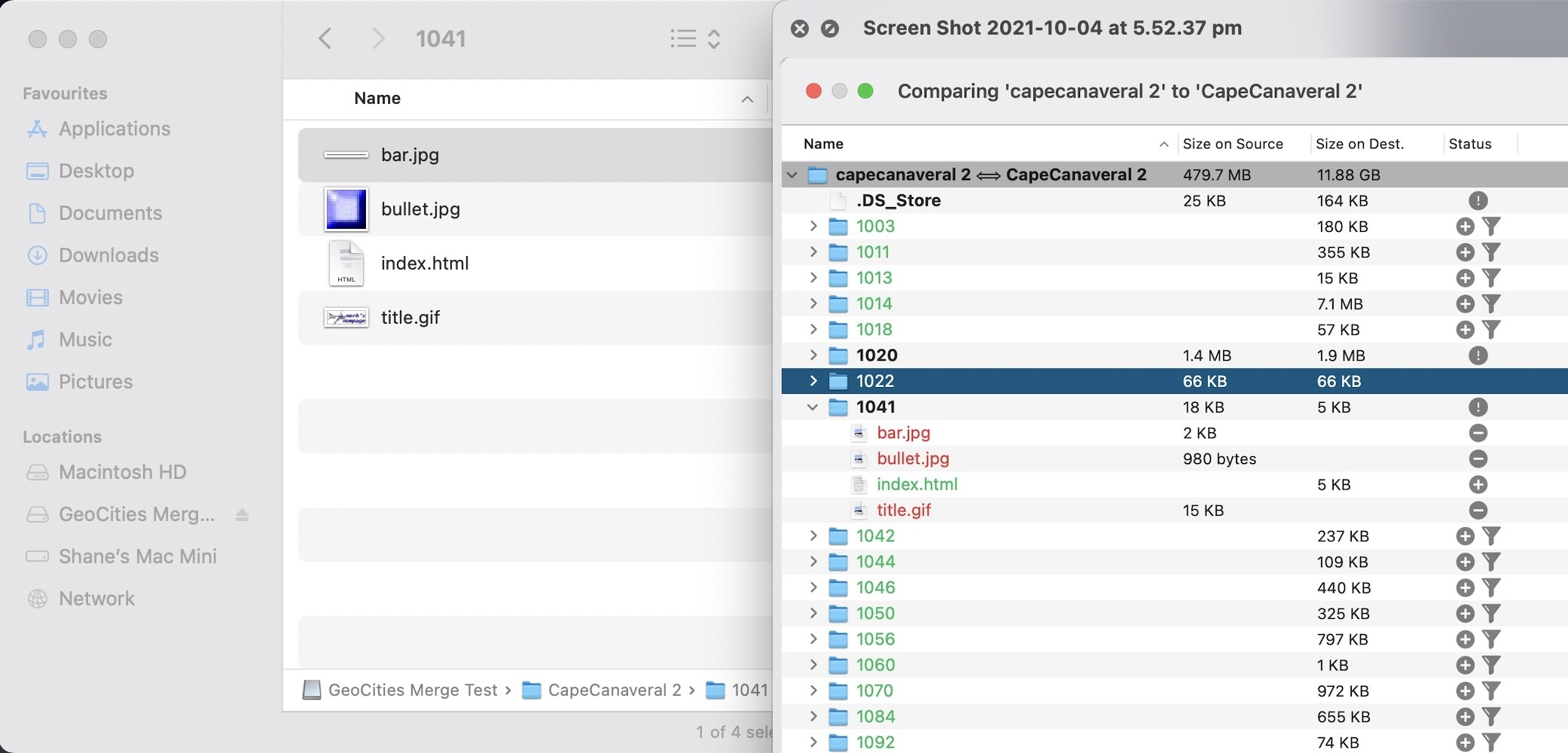
As you can see above, from the example earlier, CapeCanaveral/1041/, has successfully merged using CCC5. We’ll stick with CCC5 for merging the “core” neighbourhoods. The suburbs inside the core neighbourhoods will need to be sorted also. Not quite sure how to do that yet. And in the next screenshot we have CapeCanaveral/Galaxy/1002/ now showing a full directory.
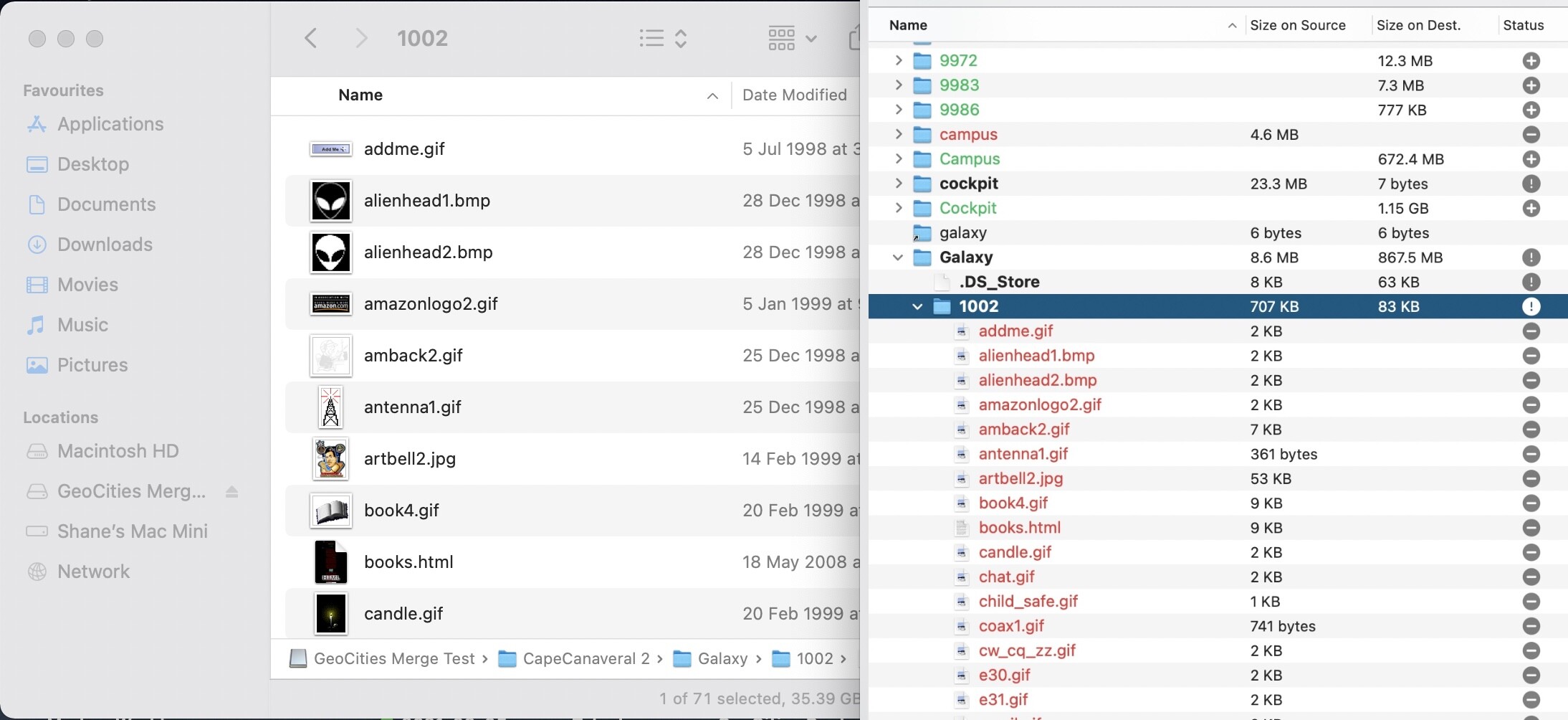
Once I work out how to get all the suburbs into their correctly capitalised folders, I’ll need to create symbolic/soft links to join capecanaveral, capeCanaveral, and Capecanaveral to CapeCanaveral. Unless Apache has a way to help with this issue.
1 Like

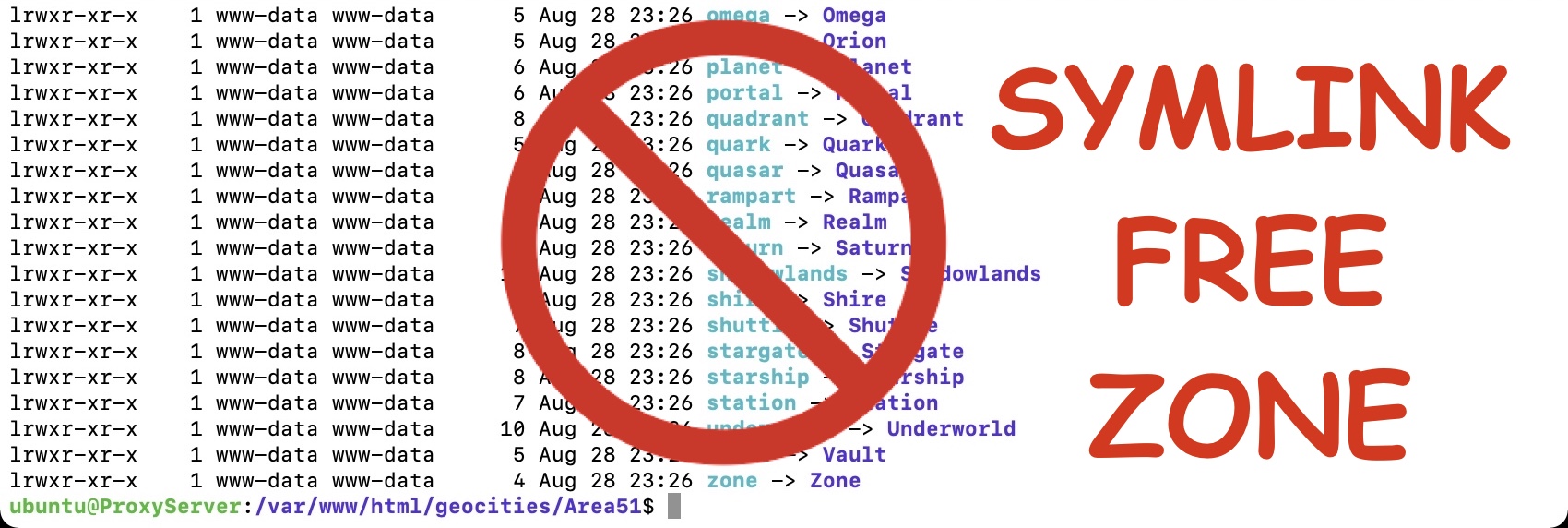
Alright, so we’ve had data cloning back and forth. What damage have we done to the permissions and symlinks? Thankfully the symlinks look to be intact - they are denoted by the l at the start of the permissions. d indicates a directory and - would be a file.
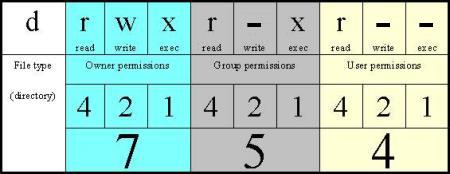
I had no idea that this is how they worked. Setting a directory to 755 (drwxr-xr-x) and a file to 644 (-rwxr--r--) is what I was doing earlier. Neat! Anyway, hall redirects to Hall OK in the image two above. I went through and manually tidied up the “Station” folder, so there is no longer a lowercase “station” folder. I’ve created a symlink on my Mac using:
ln -s Station station
Which creates the following new symlink:
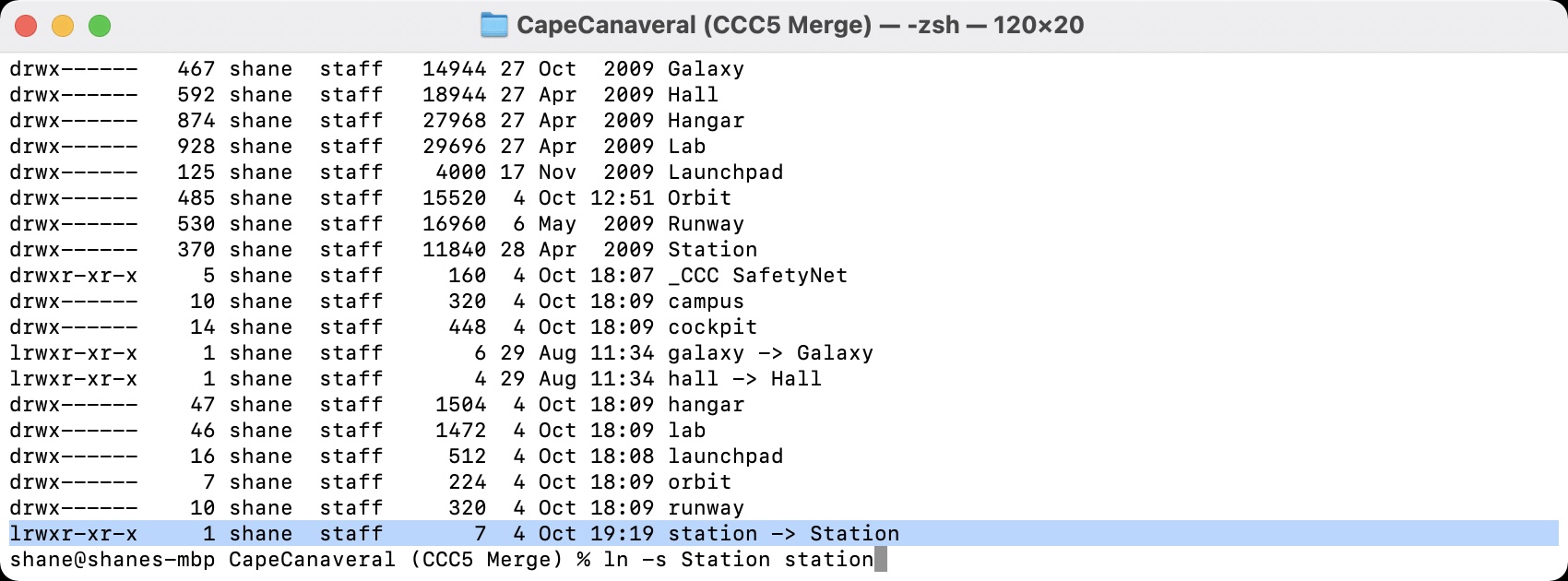
Which we can then check in Finder, and it appears to be working well.

With symlinks working for now, we still have a lot to tidy up before we can start symlinking everything. The image above shows that there are still multiple folders with different cases. I need to unify them as one and then create symlinks in case someone has referenced /symlink/ instead of /SymLink/.
1 Like
Oh, yes! This. https://httpd.apache.org/docs/2.4/mod/mod_speling.html
sudo a2enmod speling
We’ve placed the following in VirtualHost configuration file inside Directory tags:
# Case-insensitive
CheckSpelling on
CheckCaseOnly on
and a quick restart of apache2.
sudo service apache2 restart

Ahh wrong permissions are set on the web server. We had used Carbon Copy Cloner 5 to copy back onto “GeoCities APFS Decompressed” from the temporary sparse disk image bundle to maintain the case-sensitivity. We then copied from the APFS partition back onto the ext4 partition with CCC5.
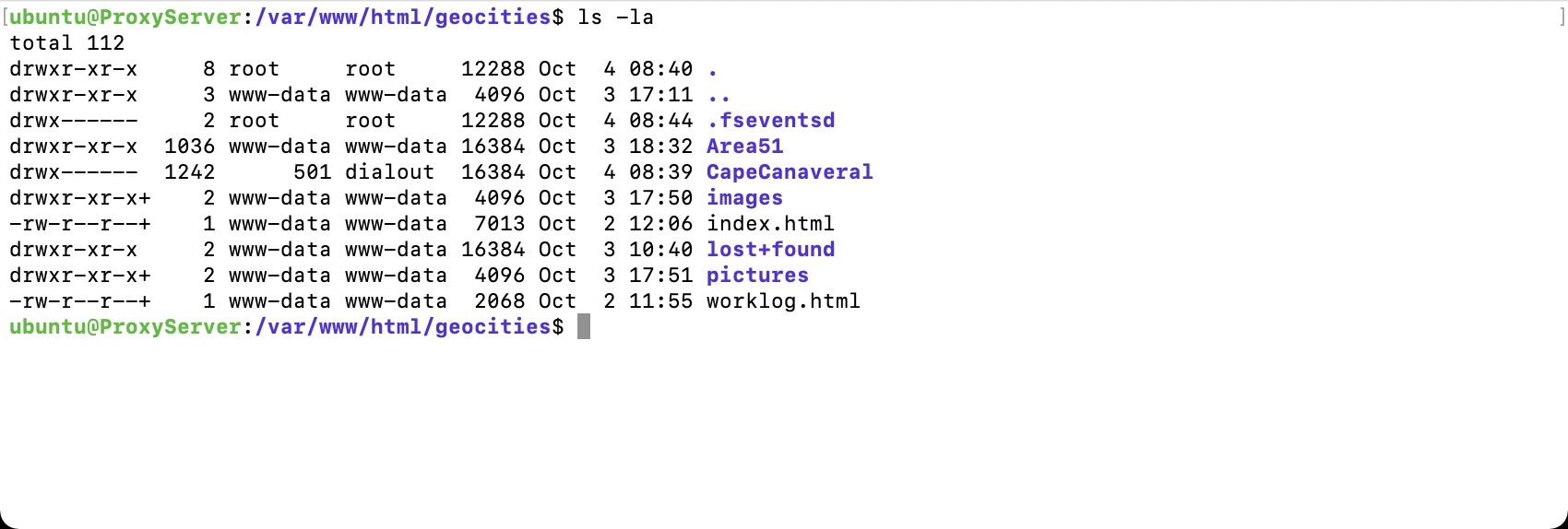
This gave me some weird permissions, 501:dialout against the CapeCanaveral directory.
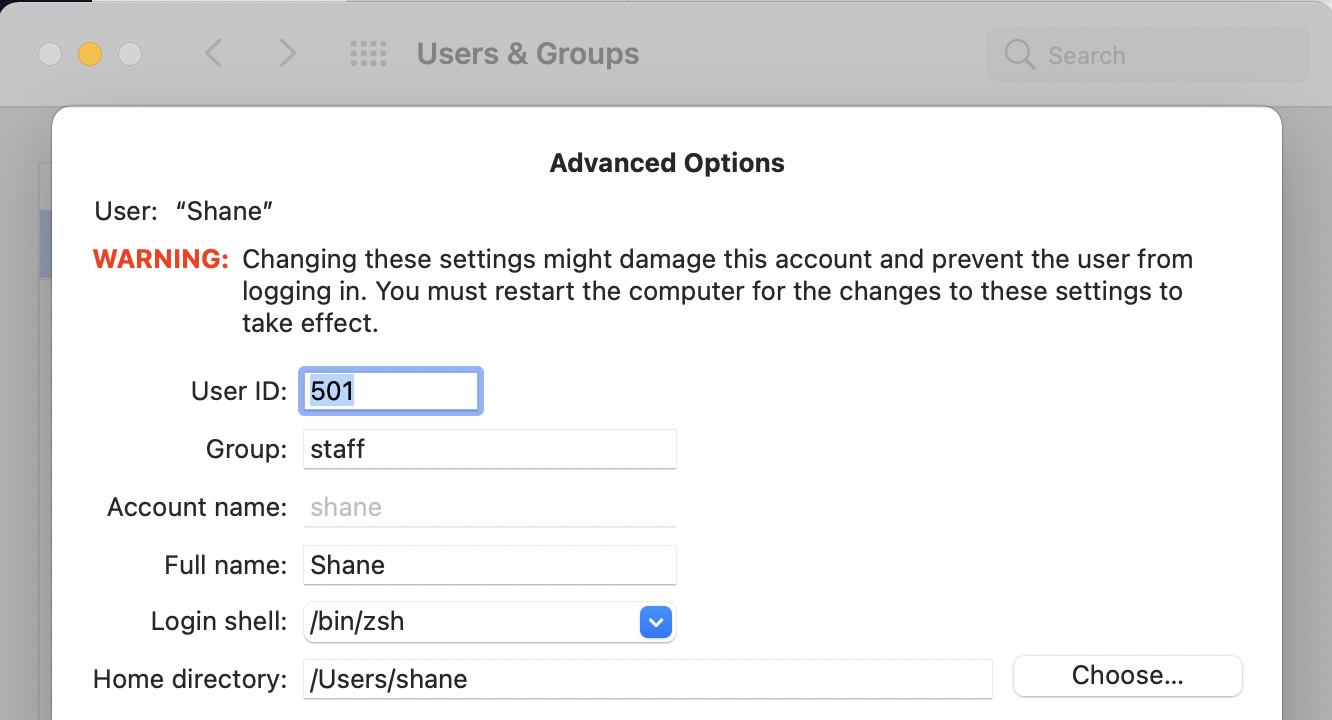
Turns out 501 is the default User ID for Mac OS. Mystery solved! A quick run of the below commands fixed up the permissions issues and…
cd /var/www
sudo chown www-data:www-data -R *
sudo chmod -R a=r,a+X,u+w .
Apache’s mod_speling allows us to have the expected, correct capitalisation:
https://geocities.mcretro.net/CapeCanaveral/
As CapeCanaveral only exists by itself, trying to load the following:
https://geocities.mcretro.net/capecanaveral/ results in…
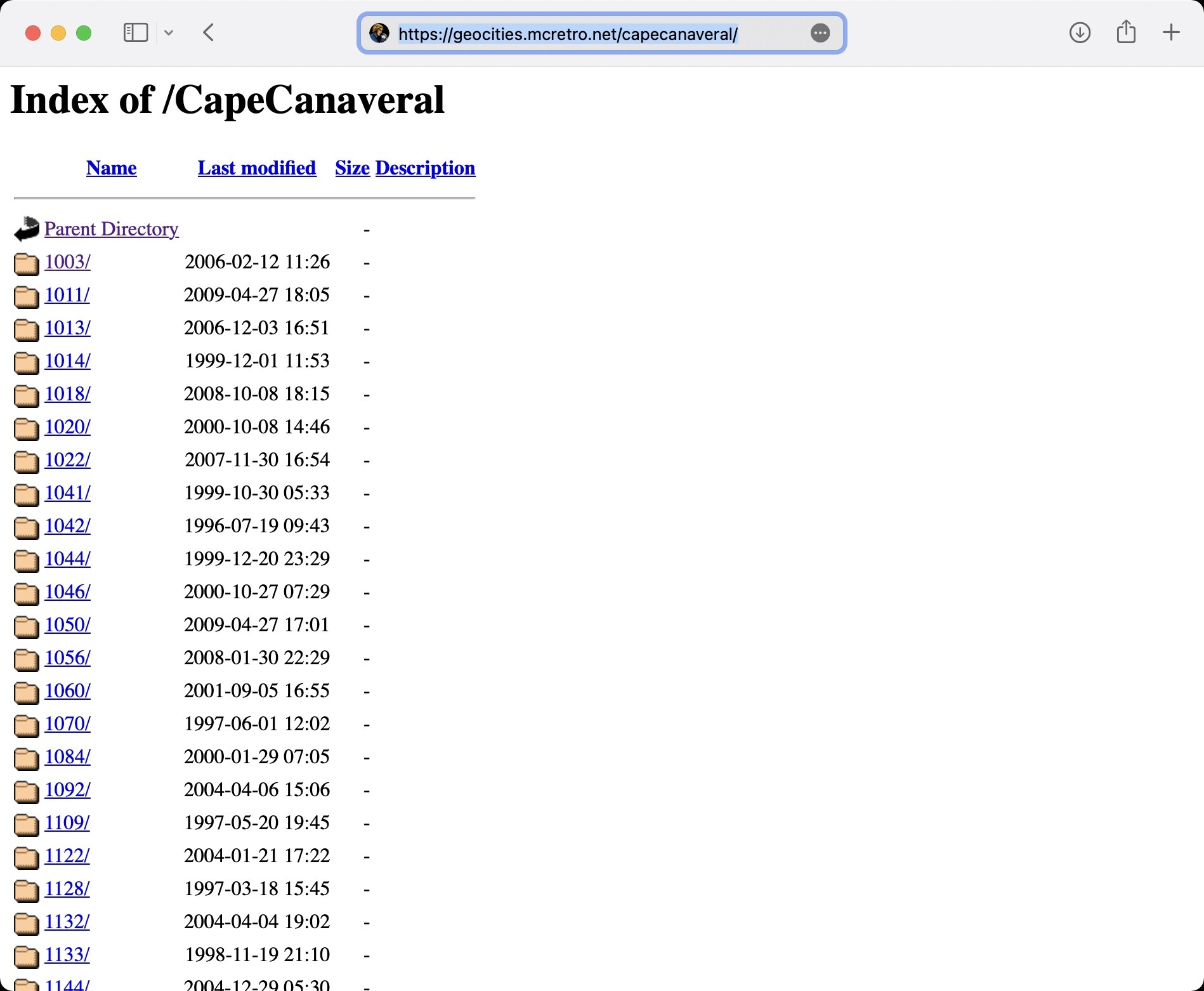
A redirection to https://geocities.mcretro.net/CapeCanaveral/ … I guess I won’t be needing those symlinks after all thanks to Apache’s mod_speling.
And that’s it for the weekend. Feel free to stop by http://geocities.mcretro.net and test out Area51 or CapeCanaveral. Don’t press anything in Athens, it isn’t working just yet! ![]()
3 Likes
")
This weekend I’ve been taking it easy due to giving a blood donation on Saturday. Perfect opportunity to test out the website on as close as I have to real hardware - while live streaming. Interestingly Netscape 4 feels clunkier and slower than Internet Explorer 5. Maybe I backed the wrong horse on this one.
For now I’m going to get the neighbourhood list tabled up and cross checked between a few sources and with the WayBack Machine itself.
1 Like
Shower thoughts. They hit you with the greatest clarity but rarely make it out. This one survived.
For the past couple of days I have been trying to think about how to get a header to stick at the top of the page to allow “teleport” to another random page, head back to the neighbourhood list, etc.
I haven’t been able to use basic php as it would result in the location bar URL simply returning http://geocities.mcretro.net - useless for takedowns or knowing where you are in the archives.
I tried a few things, mostly seeing if there was a way to use javascript to rewrite the location bar URL. In hindsight, I think I may have been thinking about this back-to-front.
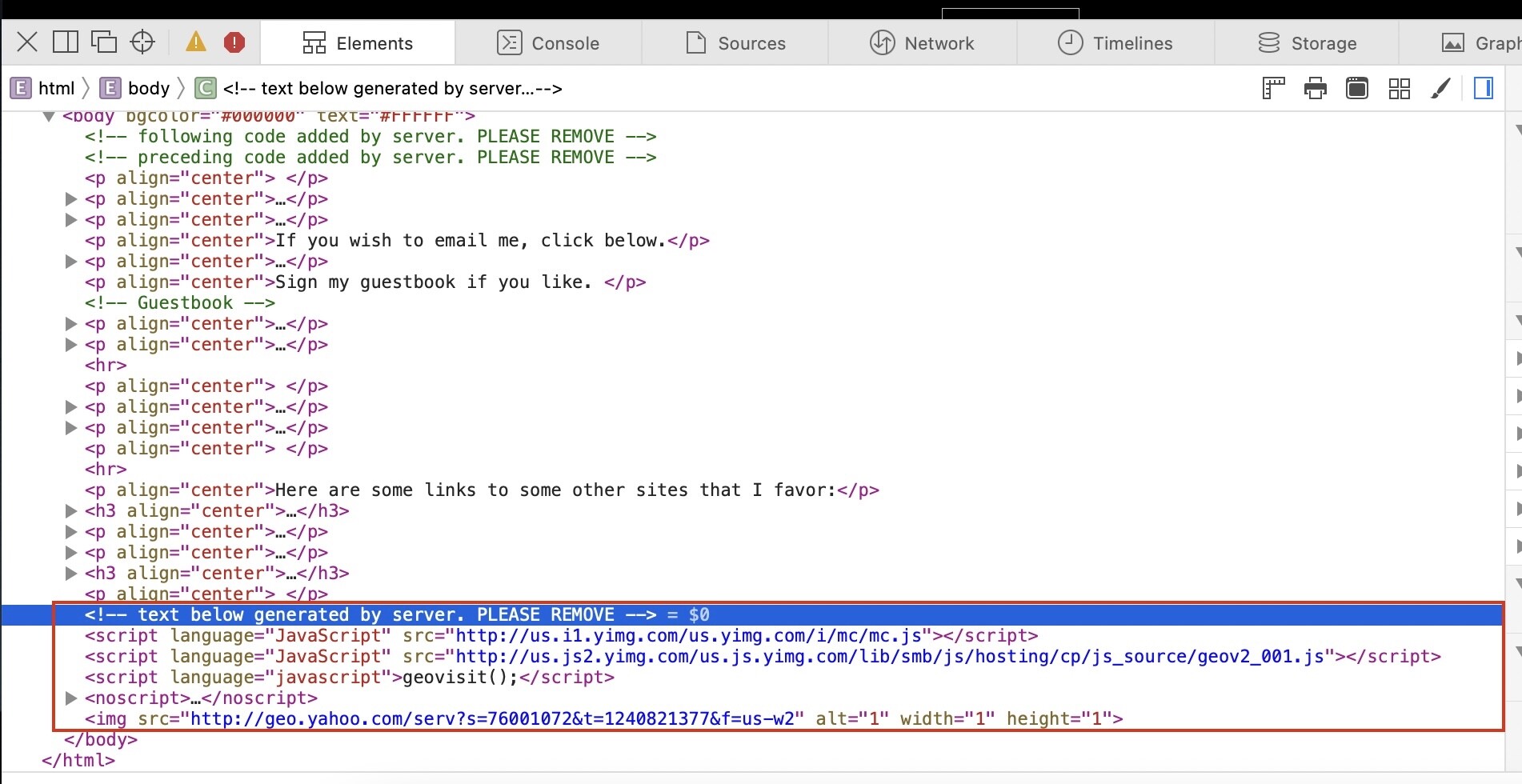
Late last night I was looking into the section boxed in red in the above image. It seems to be on almost every archived html page. I went to sleep.
This morning, in the middle of my shower, it hit me. Could the Yahoo! server-generated code be replaced with a new script for inserting a header? Now that I know mod_substitute exists, this might just work.
I needed something big and flashy to stand out so I made a Pickle Rick gif and added the following inside the VirtualHost tags:
Substitute 's|<script language="JavaScript" src="http://us.js2.yimg.com/us.js.yimg.com/lib/smb/js/hosting/cp/js_source/geov2_001.js"></script>|<img src="http://geocities.mcretro.net/pictures/pickle.gif">|i'
And what do we have…
Giant. Spinning. Pickle.
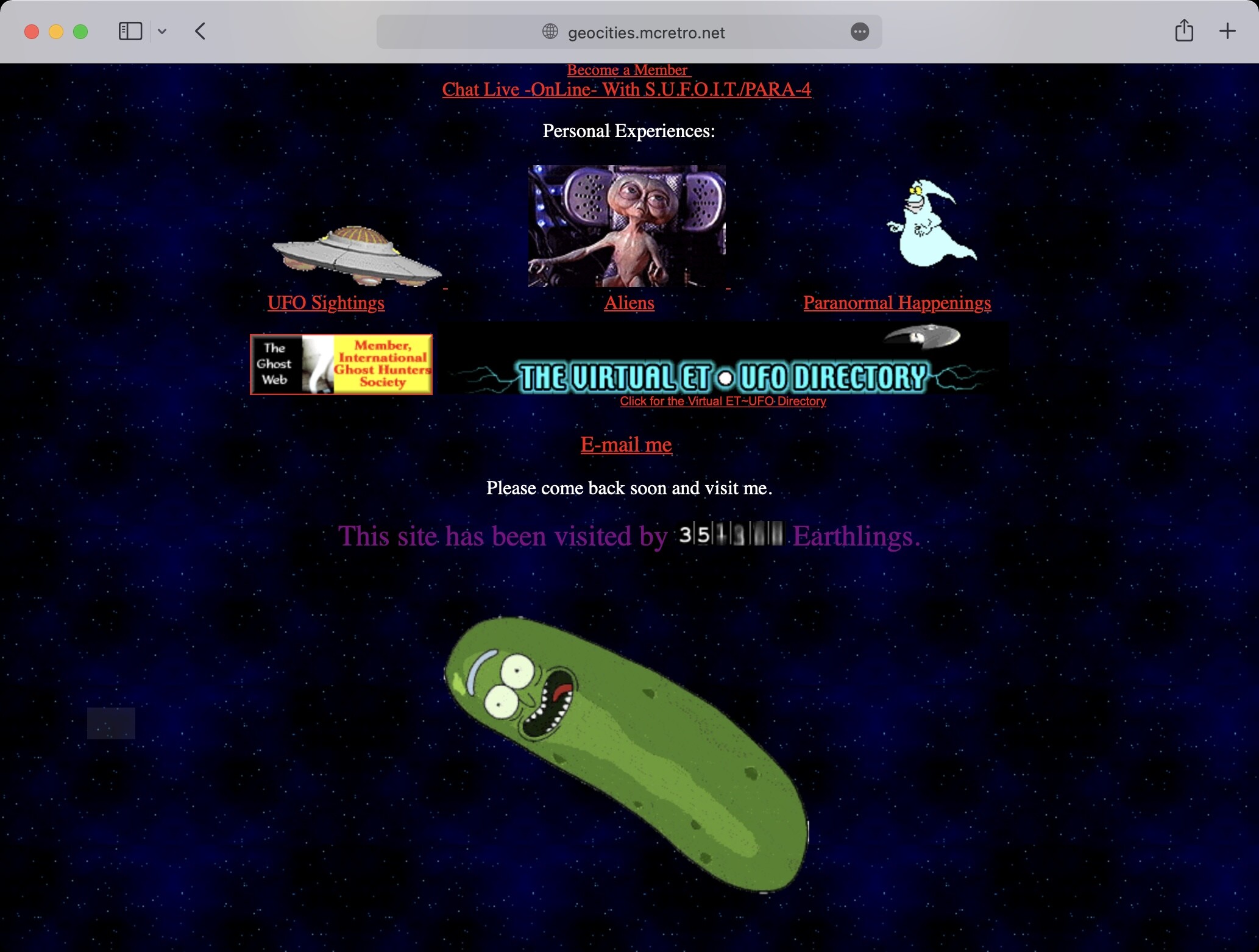
Yes, it’s possible! And when coupled with mod_cache, the substituted result can be saved for later viewing with less strain on server resources. I could possibly use this in several ways:
- Add a navigation header by injecting javascript of my own.
- Add a navigation footer, instead of a header, by replacing the closing
</body>tag in the HTML.
Back to the first image. In the red box there is also additional, possibly global, code that could be removed or replaced. I know the last image source carries a relatively unique timestamp, which means I may need to use some fancy strings to remove or replace it.
Another issue I remembered was that the pages without an index.html or index.php file that just return a file listing could possibly also use the header / footer feature of Apache2 to insert a similar header / footer.
So for now there is a spinning pickle on all the pages that are up, until a header is added. Definitely check out CapeCanaveral and Area51 to see if you can find any without spinning pickles. What a time to be alive. I better get back to creating the neighbourhood pages.
2 Likes
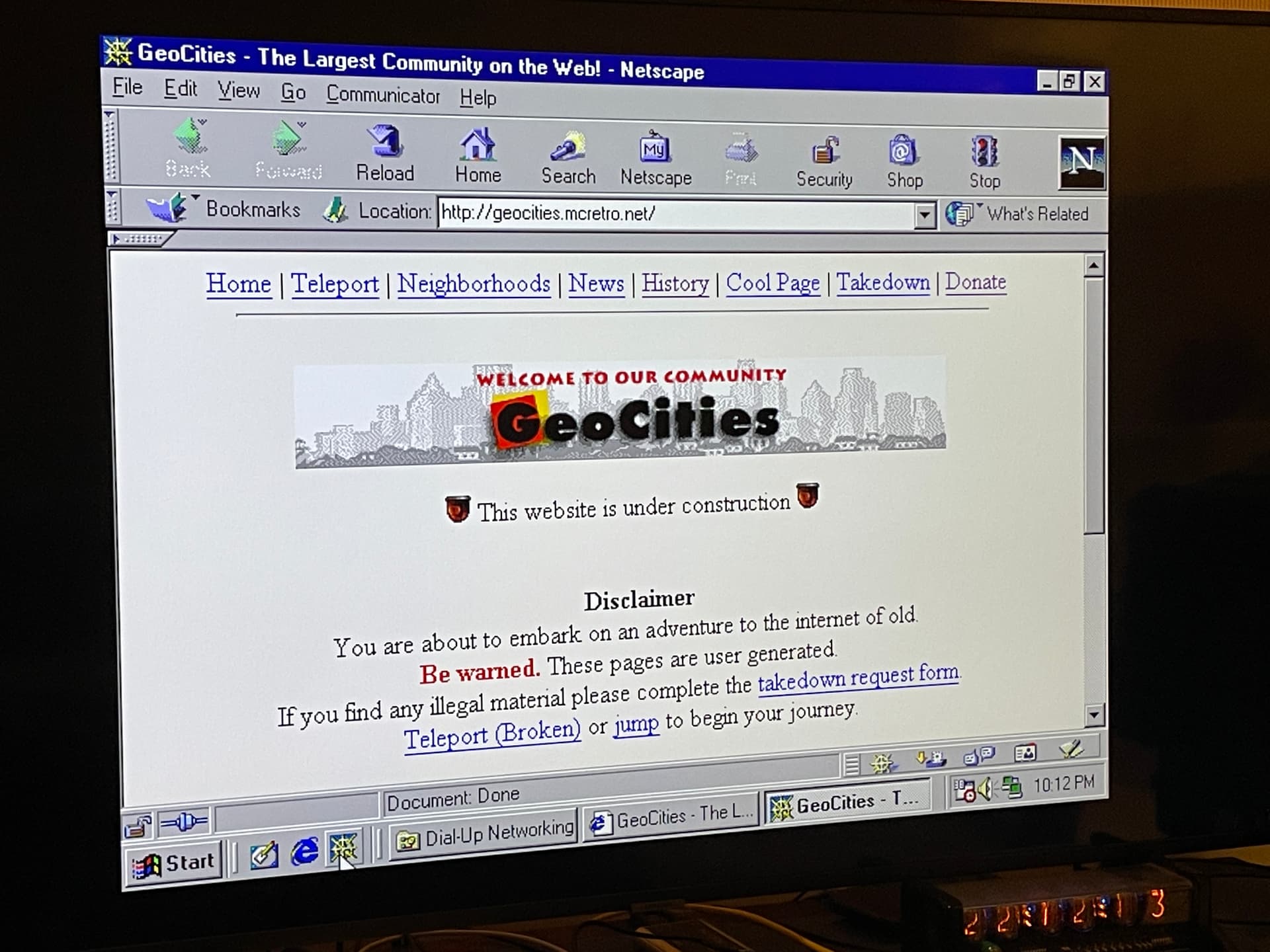
A quick redesign to make it a little nicer, still a work in progress - it wouldn’t be a GeoCities website if it wasn’t under construction after all.
Being able to teleport or jump to random sites inside the GeoCities archives is going to need a list of all available links to jump to. A sitemap.xml file should help us with that. That will be the database of available links for jumping.
To generate a sitemap we’ll need a… sitemap generator. I’ve decided on the aptly named Sitemap Generator CLI. I decided it would be best to run it on one of the Ubuntu 20.04 servers. Installation was straightforward.
sudo apt update
sudo apt install npm
sudo npm install -g sitemap-generator-cli
Then the generation of the sitemap.xml file. Unsurprisingly, this will also serve as a sitemap for Google, Bing and others crawling the website for links. Depth of 4 seems to be sufficient to capture the majority of user data.
sitemap-generator http://geocities.mcretro.net --verbose --max-depth 4
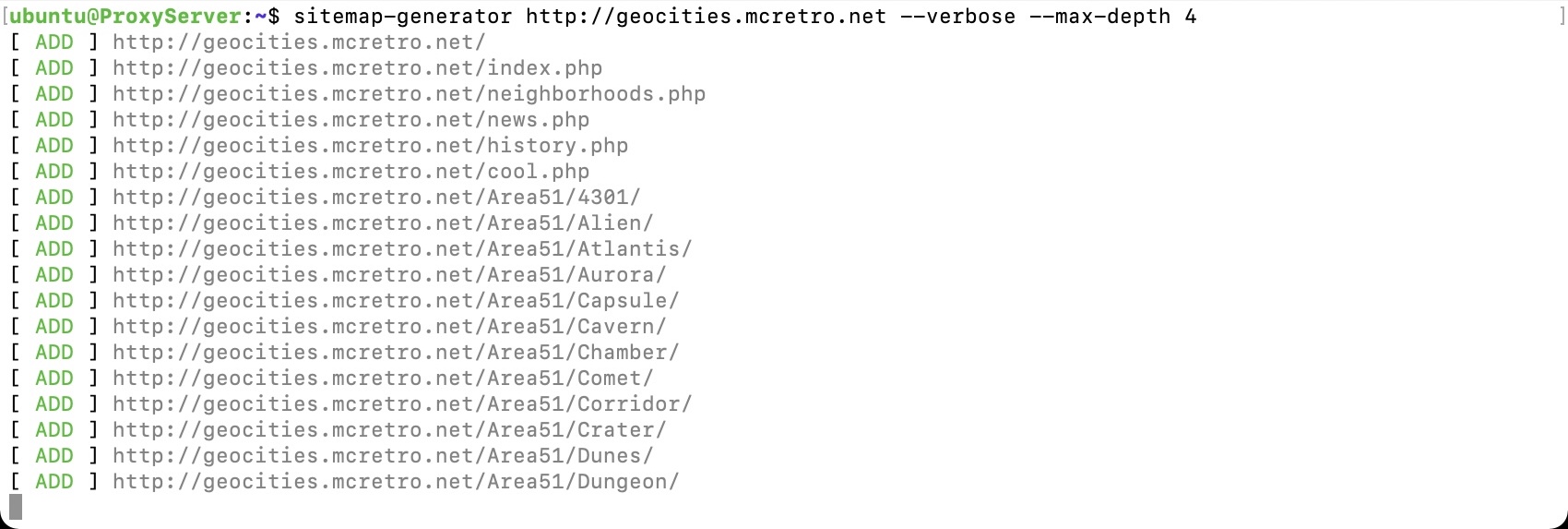
After waiting what felt like a few hours, move the sitemap into the appropriate folder:
sudo mv sitemap.xml /var/www/html/geocities/
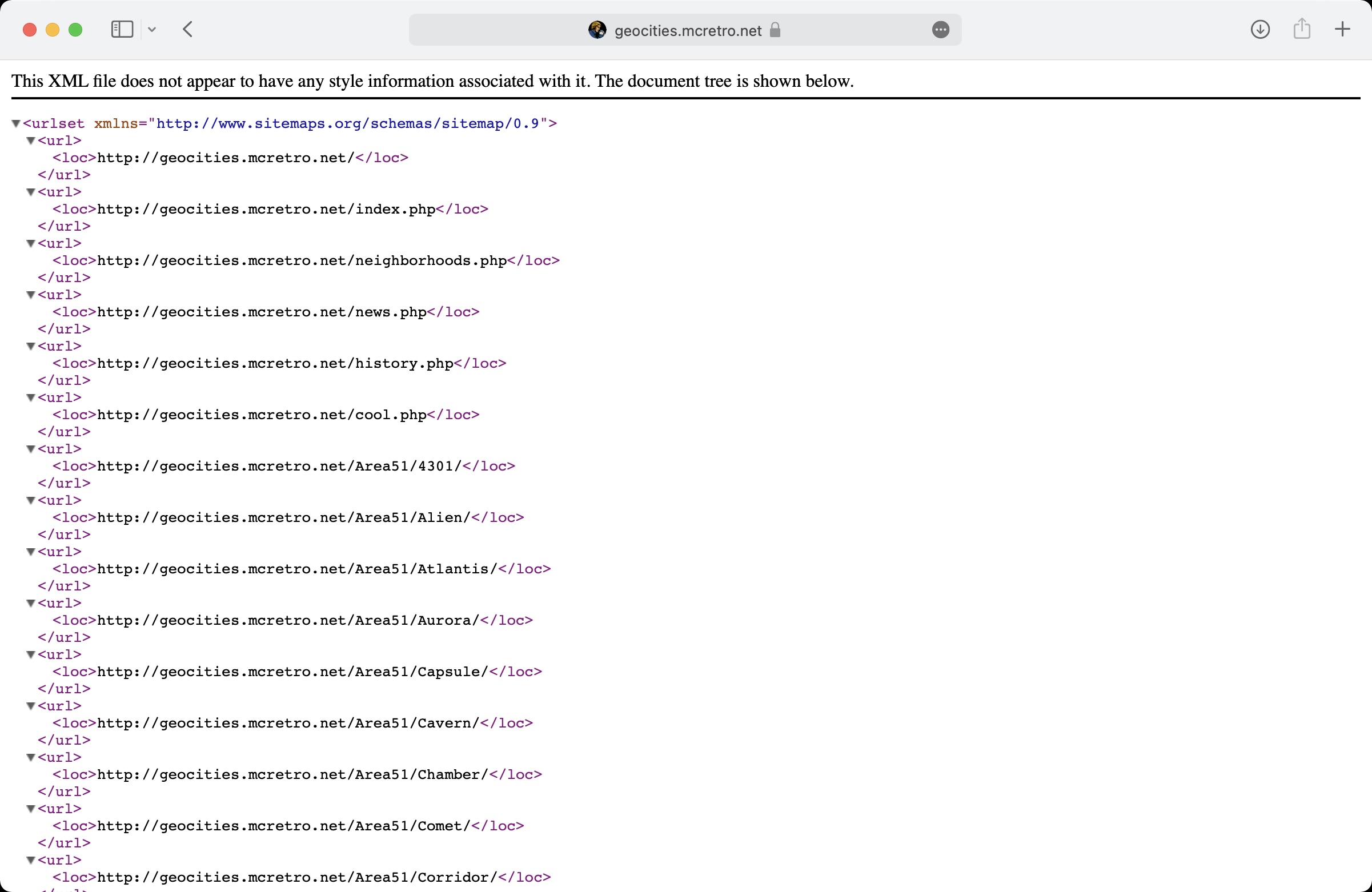
We now have a sitemap.
Next, how to best implement the teleport/jump feature to use the sitemap.
Jump implemented.
The code comes from stackoverflow.com. The jump code now runs a server-side script (in PHP) to randomly select a website from the sitemap.xml file. If it weren’t server-side you’d know because the file is 1.8MB. Downloading that over dialup is going to be one slow page load.
You can try it here to beam to a random GeoCities website. We still have only Area51 and CapeCanaveral active. Hope you like X-Files fanfic…
Now we have the code that helps us jump to random sites that is pulled from our sitemap.xml. So where to next? Finding a way to keep a “Home”, “Jump”, and “Report” text or buttons on the majority of sites visited. Initial tests were somewhat successful…
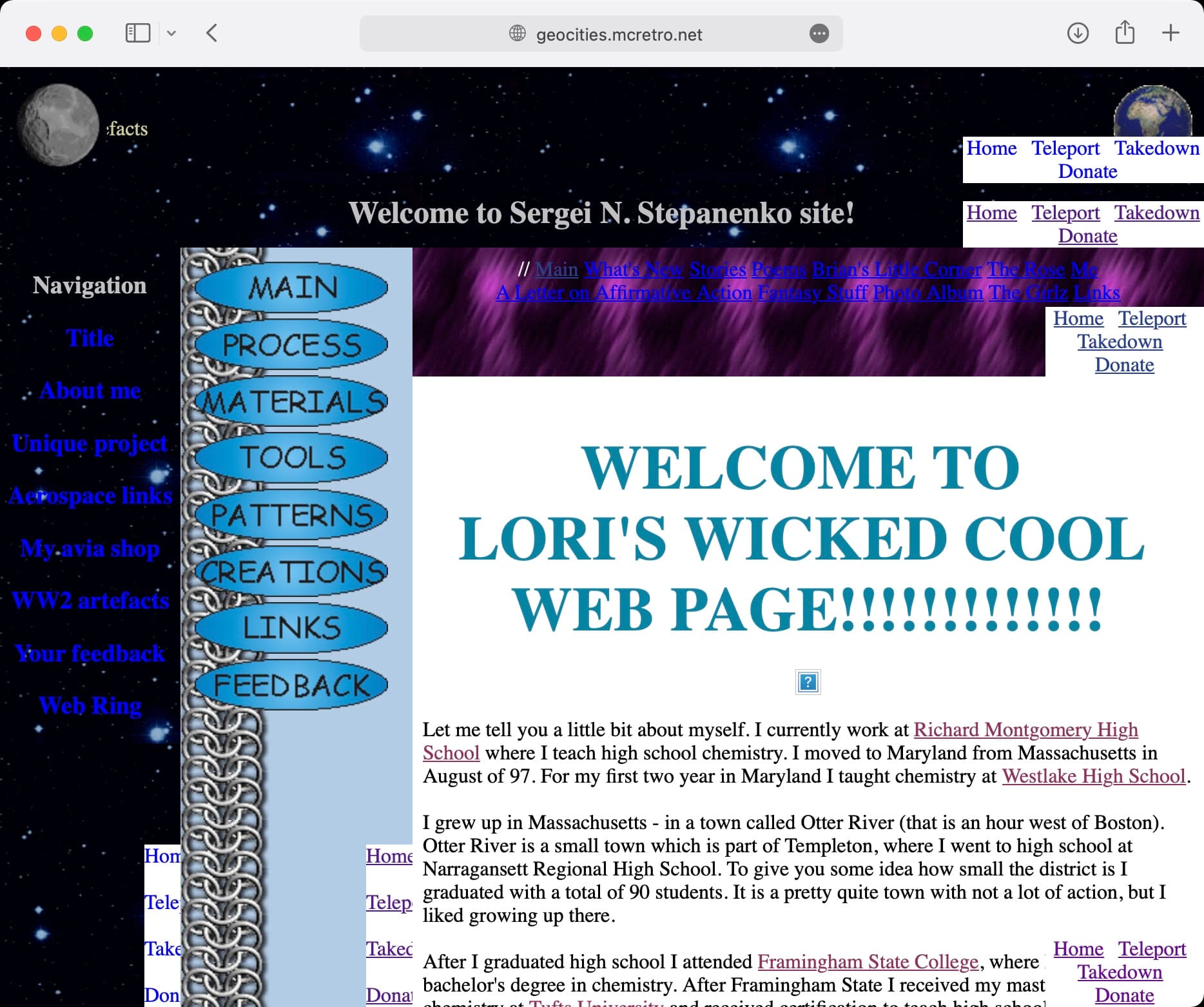
I rediscovered TARGET=“_top” after having my test links as same window. TARGET=“_top” makes links open in the topmost frame, i.e. the full browser tab and window. Lesson learnt.
The current iteration of nav buttons embed into the page by Apache’s mod_substitute. We replace the </BODY> tag of the website server-side (not on the client visiting). No solution was perfect, so I went with the one that causes the least damage.
</HEAD>- Could cause the body tag to start prematurely, resulting in malformed content and it breaks frames.<BODY>- Most pages have this contain most of their formatting. Injecting code into here results in a mess, often stripping formatting.</BODY>- This only rarely causes issues.
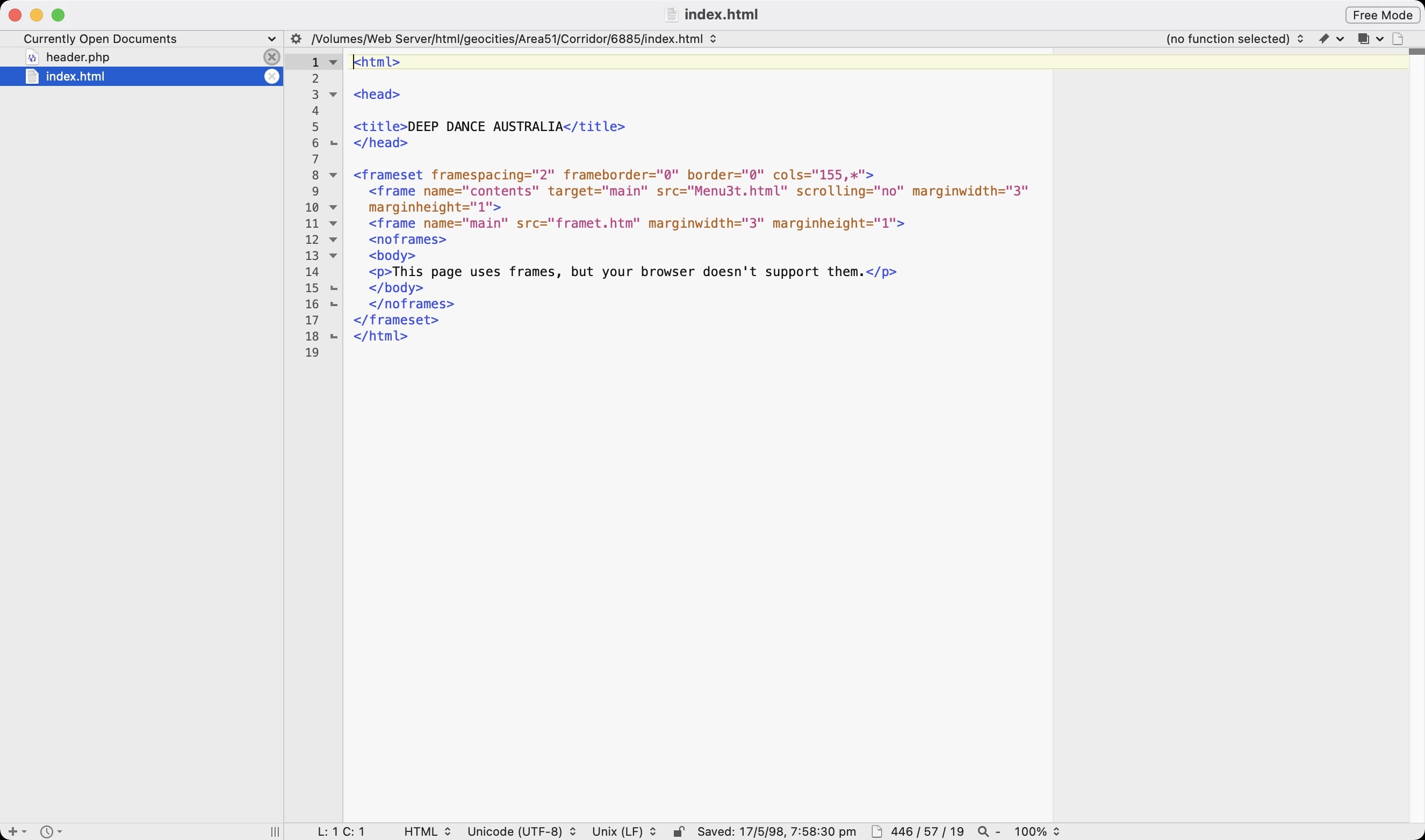
The above shows issues when using BODY as a place to inject when FRAMESET is present. Substituting the </BODY> results in no nav buttons showing because FRAMESET is used in place of BODY tags. While I could inject code into FRAMESET as well, I think it would cause more issues depending on if the FRAMESET contained body tags such as the above sample site code.
I did tinker with having JavaScript overwriting some of the code to inject a nav bar. However, it was not working on the targeted older browsers. The reason? The script always landed outside the closing BODY tag meaning it wouldn’t render on the page.
Loaded the VirtualHost config:
sudo nano /etc/apache2/sites-available/geocities.conf
and inserted the following:
# Insert Home, Jump and Report Icons - Works without breaking too much, doesn't show on sites without a closing body tag </BODY>.
Substitute 's|</body>|<BR><p align="right"><A HREF="/" target="_top"><IMG SRC="/pictures/home.gif" ALT="Home"></A> <A HREF="/jump" target="_top"><IMG SRC="/pictures/jump.gif" ALT="Jump!"></A> <A HREF="http://mcretro.net/report" target="_blank"><IMG SRC="/pictures/report.gif" ALT="Report"</A></p></body>|i'
We can now jump from most pages - including directory listings (i.e. pages without an index).
In other news, I’ve mostly finished the neighborhood listing. This means if I copy all the files across they will now load up well enough. I’m still working on directory structure though. Images for sites seem to come from the following pages:
- Yahoo | Mail, Weather, Search, Politics, News, Finance, Sports & Videos
- http://pic.geocities.com
- http://us.yimg.com
- http://us.geo1.yimg.com/pic.geocities.com
- http://visit.geocities.yahoo.com
- http://visit.geocities.com
- And other international sites.
Pure chaos.
I’m looking into aliasing some of the data directories for YahooIDs to prevent them flooding the root folder with random usernames. Still trying to work out the best way to achieve that though.
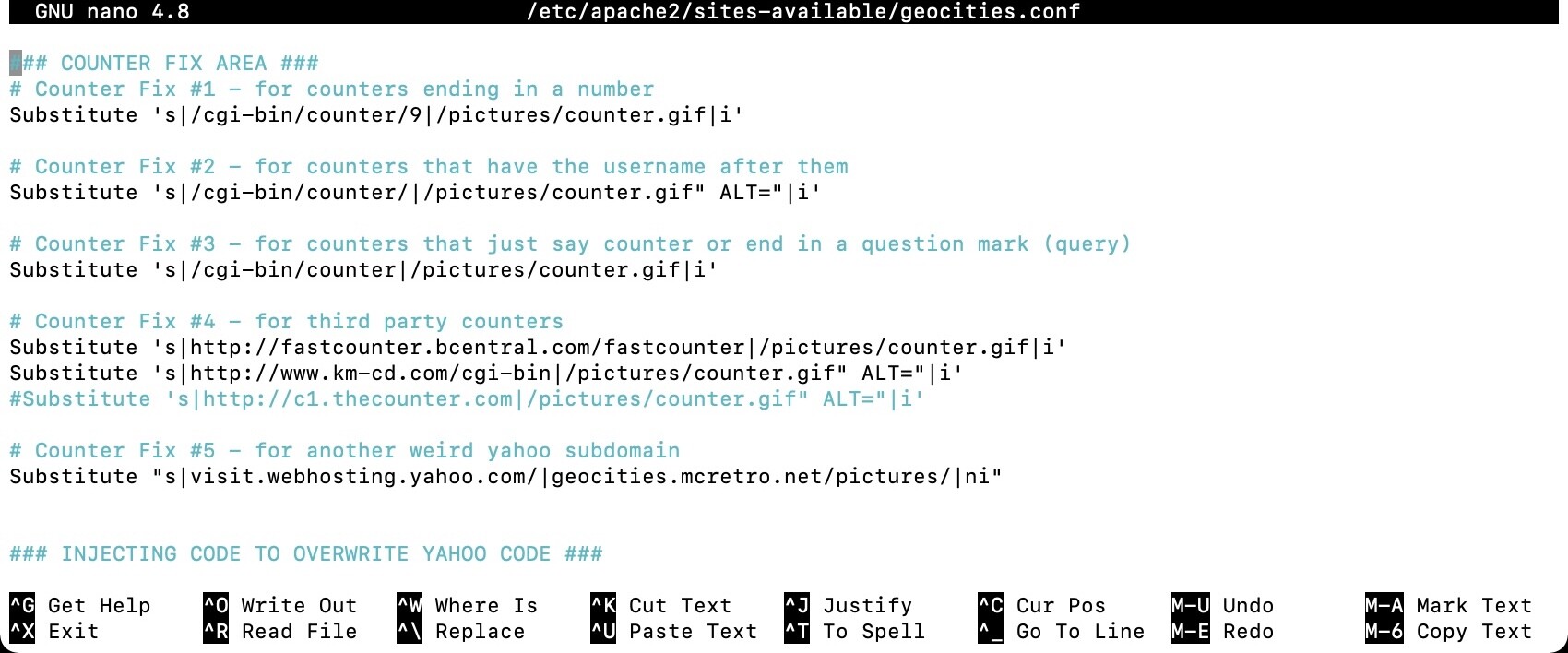
I’ve tidied up the counters and the root substitutes, I noticed a lot more backgrounds work now. Once I merge all the root pictures/images together, we’ll have much better looking sites. Well, perhaps better isn’t quite be the right word. ![]()
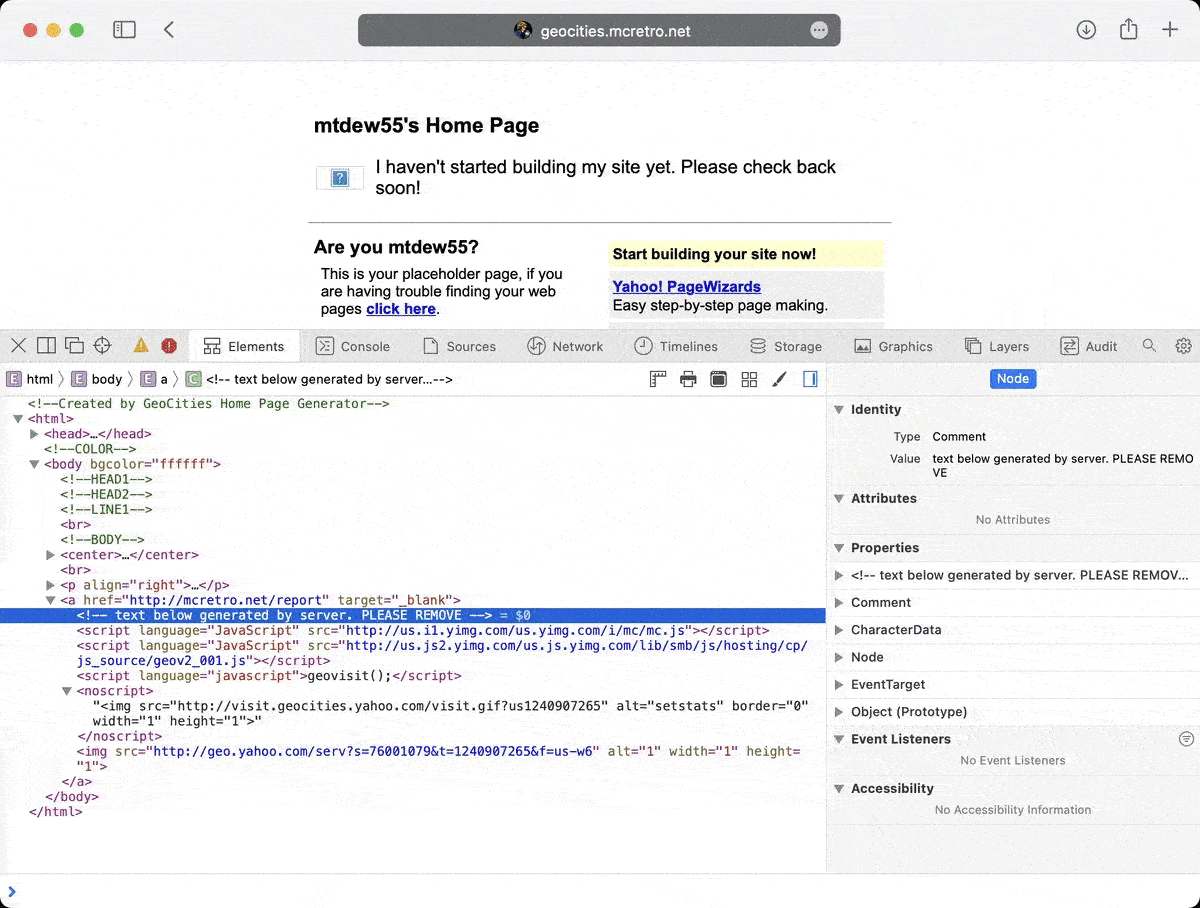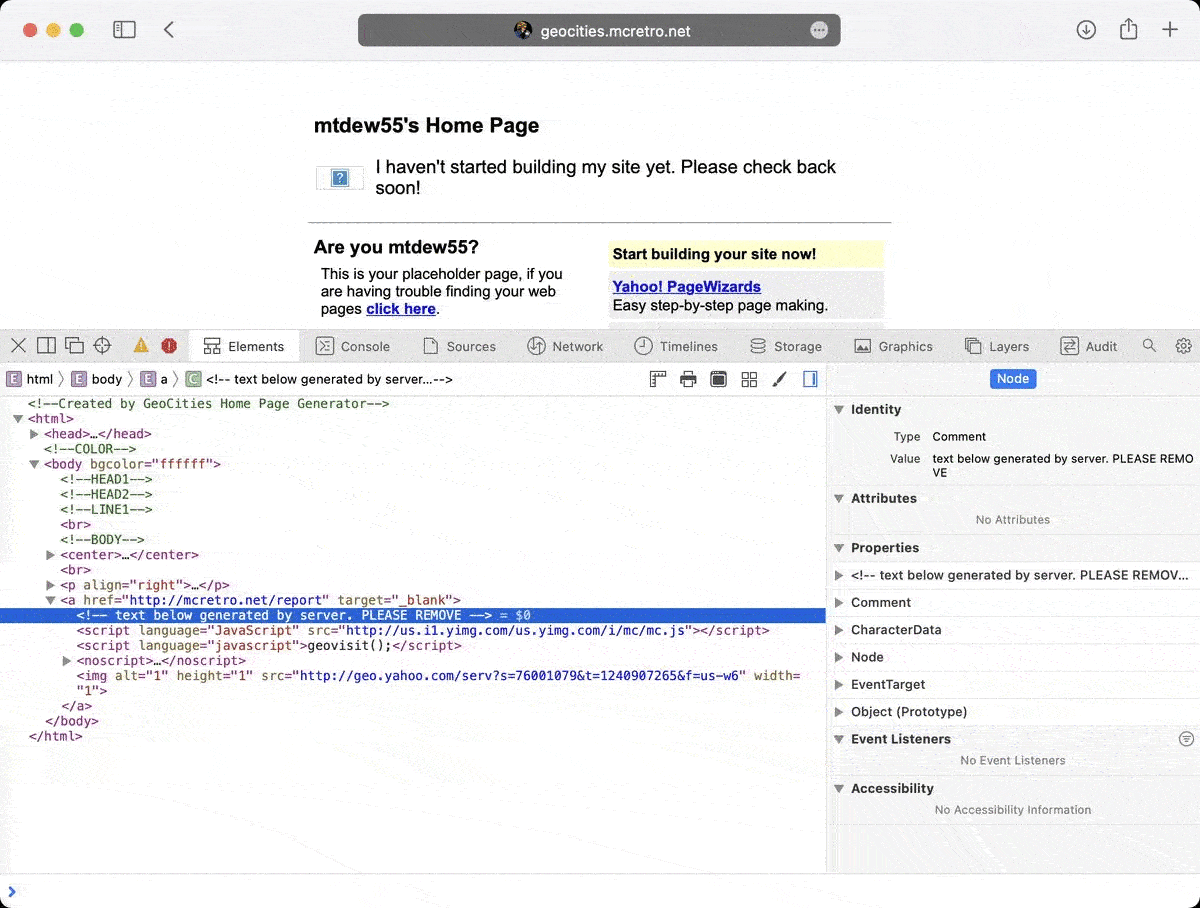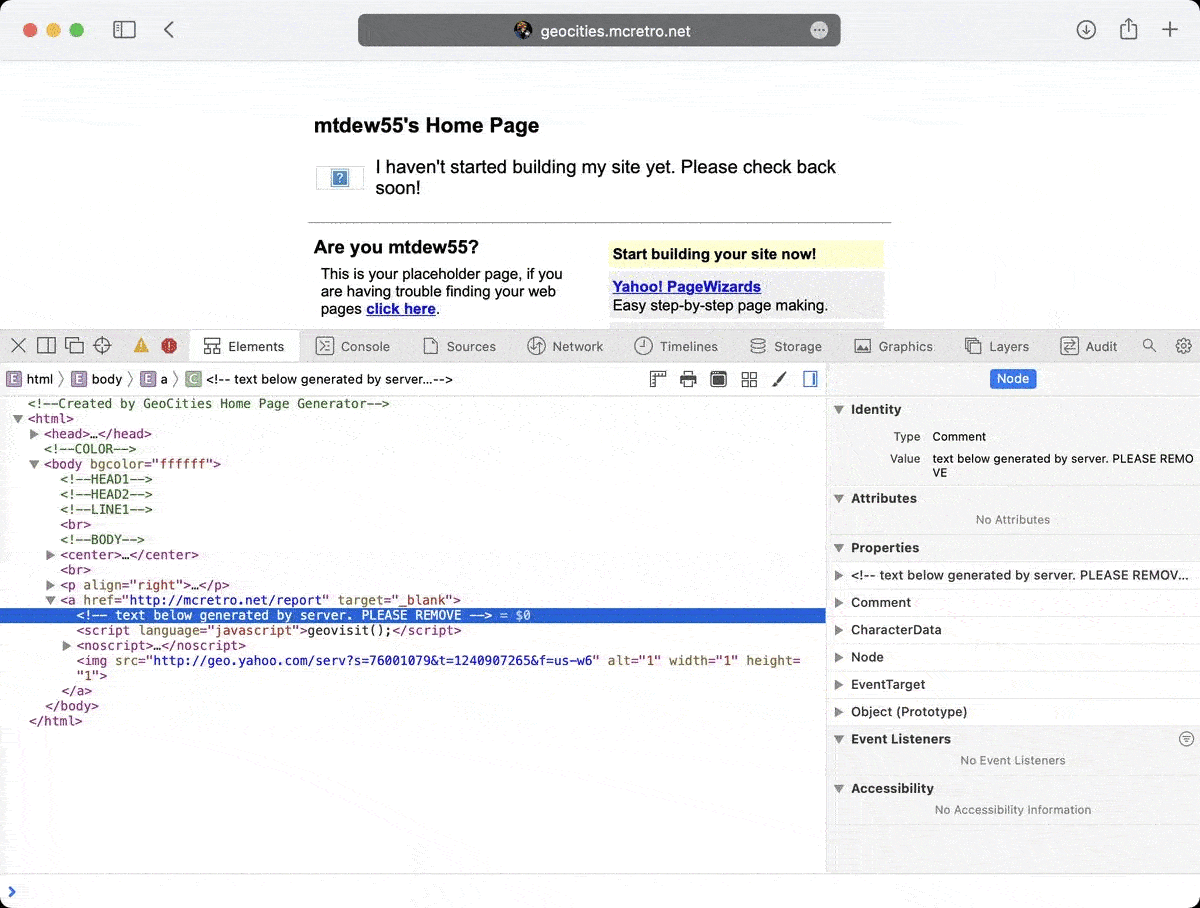
For now I have removed some of the JavaScript hiding on almost all pages. I couldn’t work out how to remove the geovisit(); code though. Two out of three ain’t bad.
Not much more to report except for some insight into those new Matrix sequels. I’ll keep working away on working out structure on the backend. I need to verify the structure of the neighborhoods against other sources such as Blade’s Place, OoCities.com and Wayback Machine.
Then I’ll need to poke around the YahooIDs, Neighborhoods and pictures spanning three periods: GeoCities, the GeoCities/Yahoo transition and Yahoo. Working these ones out will help determine the best way to mount the external media.
1 Like
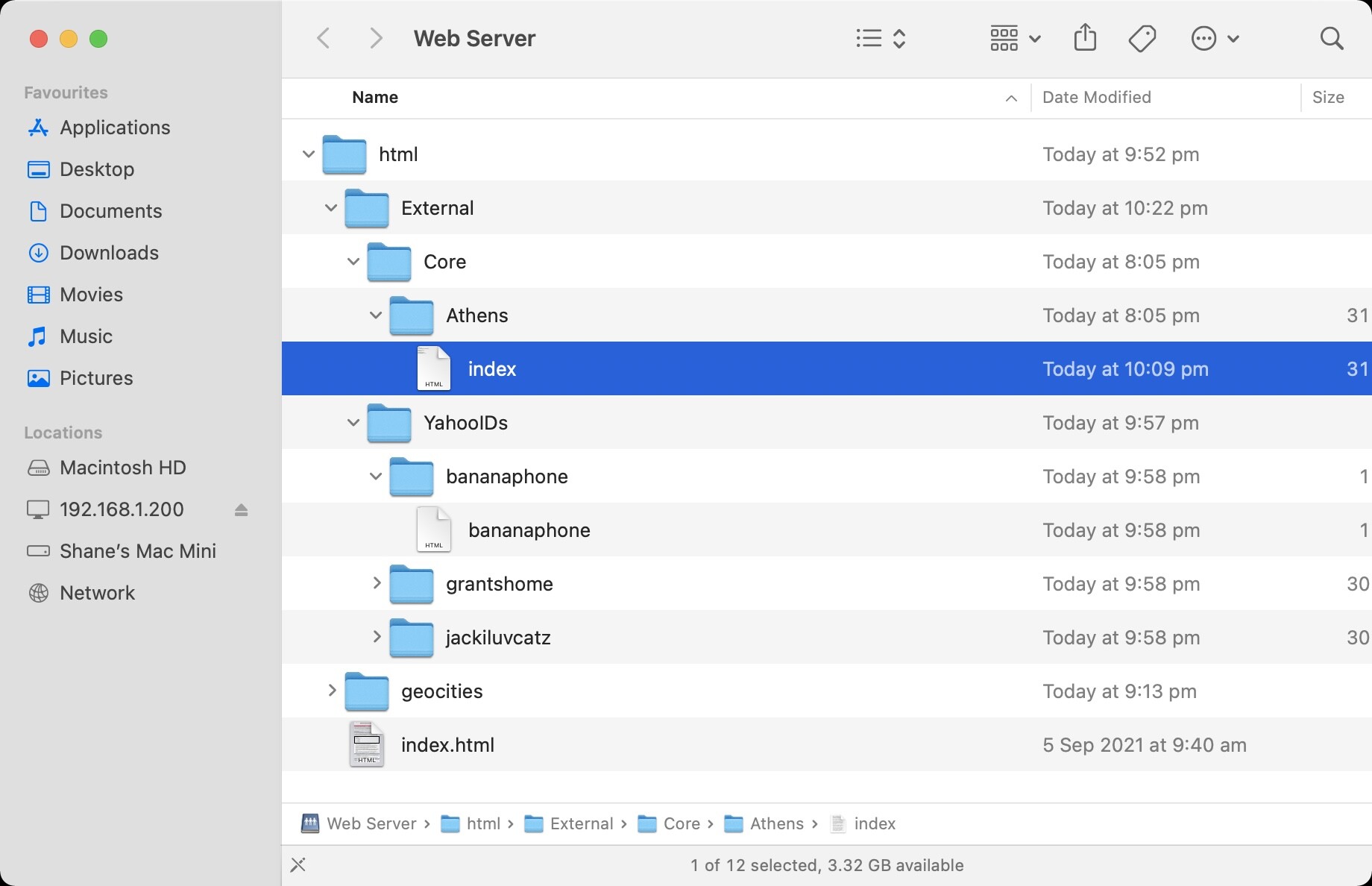
Here’s the file structure. I want to have External be an external USB SSD to hold all the data from Core (Neighborhoods) and YahooIDs (YahooIDs). Athens is an example of a neighborhood. The YahooIDs, bananaphone, grantshome and jackiluvcatz are examples of usernames. The geocities subfolder contains the HTML I have written up in the past month or so.
There’s a lot of cross over between YahooIDs and neighborhoods. It looks like if you had a page at Yahoo | Mail, Weather, Search, Politics, News, Finance, Sports & Videos you would have also had Yahoo | Mail, Weather, Search, Politics, News, Finance, Sports & Videos as a symlink. The page builders that Yahoo (and maybe GeoCities) used seem to have willy nilly used the YahooID over the neighborhood location in referencing images, and other files in your website.
So really I needed two separate locations to meet (parallel and overlapping data) under the root folder where I already had data.
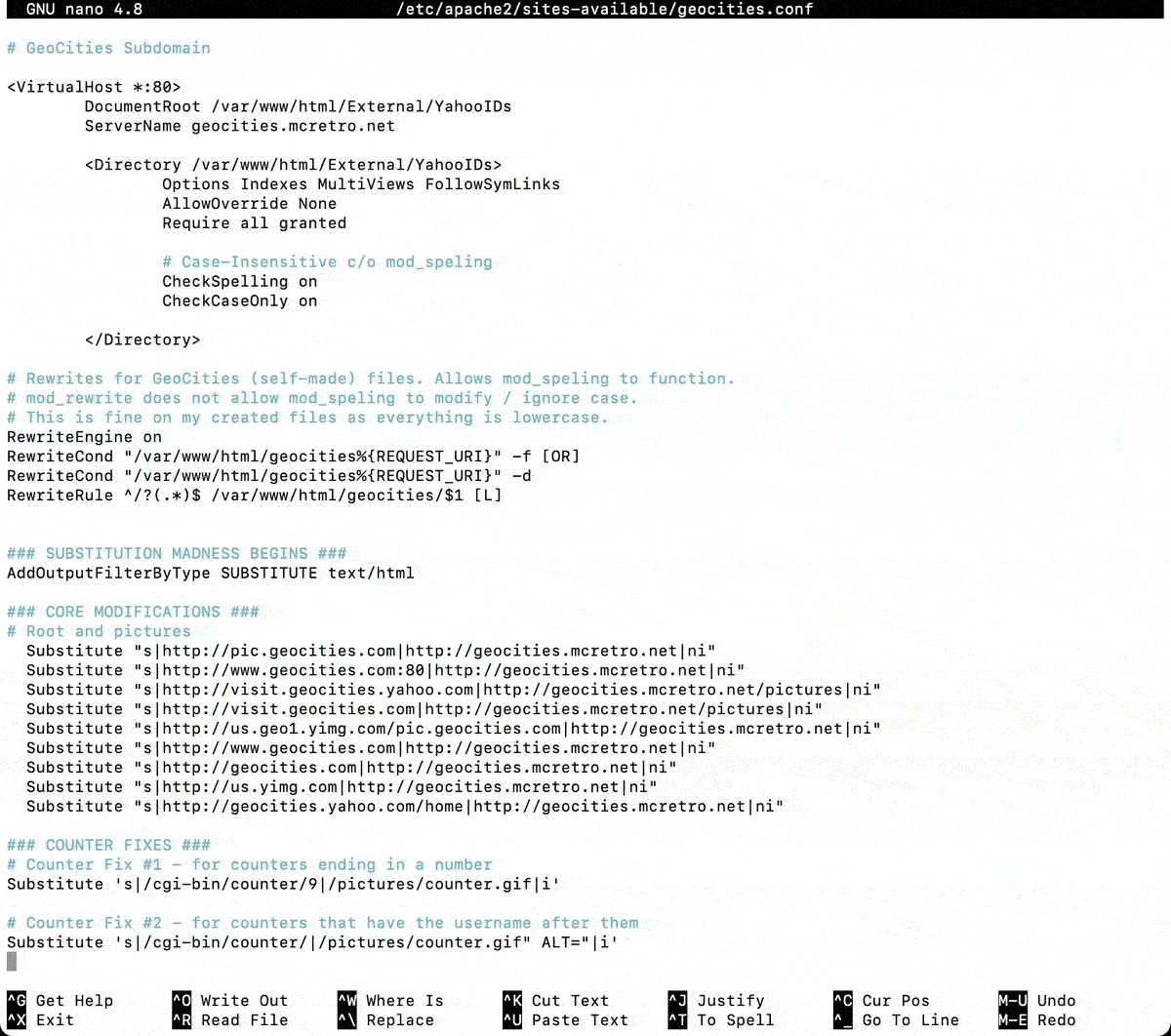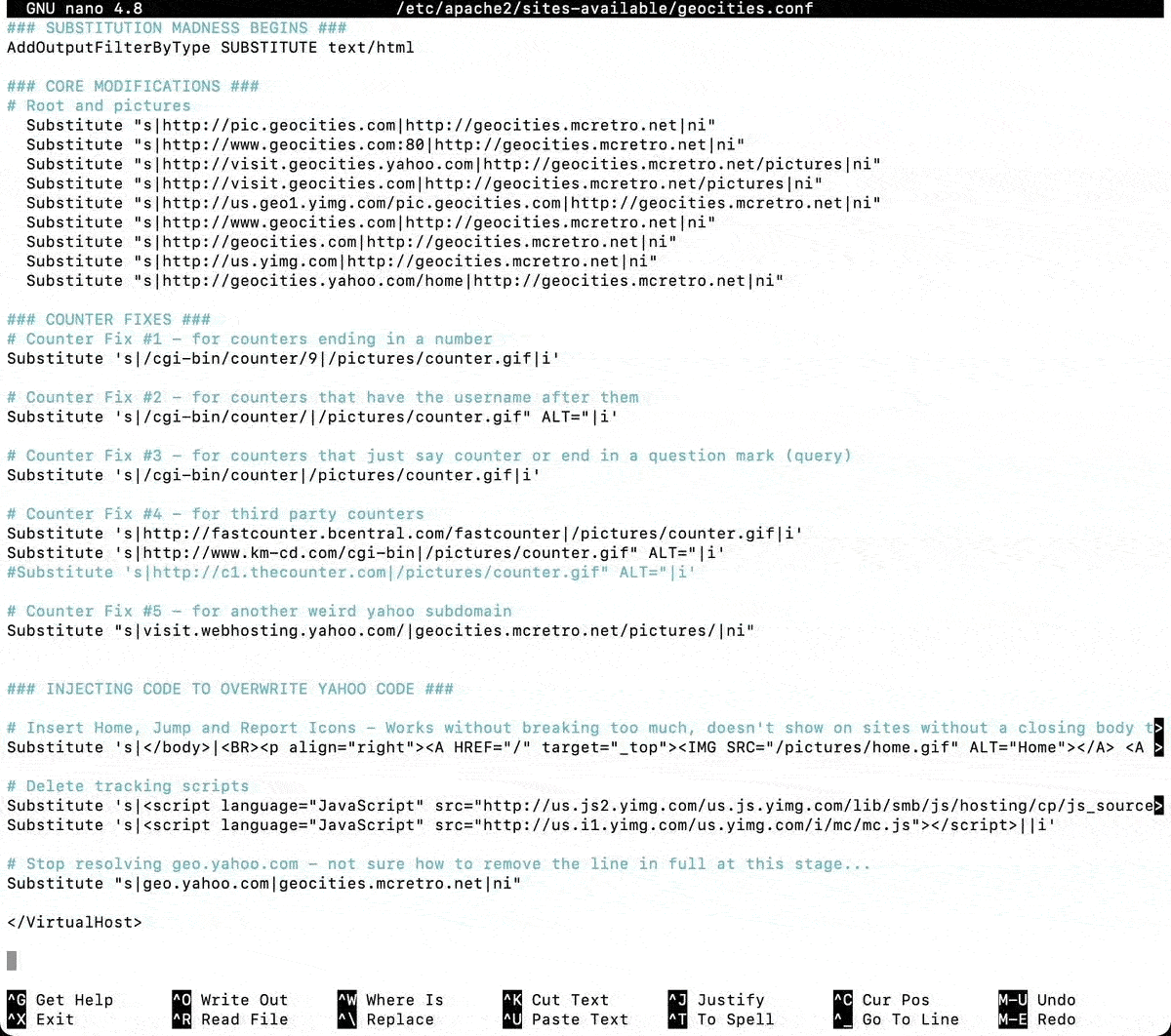
I attempted to use mod_alias only to find it kind of worked, but not really. Then I came across this incredible idea of having two DocumentRoots. My VirtualHost configuration became this:
DocumentRoot /var/www/html/geocities
<Directory /var/www/html/geocities>
Options Indexes MultiViews FollowSymLinks
AllowOverride None
Require all granted
</Directory>
RewriteCond "/var/www/html/External/YahooIDs%{REQUEST_URI}" -f [OR]
RewriteCond "/var/www/html/External/YahooIDs%{REQUEST_URI}" -d
RewriteRule ^/?(.*)$ /var/www/html/External/YahooIDs/$1 [L]
RewriteCond "/var/www/html/External/Core%{REQUEST_URI}" -f [OR]
RewriteCond "/var/www/html/External/Core%{REQUEST_URI}" -d
RewriteRule ^/?(.*)$ /var/www/html/External/Core/$1 [L]
It worked! Almost perfectly. I found that we would lose the ability to have “athens” be corrected to “Athens” once passed through the rewrite rule. It turns out mod_speling and mod_rewrite are incompatible.
“mod_speling and mod_rewrite apply their rules during the same phase. If rewrite touches a URL it generally won’t pass the url on to mod_speling.”
One document root (my HTML) and two rewrite rules (Neighborhoods and YahooIDs) were so close to working. Every article I read told me it wasn’t possible, everyone else gave up or threads went dead. I did learn that Microsoft IIS has this issue often when migrating to a Linux host with Apache. Great.
Symlinks are back on the menu. I could use:
sudo ln -s Athens athens
This would allow me to have athens corrected to Athens. But what about SoHo, Soho and soho. Let alone the case sensitivity on YahooIDs… Plus there’s a bunch of unmerged case differences. I’ll merge them one day, maybe. mod_speling might negate the need to do that.
There’s too many variations of each YahooID, e.g. bananaphone vs BANANAPHONE and every iteration inbetween to create symlinks for. If mod_speling is broken, then case sensitivity is broken stopping people visiting the second address listed:
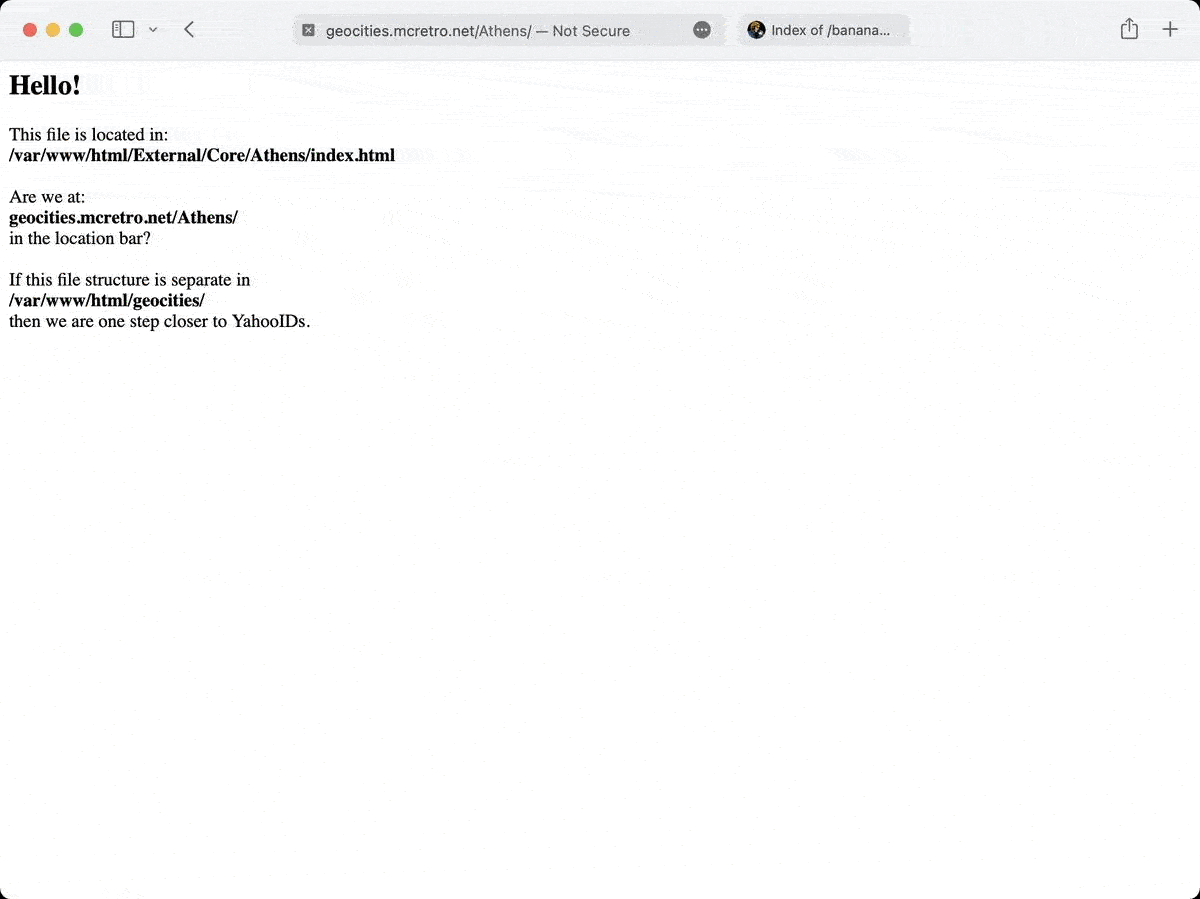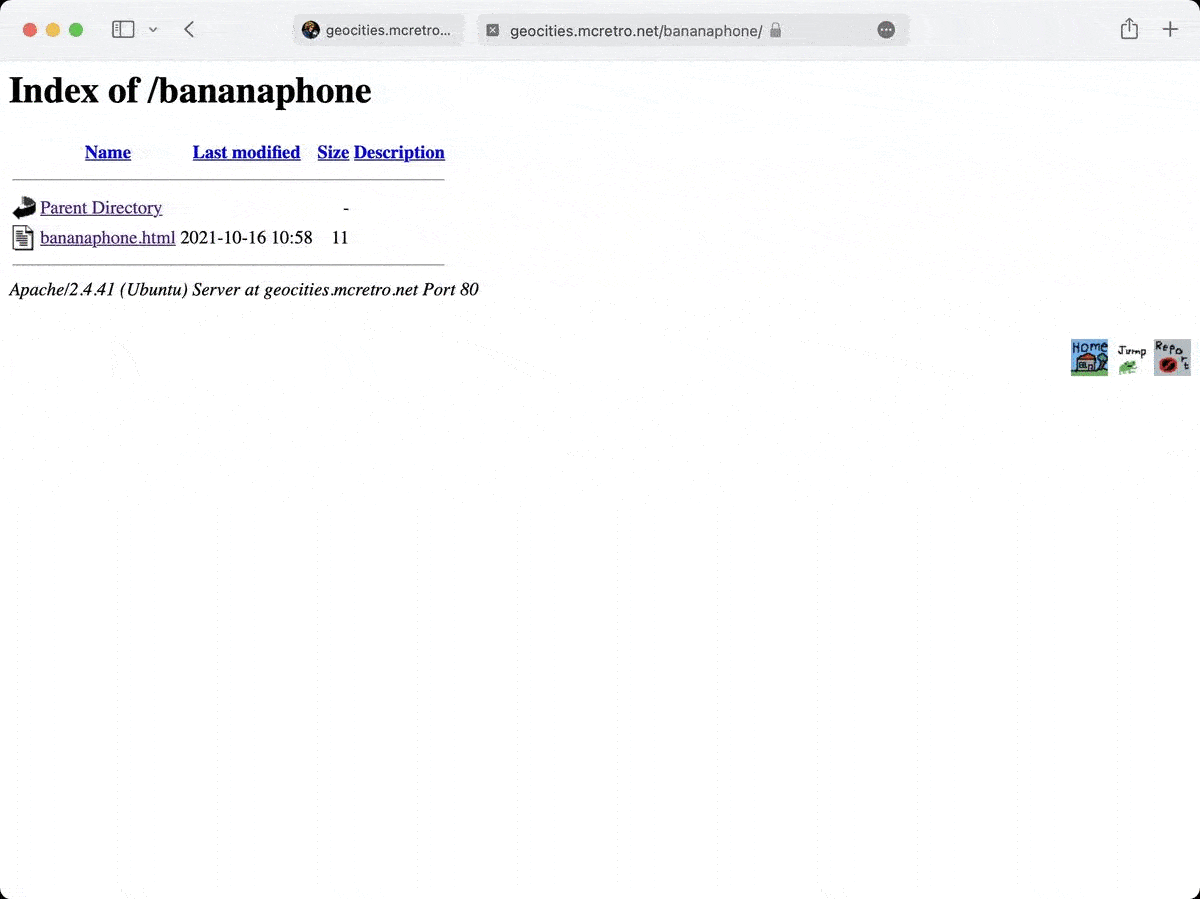
It was so close to working. Just the lowercase variations were broken. I even dabbled in rewriting all files to lowercase through mod_rewrite. Nope, that didn’t work at all. Hmmm. Then it hit me. Like a bus. Reverse it.

I know that my created HTML is all lowercase and doesn’t require mod_speling. That means that the “geocities” folder can be ran through mod_rewrite with no consequences of mod_speling being disabled. Great!
# Rewrites for GeoCities (self-made) files. Allows mod_speling to function.
# mod_rewrite does not allow mod_speling to modify / ignore case.
# This is fine on my created files as everything is lowercase.
RewriteEngine on
RewriteCond "/var/www/html/geocities%{REQUEST_URI}" -f [OR]
RewriteCond "/var/www/html/geocities%{REQUEST_URI}" -d
RewriteRule ^/?(.*)$ /var/www/html/geocities/$1 [L]
With “geocities” being taken care of we move on to the contents of the “External” folders. We need their contents to show at:
Simple? Not really. No wonder I got stuck on this so long! The larger of the two folders is going to be YahooIDs. There’s a finite amount of neighborhoods, so core will have less items. Sounds like I need to symlink Core folders into YahooIDs so they both display at root in http://geocities.mcretro.net/ - symlink activate!
sudo ln -s /var/www/html/External/Core/* /var/www/html/External/YahooIDs
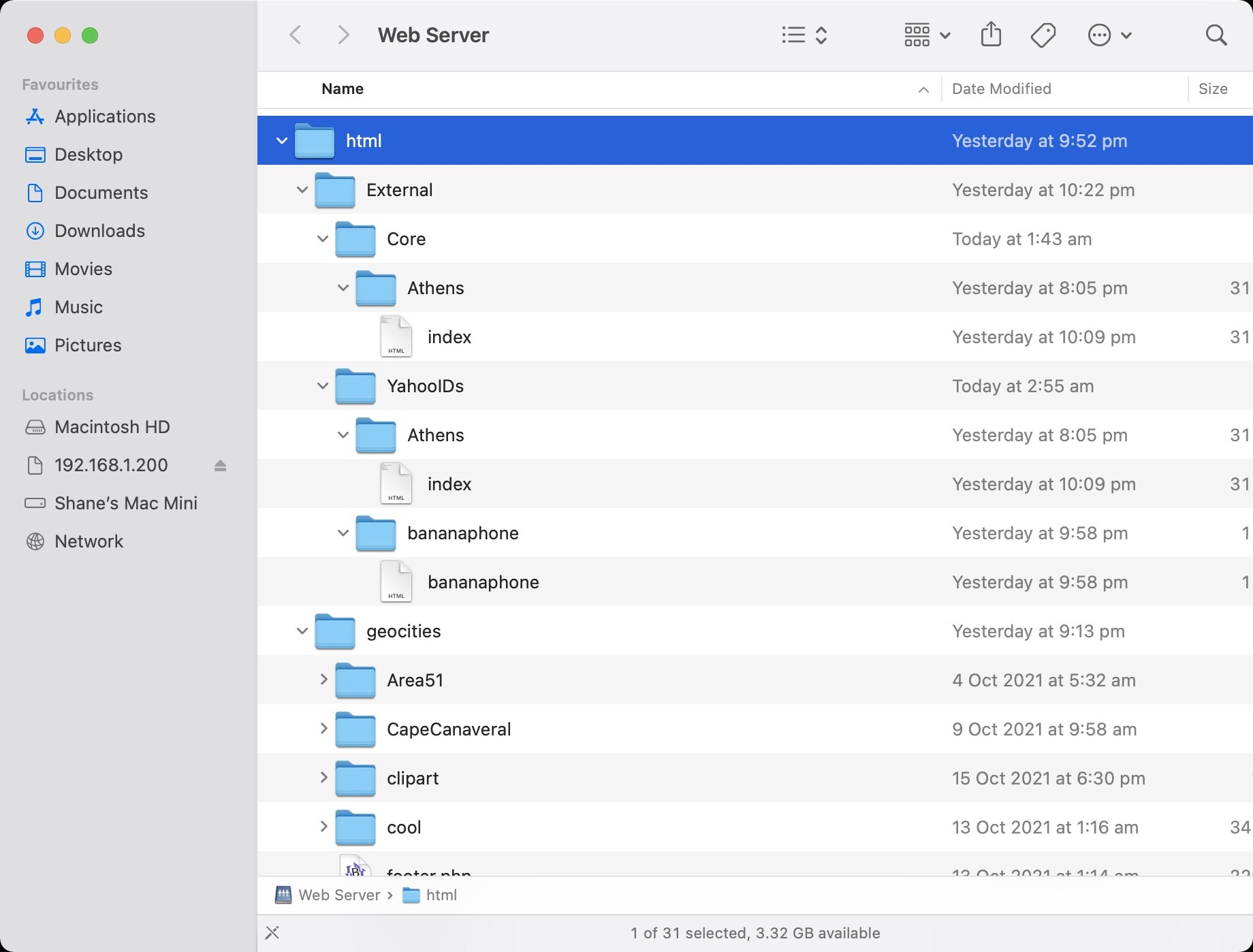
Now we have an Athens folder inside YahooIDs. Excellent. YahooIDs is now our DocumentRoot. Core (neighborhoods) is symlinked into YahooIDs. My GeoCities HTML landing page is rewritten into / alongside the above two. Three folders feeding into one. Incredible.
I’m hoping you’re starting to see why the GeoCities Archive is such a mess. The backend would have been chaos.
These all redirect correctly:
- https://geocities.mcretro.net/BANANAphone
- https://geocities.mcretro.net/bananaPHONE
- https://geocities.mcretro.net/athENS
- https://geocities.mcretro.net/ATHens
Also important to check the older links are still working and have mod_speling active:
On that note, we’ll need to move any neighborhoods from /geocities/* to /External/Core/*.
It seems that the /geocities/Area51/ rewrite rule has priority over /External/Core/Area51/ - interesting. Throw some case in there and it all redirects correctly though. This might not mean anything at this stage since I need to reshuffle the files around and fix permissions.
Above is the VirtualHost configuration to date. I better get around to moving everything across into final directories for further testing. ![]()
Update: Copied all the neighborhoods across (core) and a few usernames (yahooids) - it looks like it might be working. I’ll rebuild the sitemap.xml file tonight. It should wind up being pretty big. Then jump should teleport across any page that is available! ![]()
1 Like
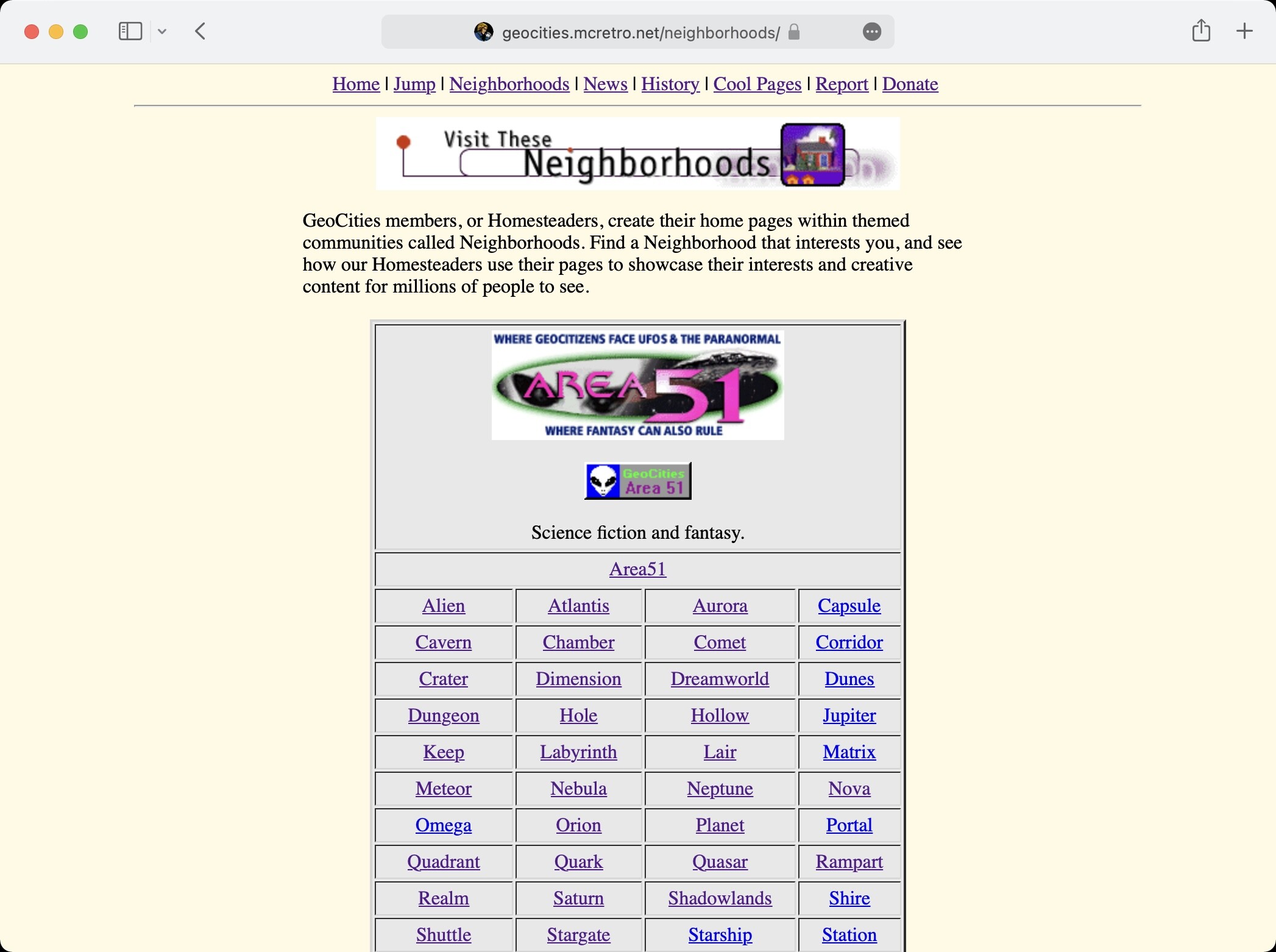
Jump is working, however the server does not like having to parse a file that is 15MB everytime the link is clicked. There’s over 280,000 links indexed. Yikes! That’s before I add 100,000+ user folders… That’s a lot of files.
What I can possibly do to speed it up a little is to split the sitemap into multiple files. Then the jump PHP script could call on one of the sitemaps at random, and pick a random URL inside the sitemap called upon. Of course you could just pick a suburb from the neighhborhood section and explore that way too.
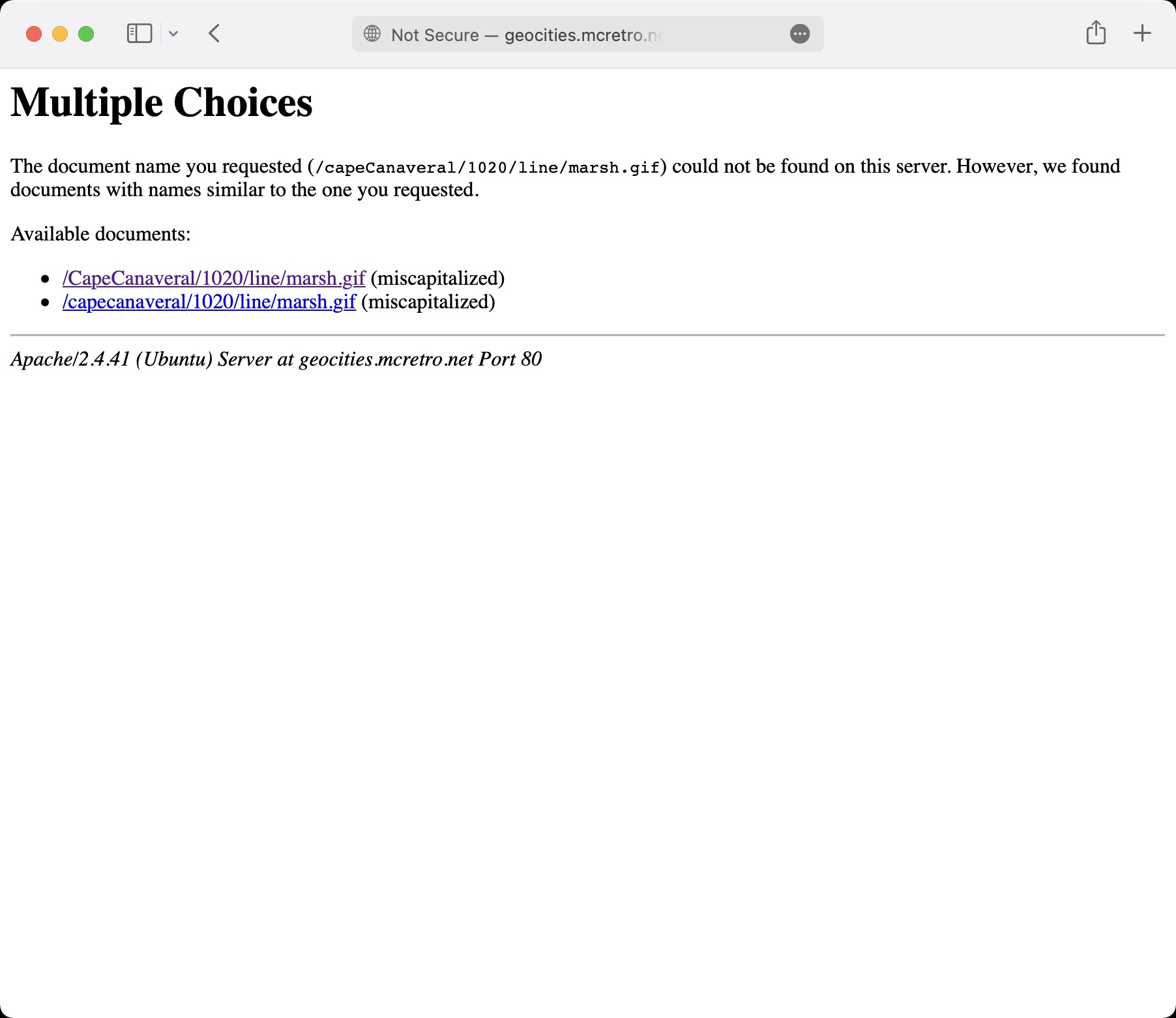
Now that I’ve got everything redirecting to the root where it should be, I’m coming across some issues. This is one of them. This is mod_speling in action, trying to work out what address I was supposed to go to. I gave it capeCanaveral (invalid, non-existent) instead of CapeCanaveral (valid, exists) or capecanaveral (invalid, non-existent).
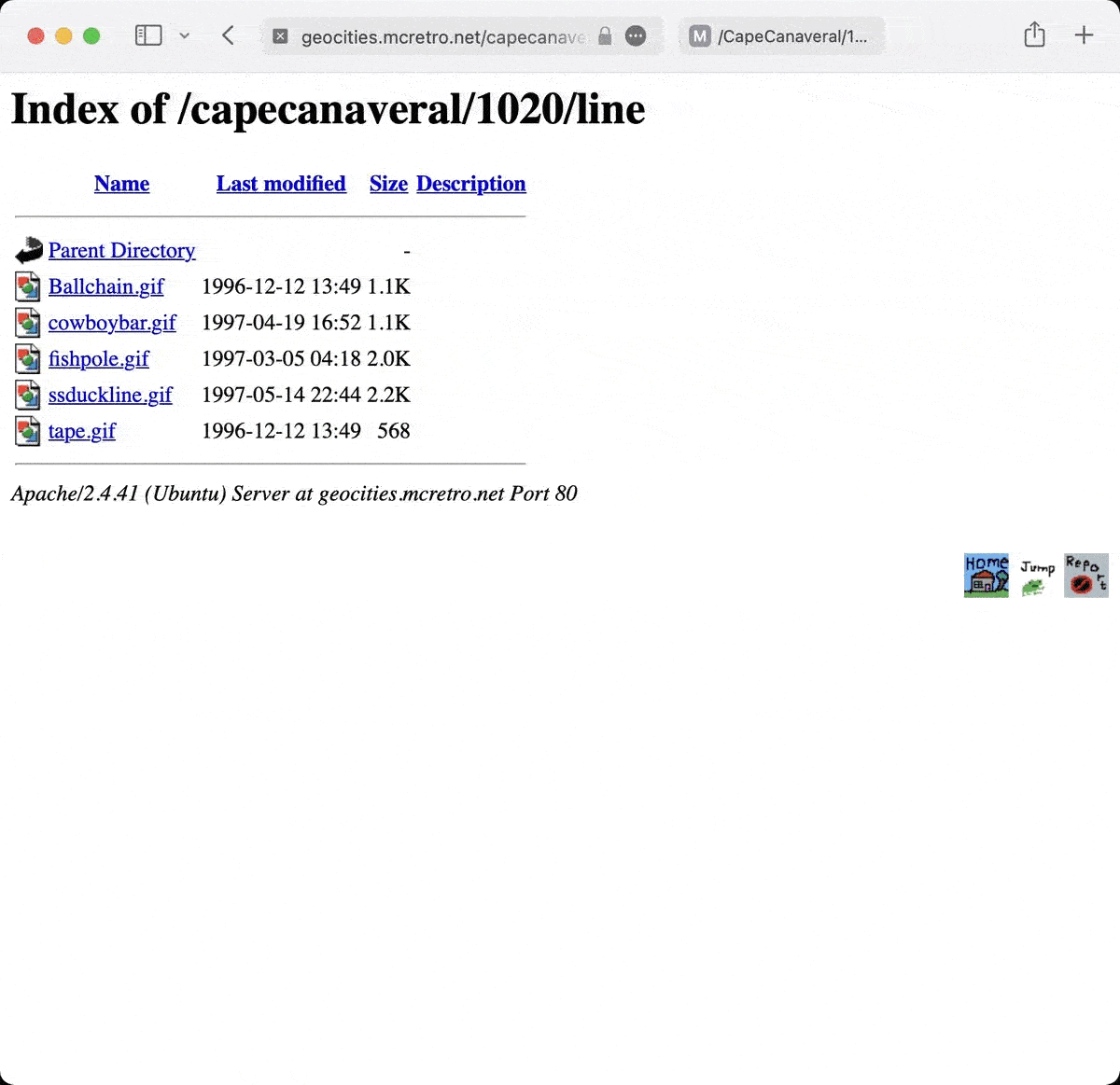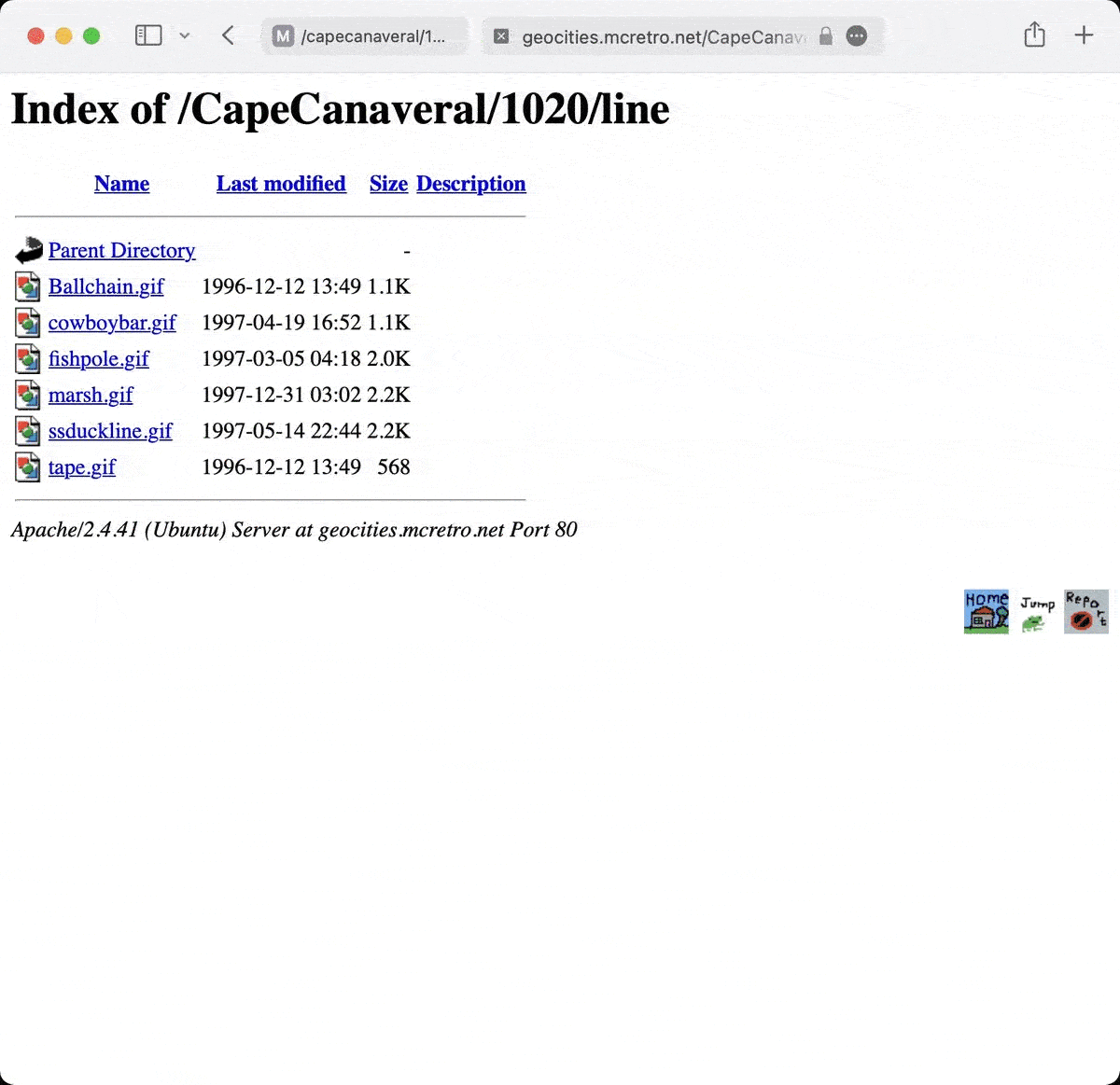
As you can see from the above gif, marsh.gif is present in only one and it mod_speling failed to splice the two directories together. This might be a by-product of the way the DocumentRoot and mod_rewrite was configured earlier… I guess it doesn’t matter too much for now. I will need to find a way to merge the lower case and upper case variations on directory names eventually.
Next steps will be capturing more core (neighborhoods) directories to merge from the YahooID folders. The data dump included a few extra sources apart from the main files, I’ll need to get these into the mix.
The next step after that will be sorting out the structure of the root pictures and images folders. These are pretty important as some people hot-linked directly to the root source files which aren’t all present yet.
I won’t be able to work on this too much until the weekend again, but it does give some food for thought until then. ![]()
1 Like
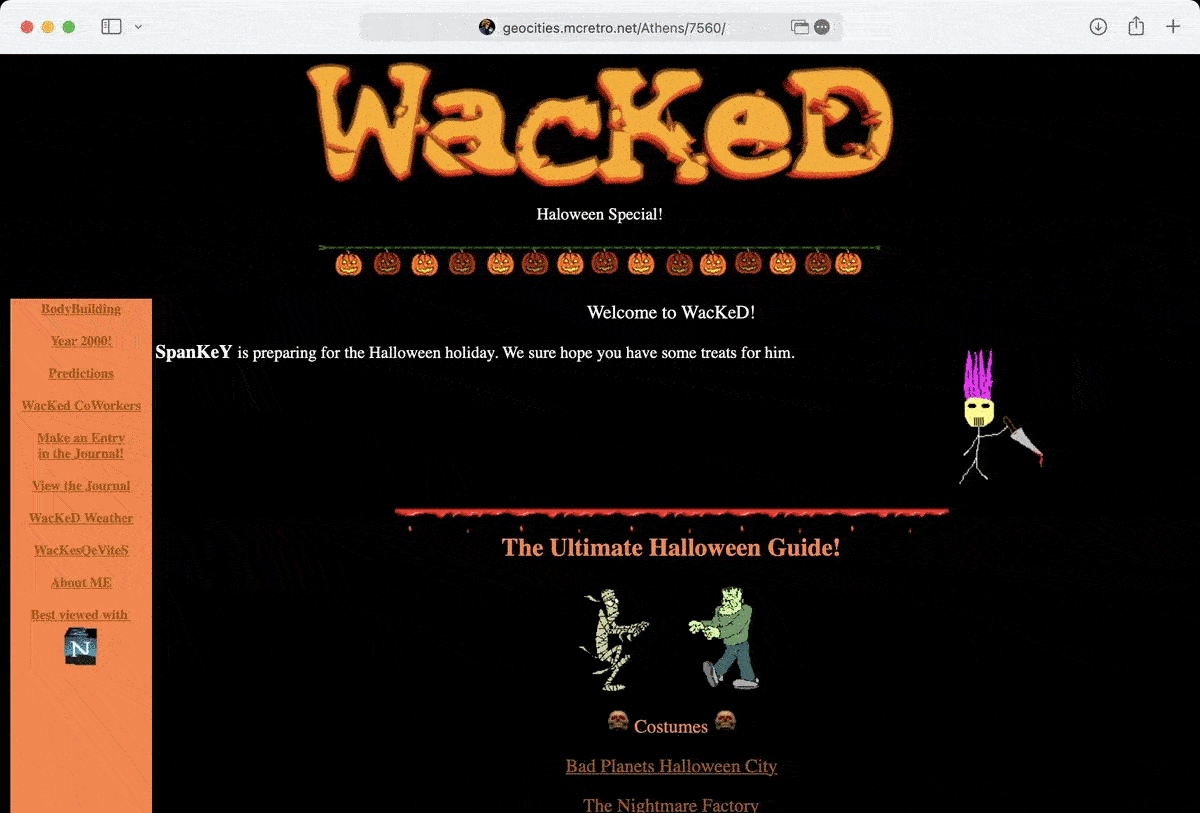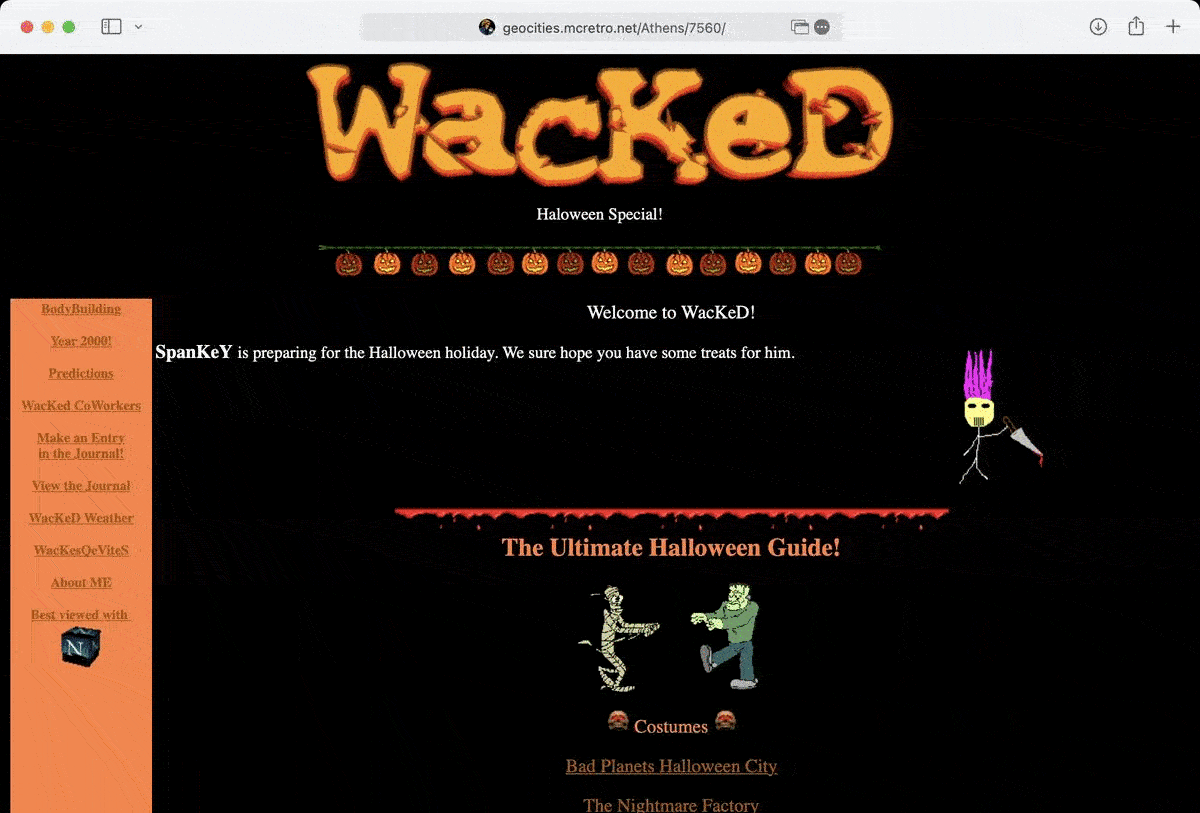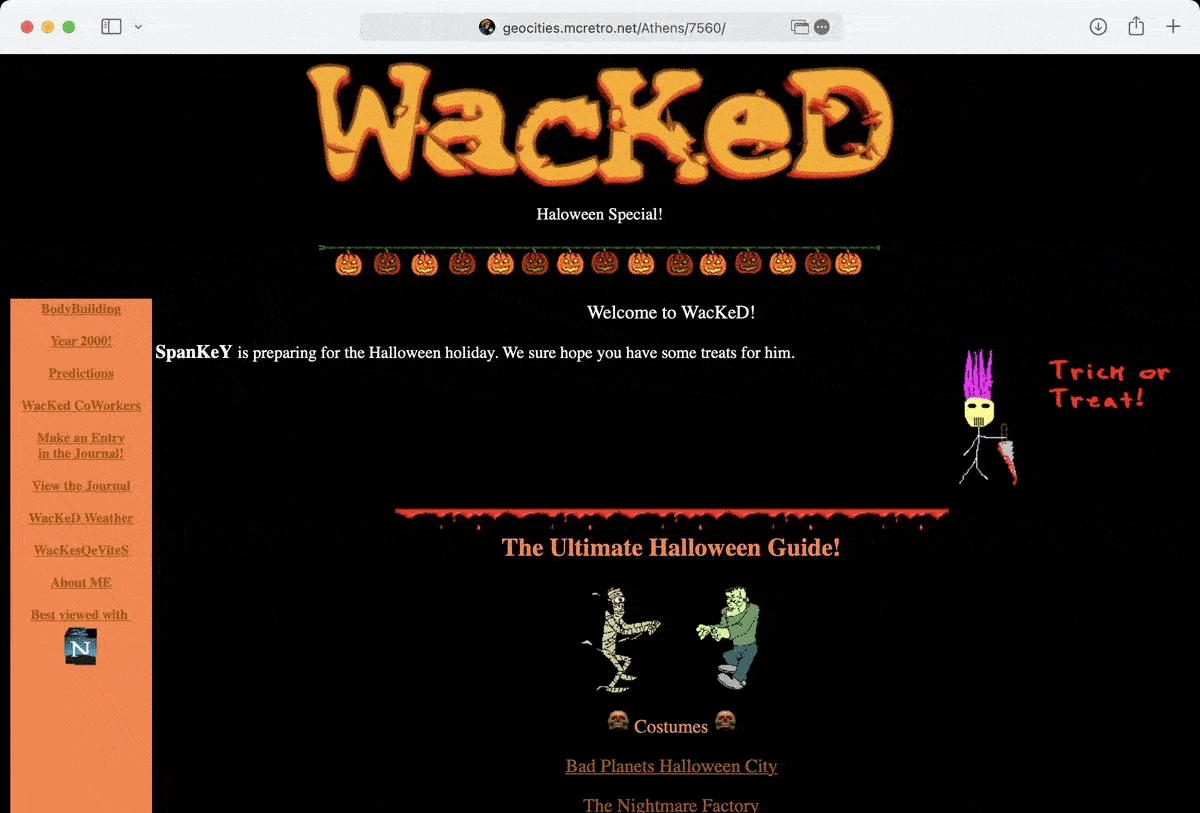
I know I said I wouldn’t do too much during the week but a few things did click together. In preparation for merging the neighborhood case differences with rsync (or Carbon Copy Cloner) we’ve made some big strides in the past week. Here’s the more exciting things:
- Found and removed all index.html files from directory listings.
- Removed 0 byte files, removed 0 byte folders (in that order).
- Started to clean up some of the redirection looped files and folders.
- Less than 1TB of data is present now.
- Symlinks were all deleted (again) - we need mod_speling to work properly.
- Sitemap has been created successfully and is now split into smaller chunks.
- The jump script now covers all neighborhoods and is a fair bit quicker.
All these will help with the merging of the various data sources together. It’s a bit like Minesweeper before you tinker with the settings to win faster.
The best order for cleaning up the file and directory structure (#2 and #5) was:
- Delete .DS_Store files (thanks Mac OS for creating them)
- Delete zero byte (empty) files
- Delete empty directories
- Delete symlinks
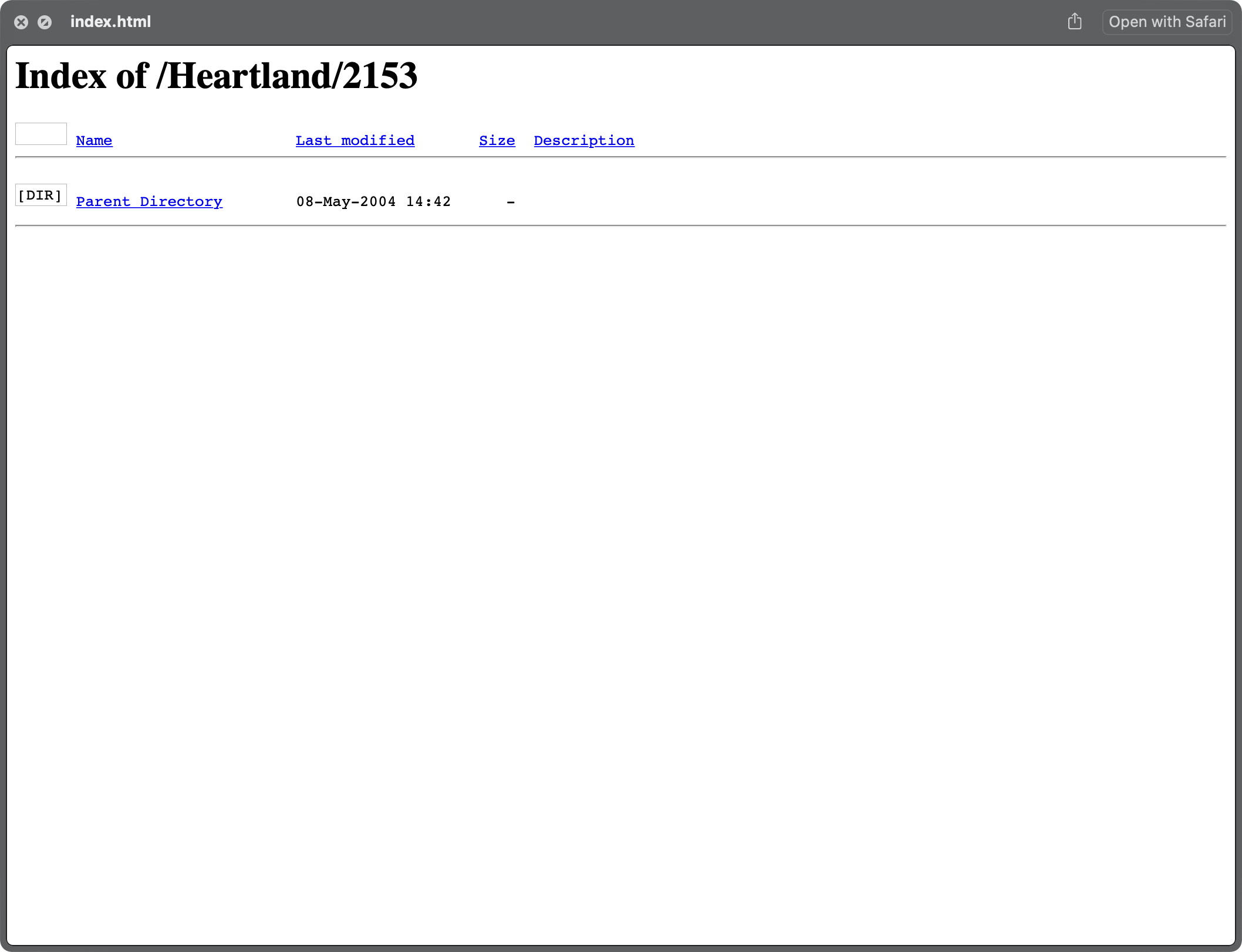
The creation of hidden .DS_Store files and directory listing index.html files (see #1) were blocking directories from being deleted as they were not empty. The above image was one of the offending index.html files that were likely autogenerated by Yahoo in order to reduce server load. The cost? They aren’t dynamic anymore. Deleting the index.html files was a tough feat.
As you can see above, these directory listing indexes are missing their icons and are quite boring. They don’t have a lot in common, but their source code shared some unique beginnings. This is one of the files:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<HTML>
<HEAD>
<TITLE>Index of /CapeCanaveral/6276/wreck</TITLE>
</HEAD>
<BODY>
<H1>Index of /CapeCanaveral/6276/wreck</H1>
From that we can steal the first part - four lines worth:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<HTML>
<HEAD>
<TITLE>Index of
And that’s pretty unique in itself as it narrows down HTML files that have “Index of” in their title. That’s only going to be indexes of directories. Perfect. Another bonus is the !DOCTYPE declaration. HTML3.2 Final (we’re up to HTML5 now). Very handy.
Next up I did some searching to find what command line tool(s) I could use. Enter grep via this post:
grep --include=\*.{htm,html} -rnw '/path/to/somewhere/' -e "pattern"
Grep seemed to work, but it was detecting my three lines as three searches and not stringing them together. So I’d have it return a positive for each line, I need all lines to be considered at the same time. Turns out grep wasn’t good enough. I needed pcregrep.
After playing around with switches and settings and adapting the code to suit my needs. I ended up with this:
pcregrep --buffer-size=2M --include=\index.{htm,html} -rilM "(?s)<\!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 3.2 Final//EN\">.*(?s)<HTML>.*<HEAD>.*(?s)<TITLE>Index of " '.' 2>&1 |tee ~/Desktop/blankindex.txt
Firstly, pcregrep has a buffer limit of 20K. Not enough. It outputs errors and messes up my blankindex.txt file. Buffer size booster to 2M. Great!
We only want to include index.htm or index.html files. -rilM, in order: recursive, case-insensitive, list matches show only, search beyond line boundaries. That last one is important. Then you have a bunch of regex stuff stringing all the lines together. The '.' searches the current folder, so make sure you are in the right directory when running this.
But that wasn’t enough, I wanted to send it all to a text file for review. 2>&1 sends errors and terminal output to my new text file, blankindex.txt, using tee. This resulted in the following:
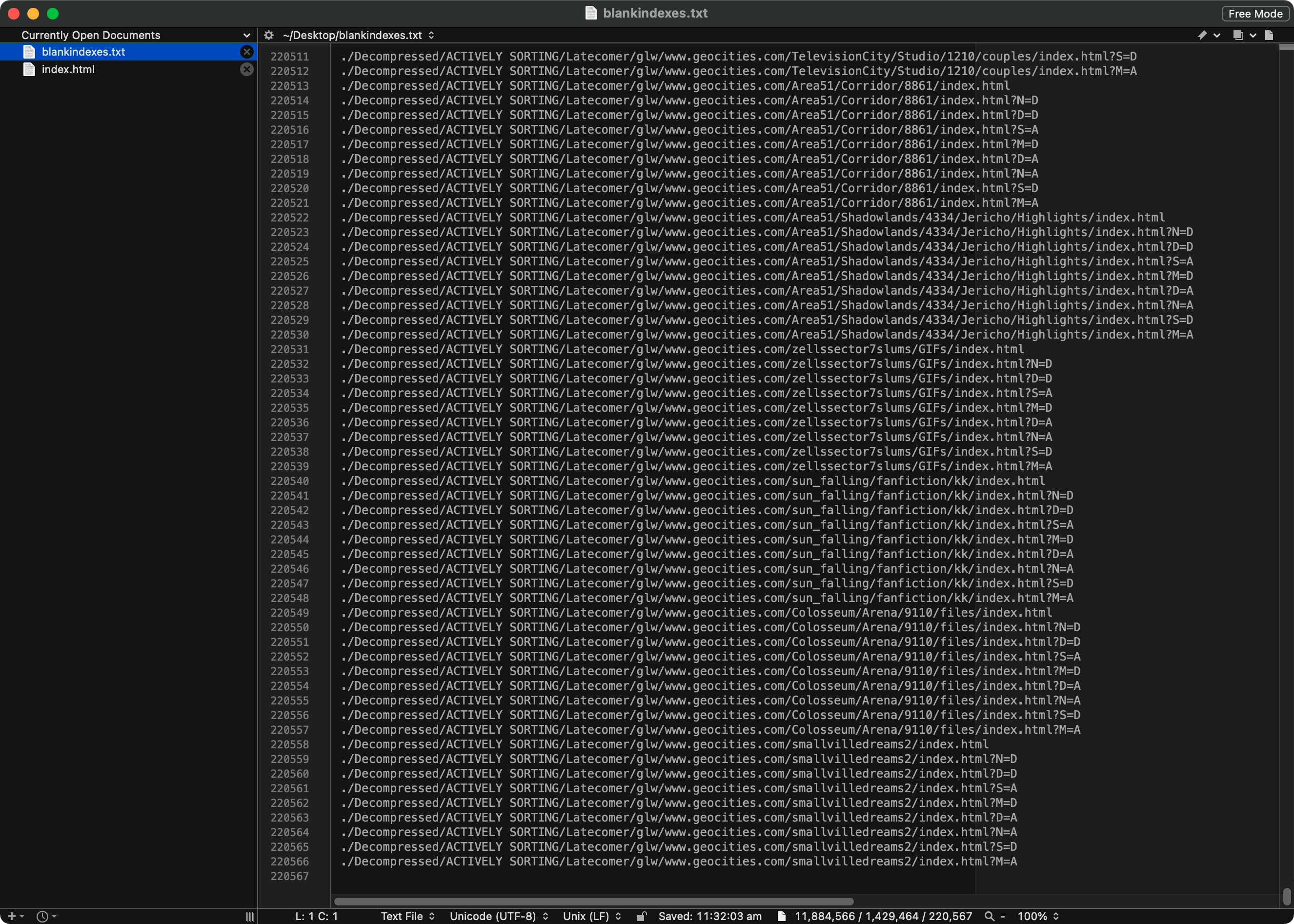
Excellent, I have a massive list of all the directory listing index.html files I don’t want. 219,060 files. Now to check my work, I checked how many index.html files were present overall. How? Well let’s try to dumb down our search with pcregrep. We’ll look for the following in index.html files.
<HTML>
<HEAD>
And we’ll search with this code. This should yield a lot more results.
pcregrep --buffer-size=2M --include=\index.{htm,html} -rilM "(?s)<HTML>.*<HEAD>" '.' 2>&1 |tee ~/Desktop/fullindex.txt
And it did. The original was 12MB at 219,000, the new one was well over 50MB before I cancelled it. There’s definitely a lot of index.html files with both HTML and HEAD tags. Past cool! ![]()
I checked some samples from the blankindex.txt file to make sure I was definitely only removing static directory listings and not user generated content. Everything checked out. Next up, xargs.
xargs -n 1 ls -v < ~/Desktop/blankindex.txt
Whoops. Good thing that had an ls in place of the rm. Apparently white space is not liked by xargs unless enclosed in quotes…
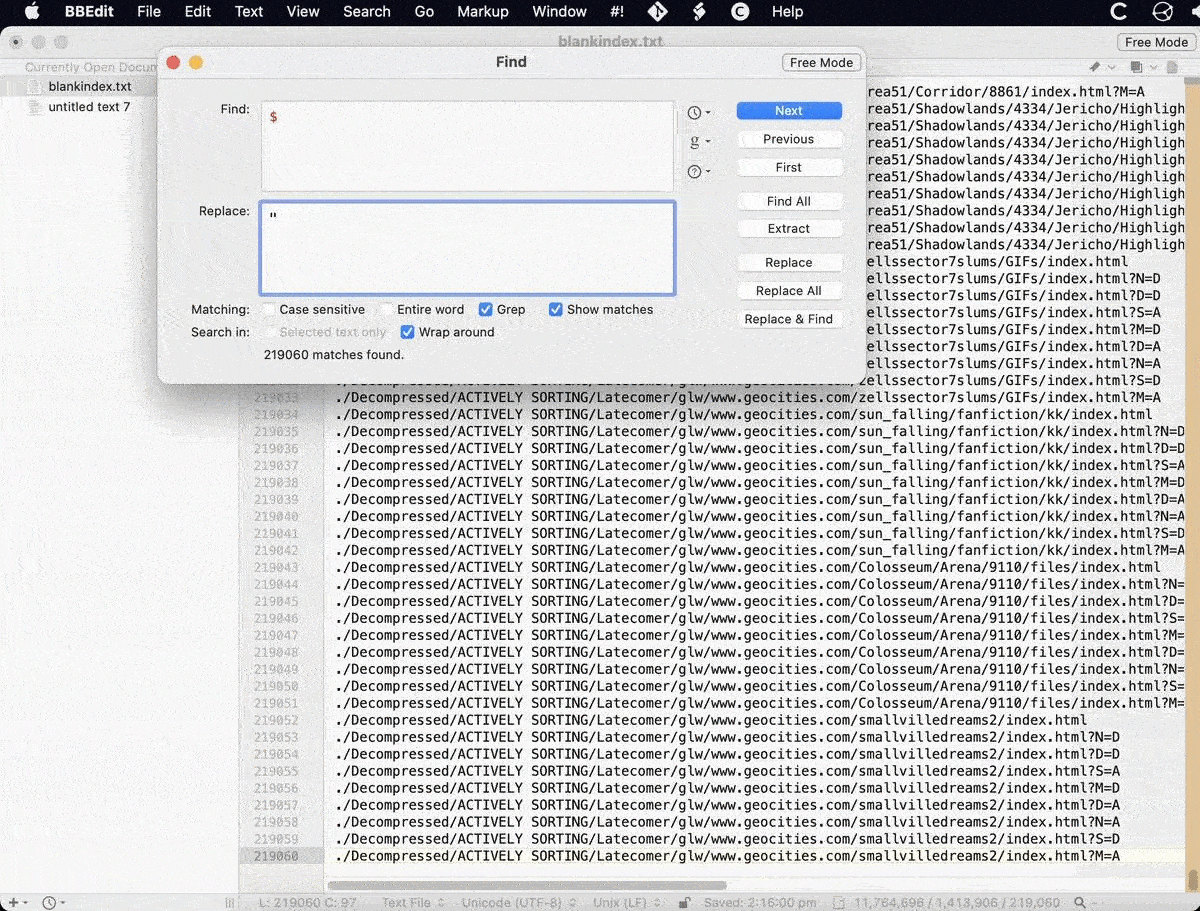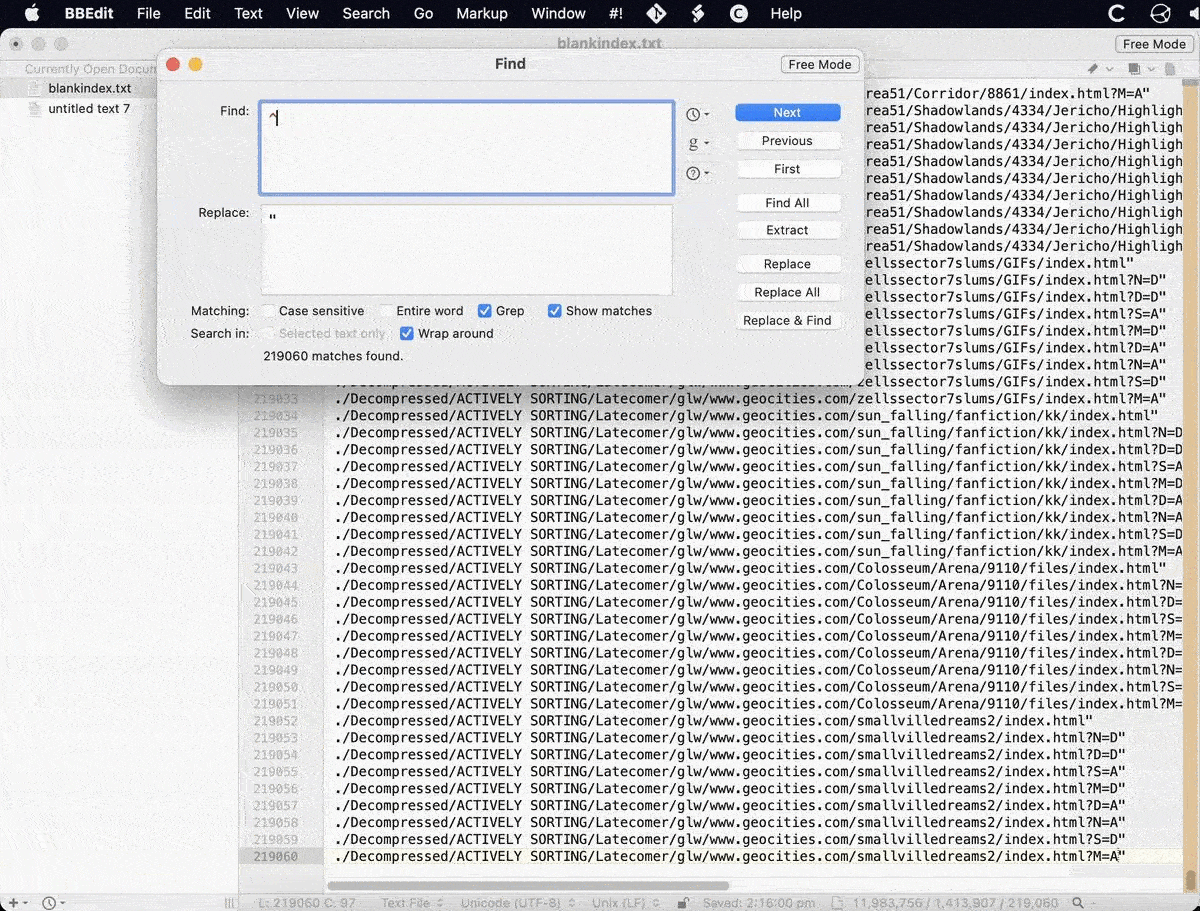
Adding quotes is quite easy using BBEdit as it has a built in grep function. As I just happened to have the knowledge fresh in my memory, I did some grepping to add to the front of each line with the ^ symbol and to the end of each line with a $ symbol. Done. Now the file should be able to get parsed correctly in terminal (Mac OS).
xargs -n 1 ls -v < ~/Desktop/blankindex.txt
A lot of reading indicated I should have been using the -0 (or --null) flag for xargs. I think it would have saved putting the quotes around each line. But I didn’t, I took the risk and watched it list attributes of files in the blankindex.txt file. I checked for any errors. None. We are go for the final command.
xargs -n 1 rm -v < ~/Desktop/blankindex.txt
It worked. Next stop, clean out some more empty files, folders and .DS_Stores:
find . -name .DS_Store -delete
find . -empty -type f -delete
find . -empty -type d -delete
We now have a much tidier directory structure for merging and a lack of empty files (or useless files) will prevent collisions when merging folders. We’ll have a look at more case sensitivity, redirection loops, sitemap and jump tomorrow.