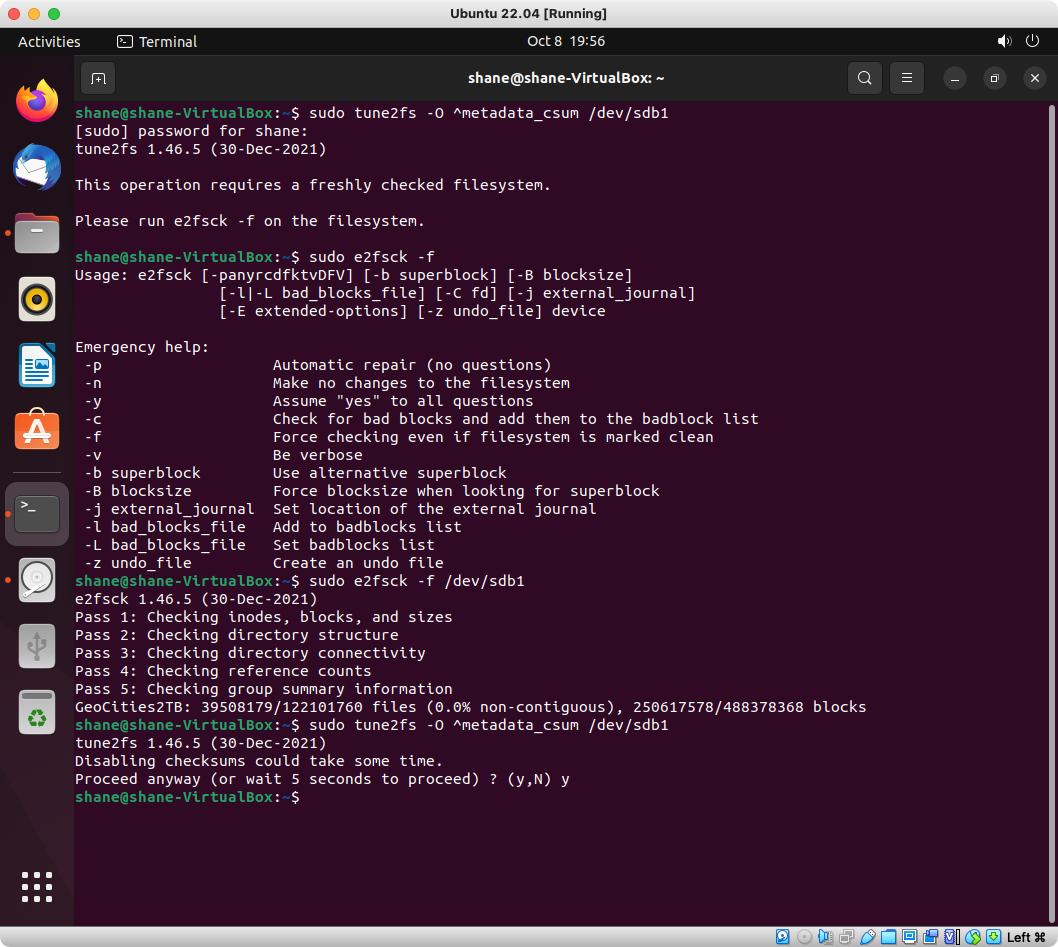
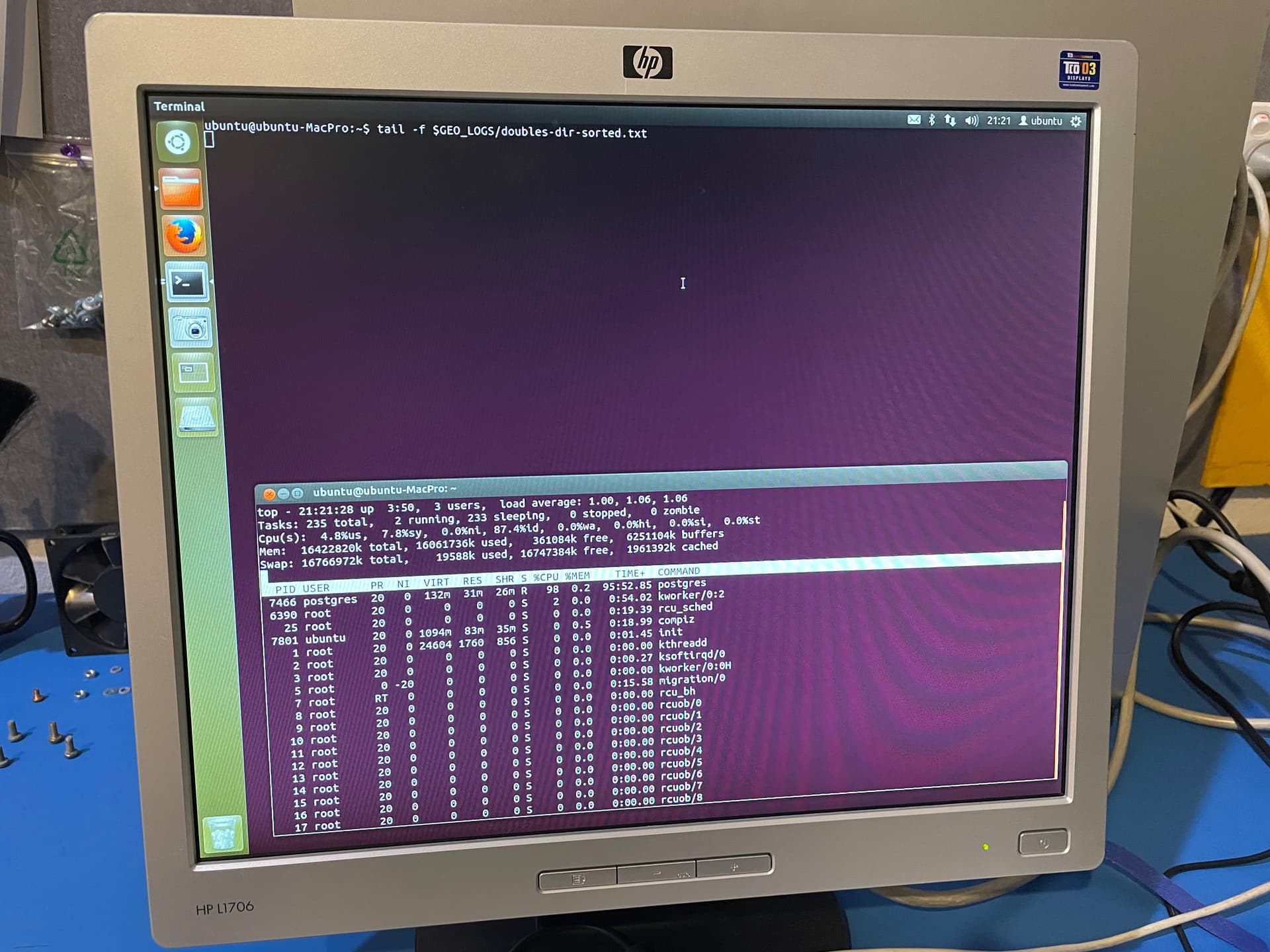
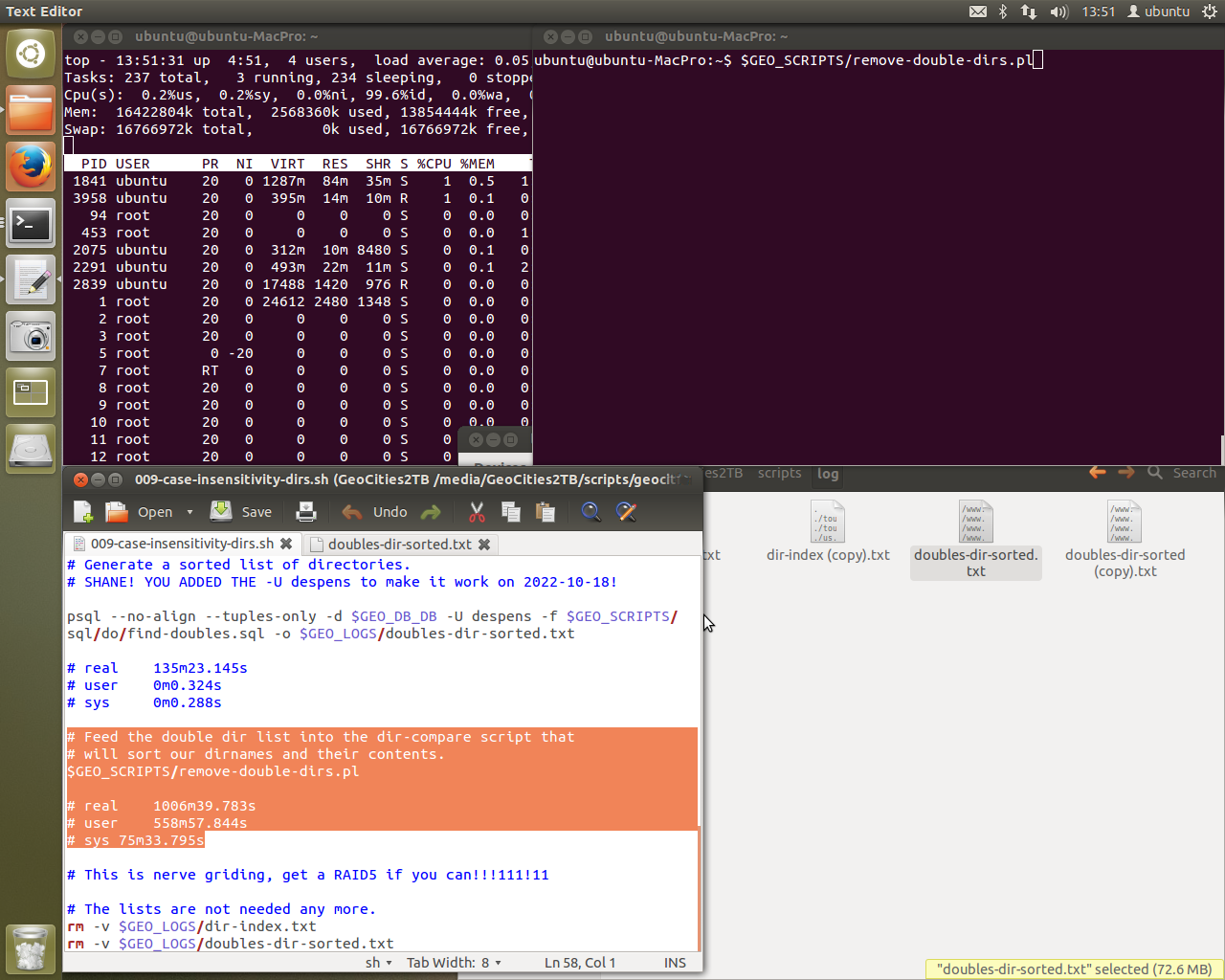
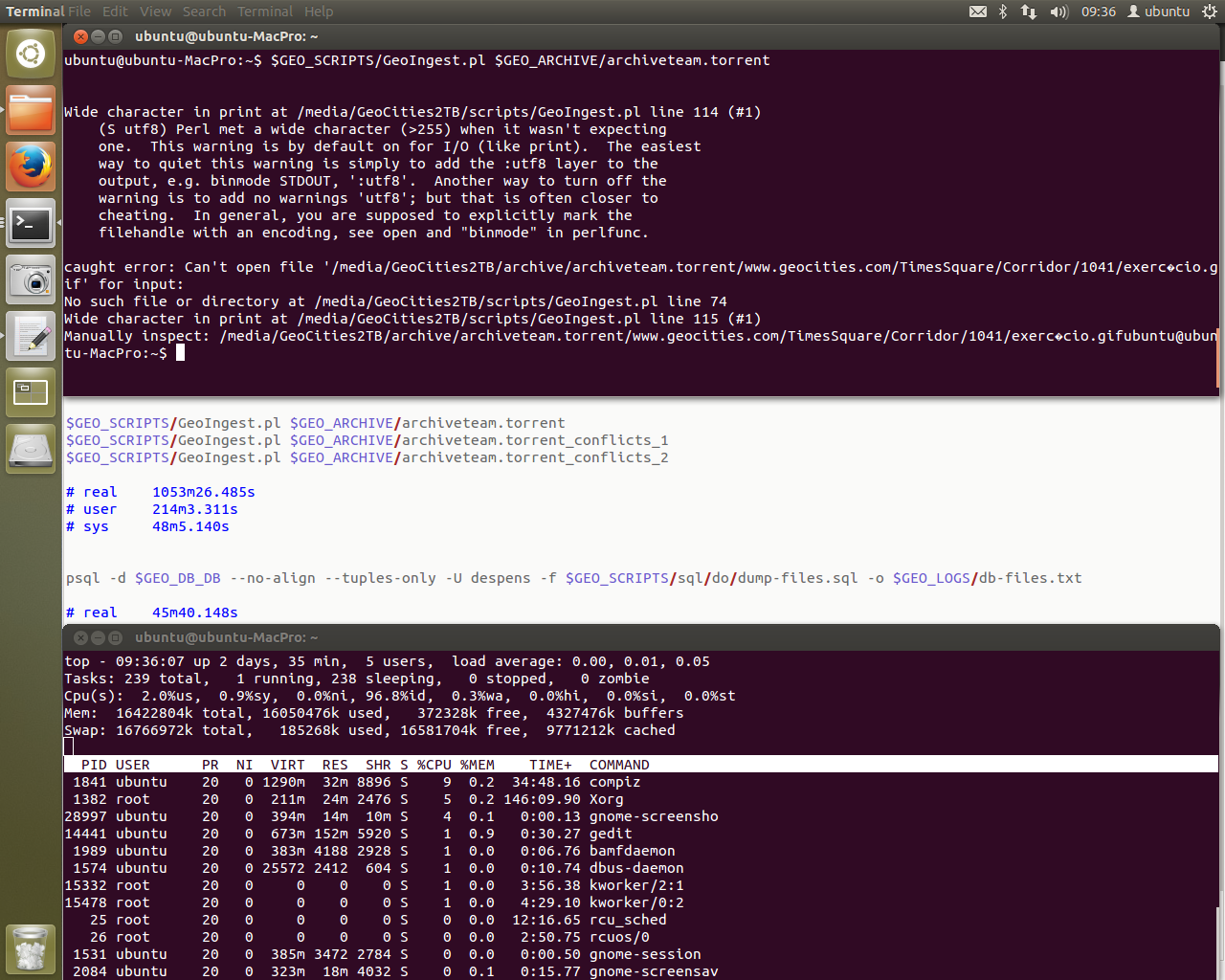
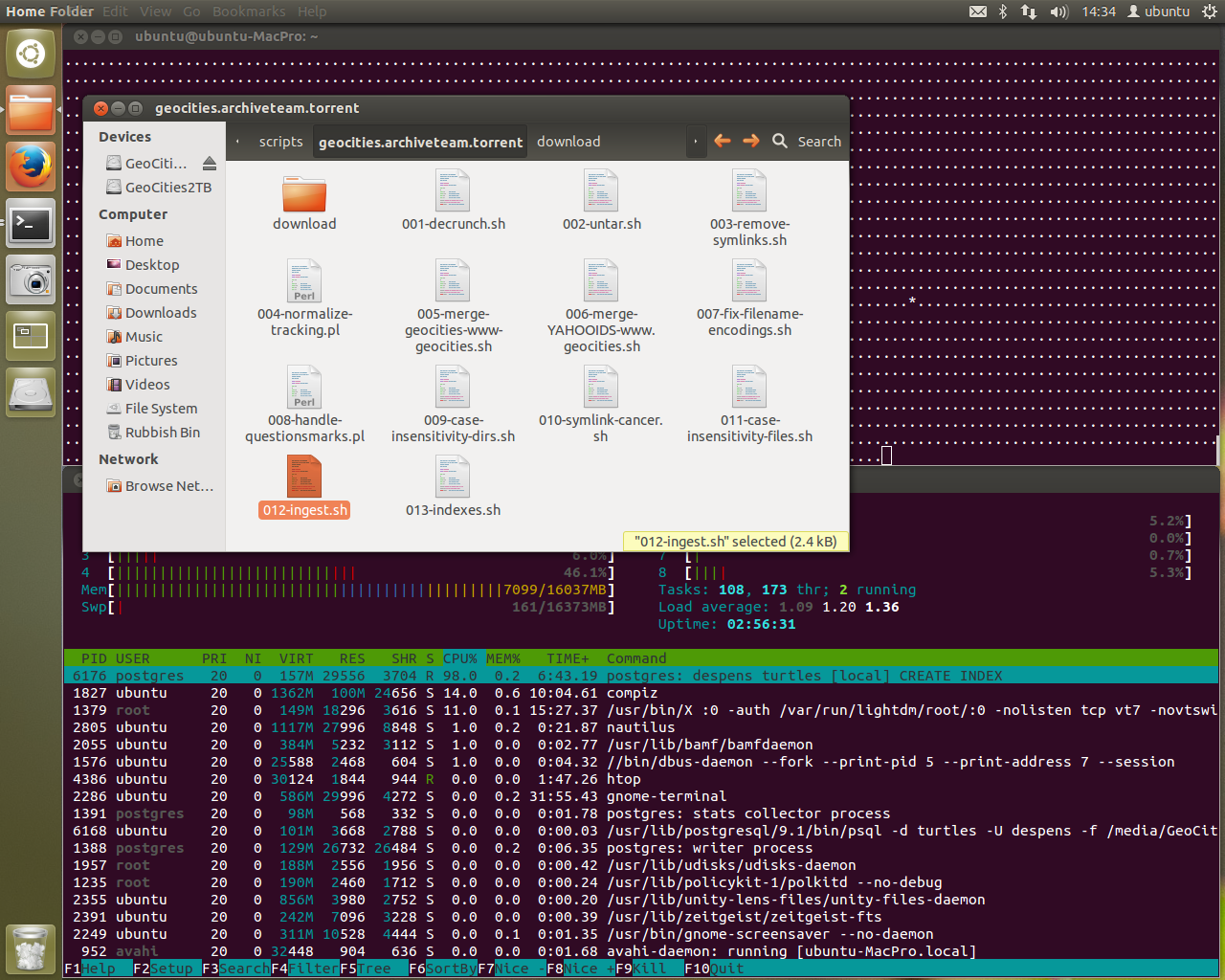
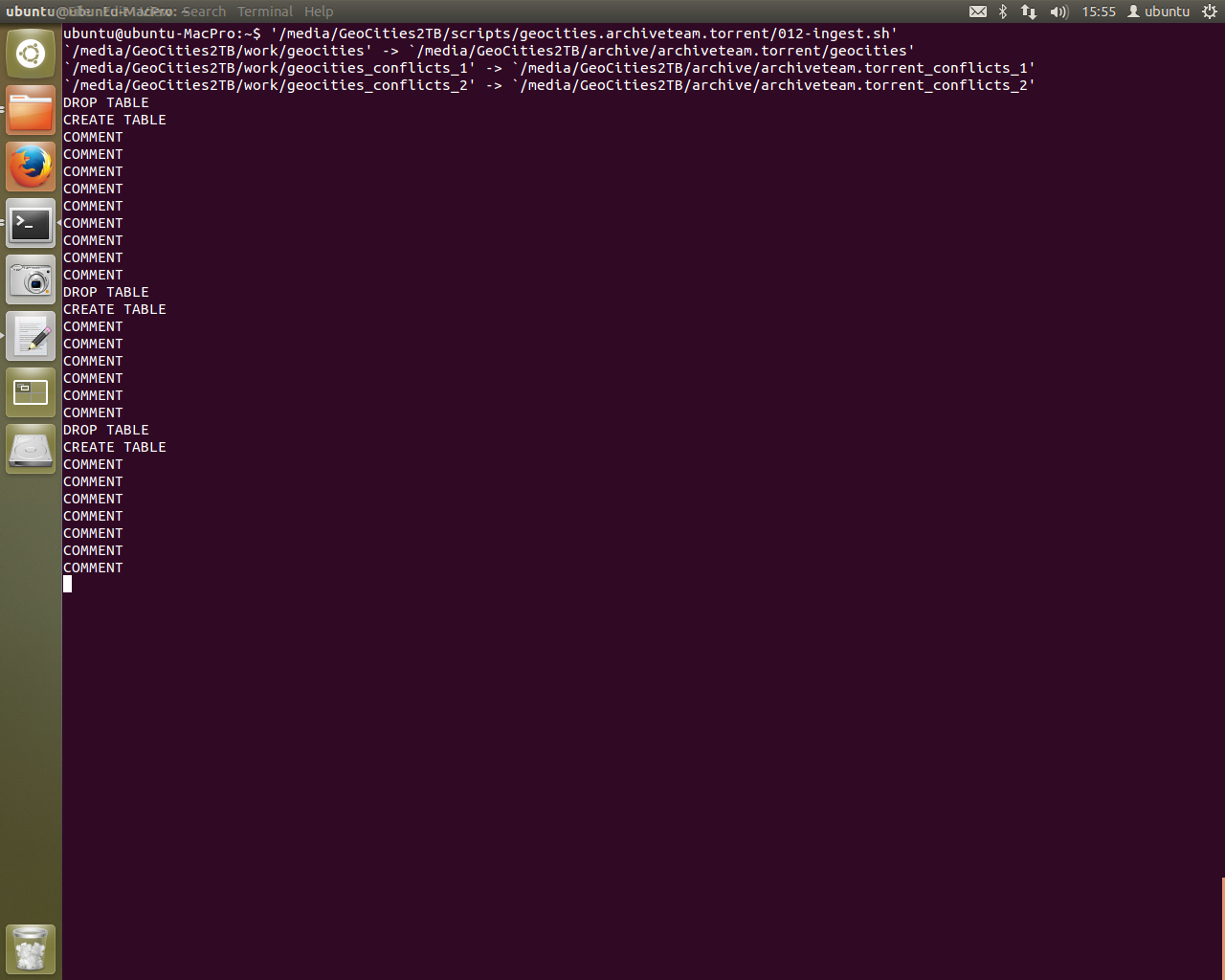
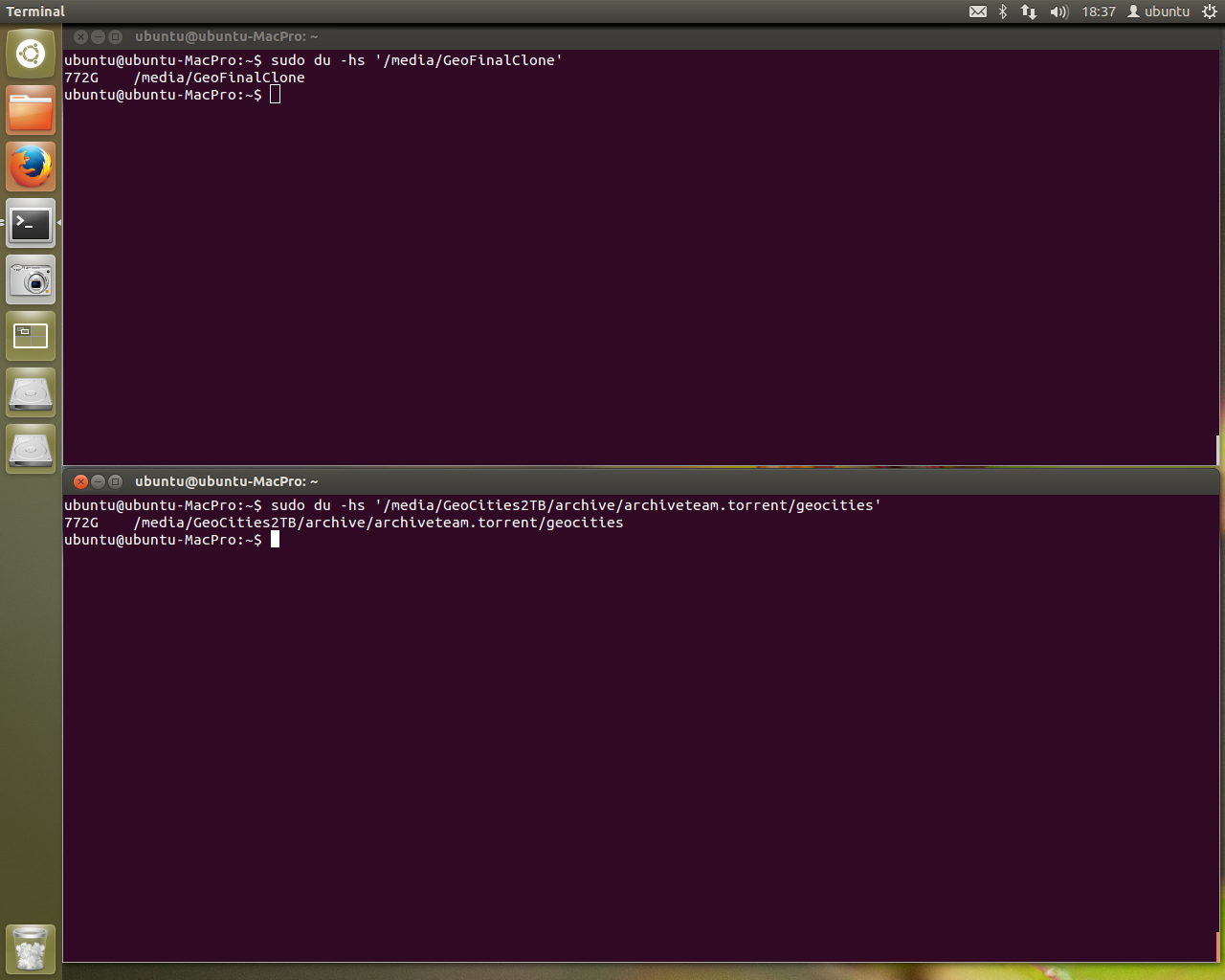
Words fail me. It’s actually running. Previously we’d get stuck on the highlighted text in ingest-doubles.pl at printing the asterisk. Now you can see the asterisk happily being printed in the terminal window at the back of all the windows. It’s committing records to the database.
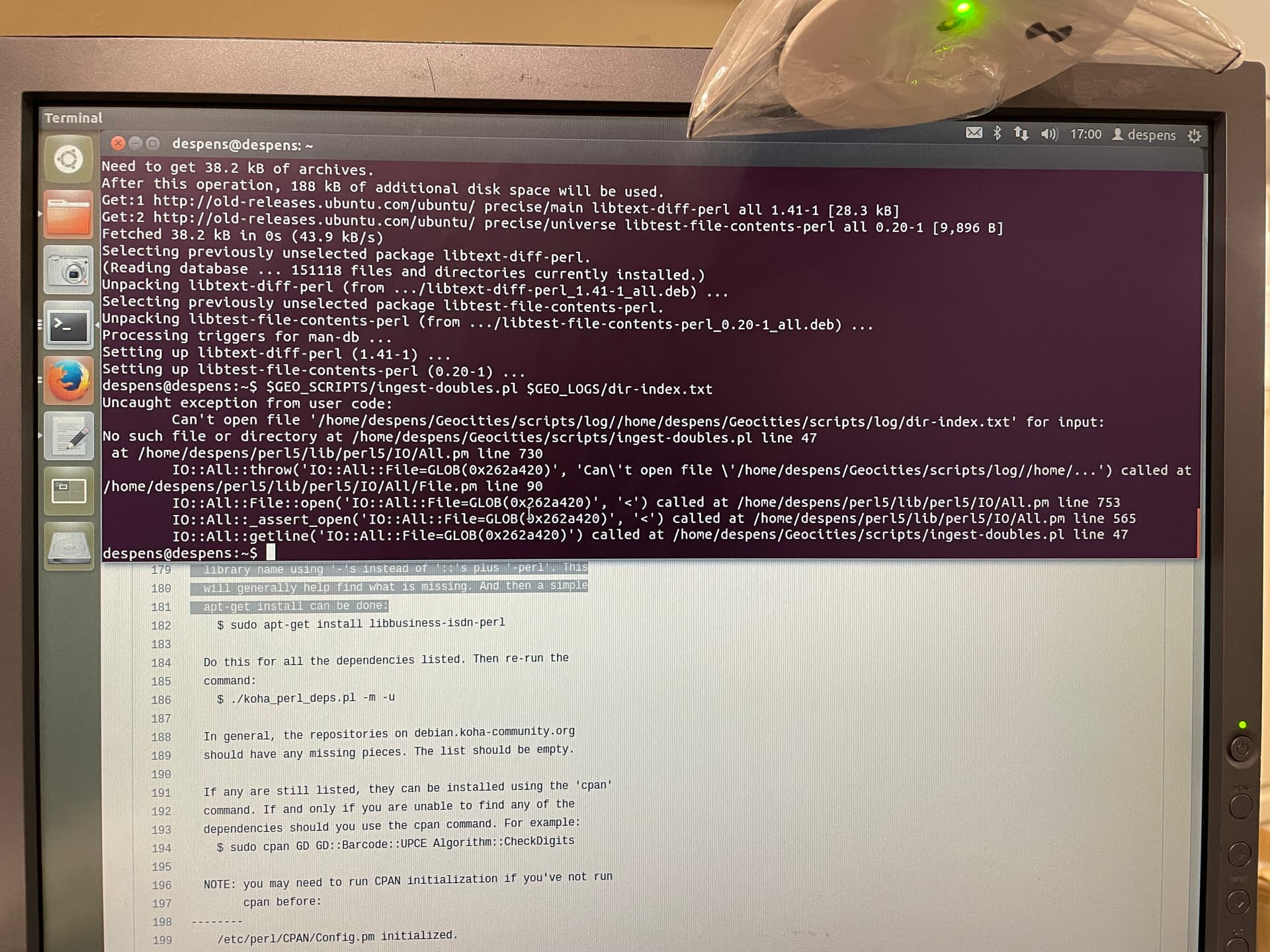
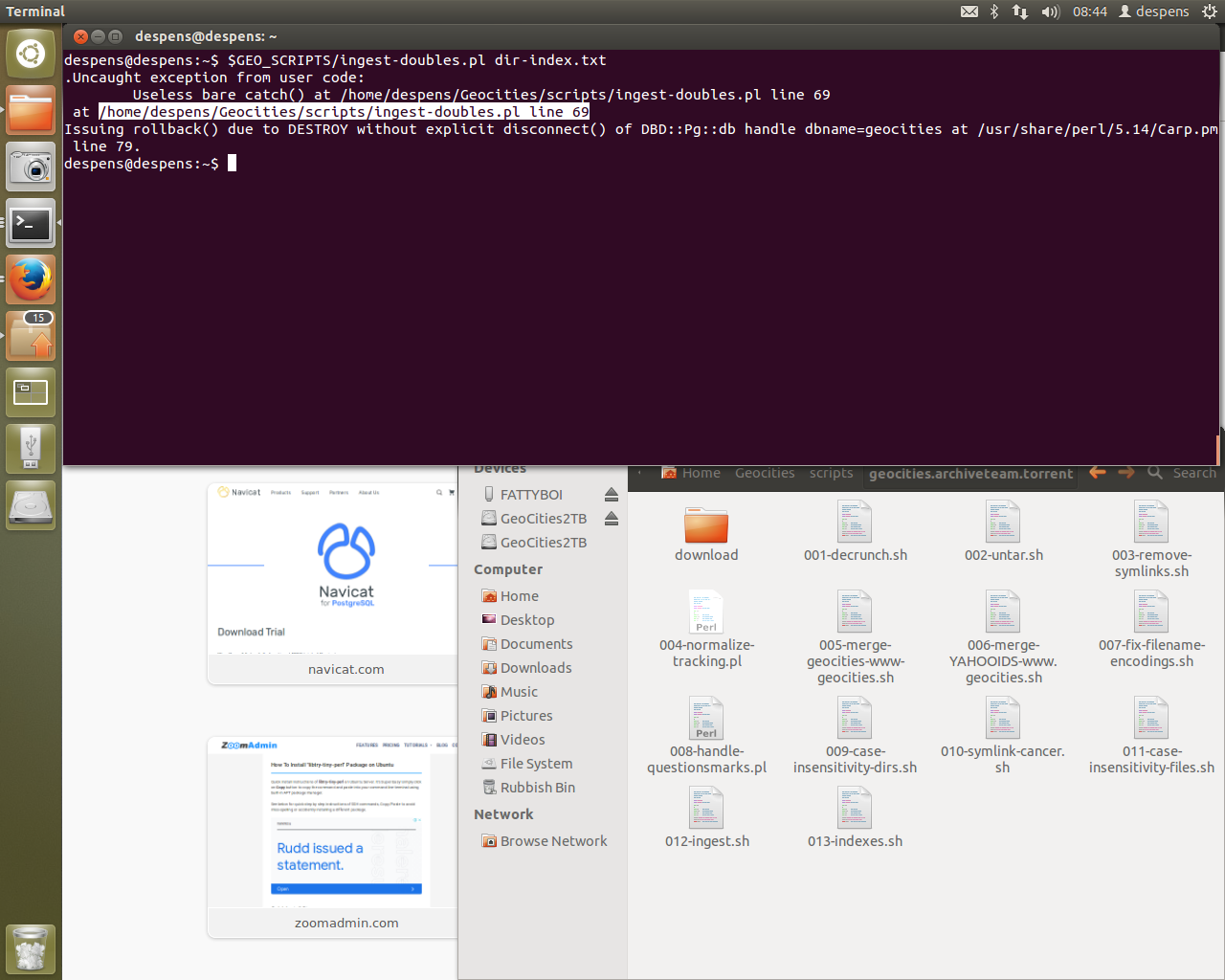
The “line 69” error that was being encountered is gone. In order to fix it, I blew away the entire Ubuntu 12.04 install and started again. Following my install steps from above for dependencies, I had installed some Perl modules not through Ubuntu’s package manager (apt-get) but through CPAN. This was a big mistake.
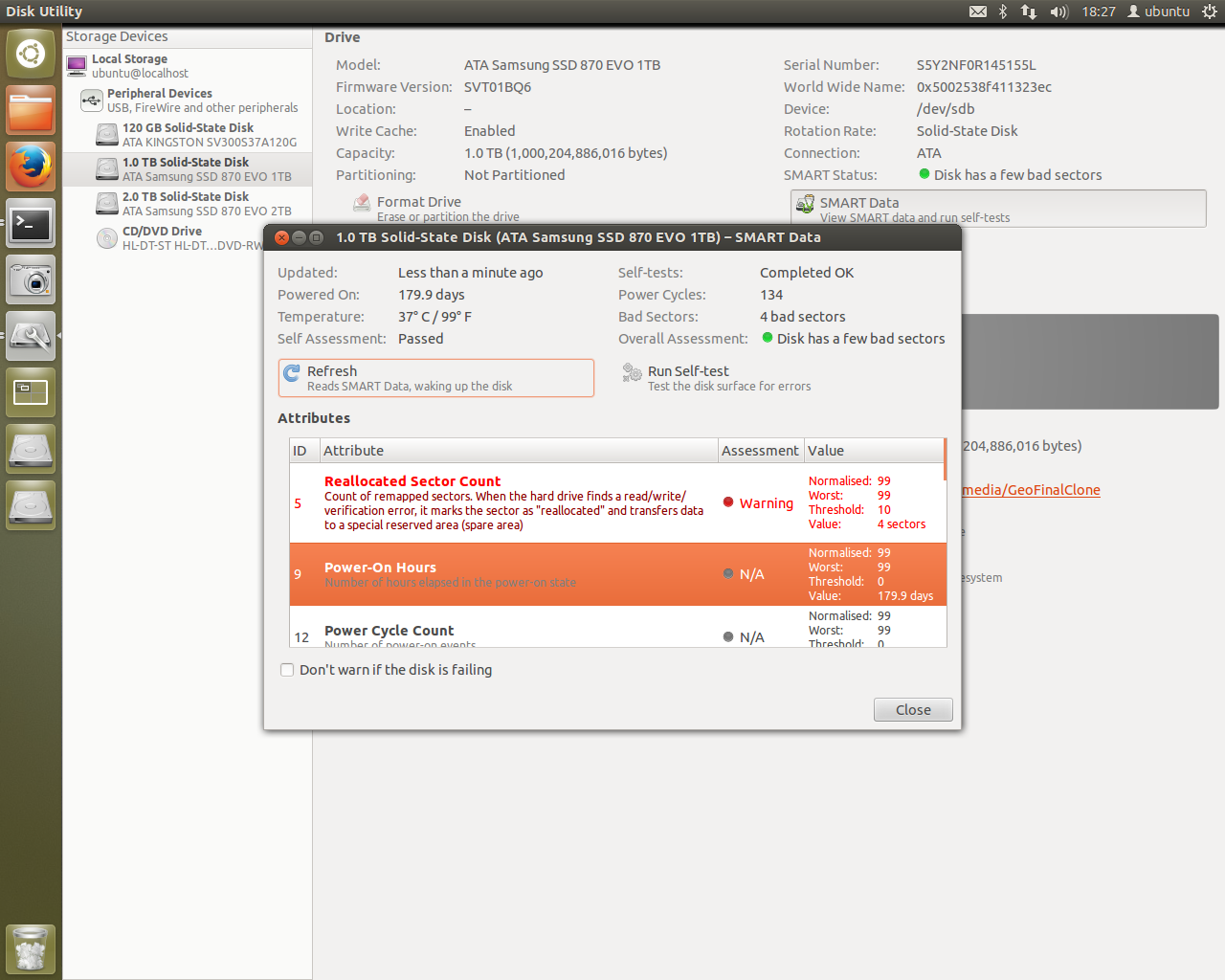
Sure, the window server seems crashing if I monitor the stats via the System Monitor GUI. That might be caused by a lack of proprietary NVIDIA drivers I haven’t quite installed yet. I also had some issues with setting up psql (again) with my notes not quite working but I eventually pushed on to work out the configuration. It was a little different as I didn’t choose the Ubuntu user to be named “despens”, but “ubuntu” instead.
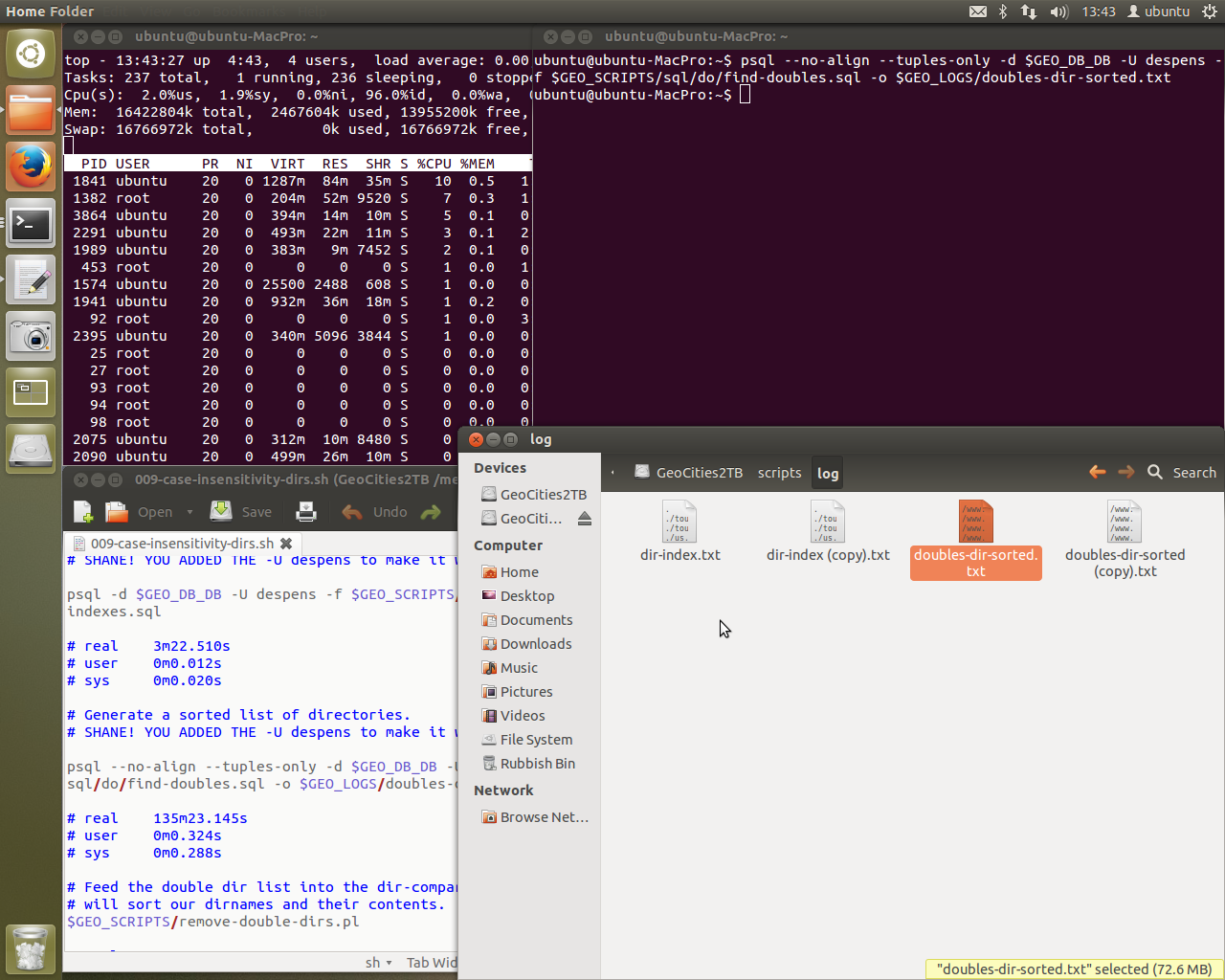
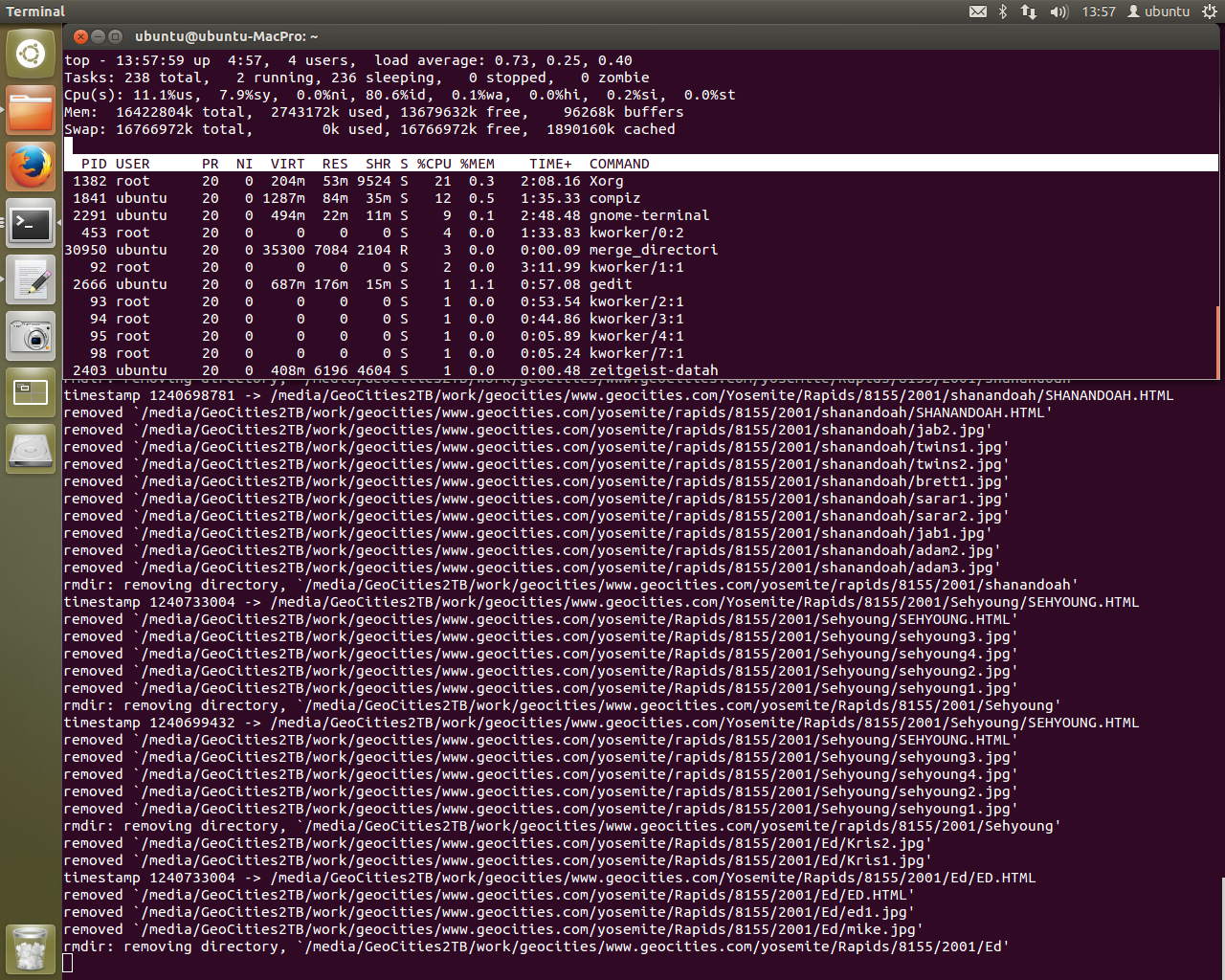
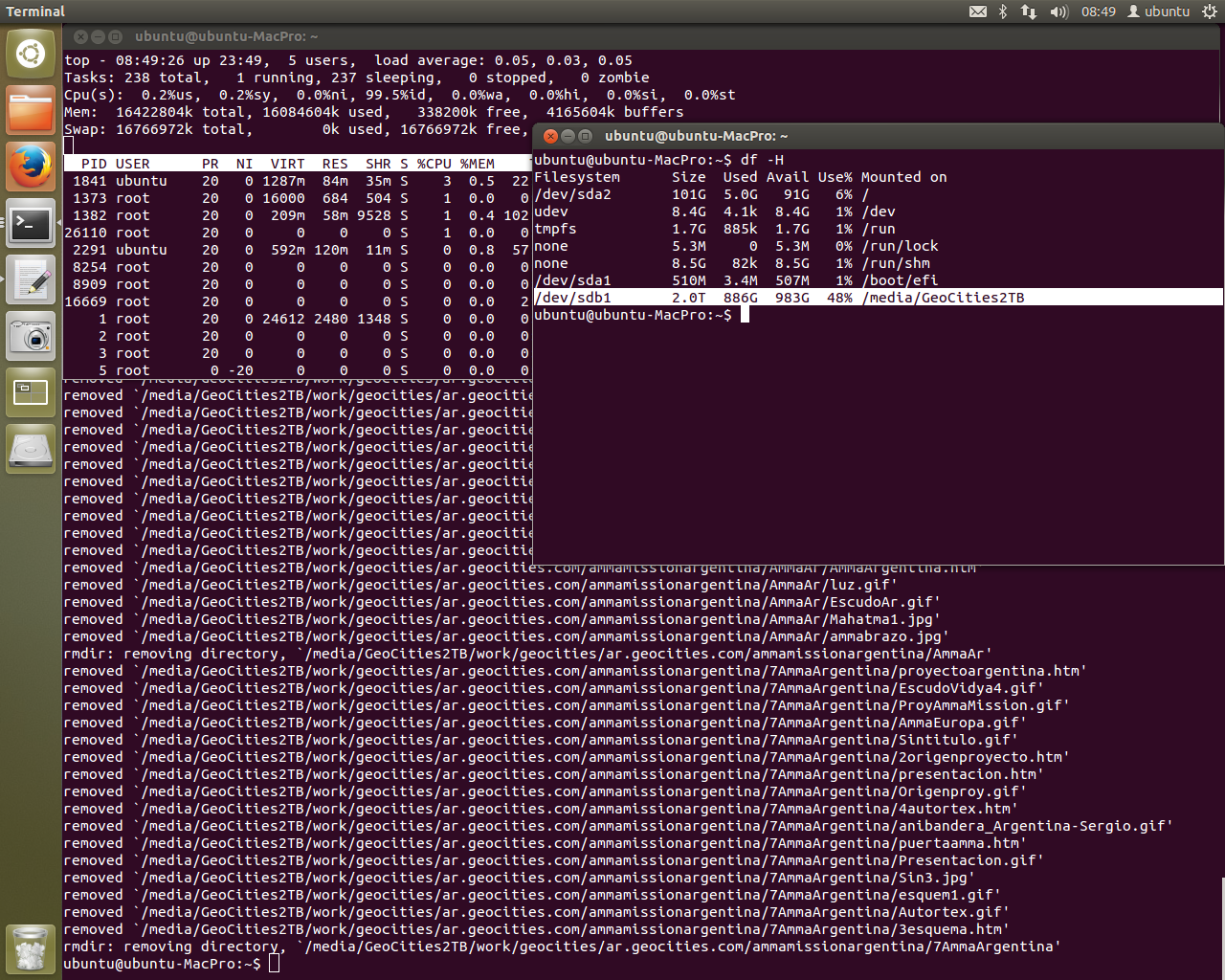
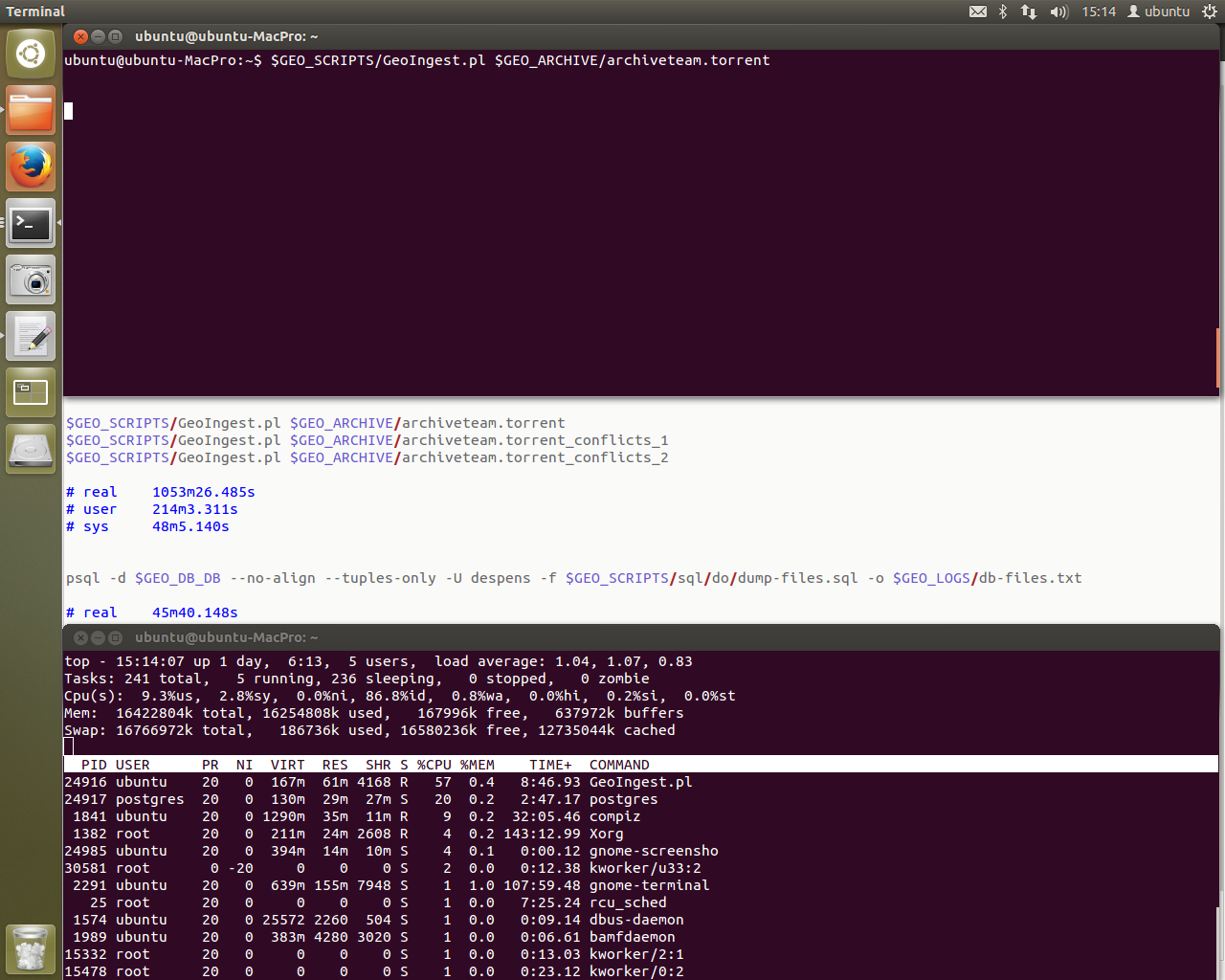
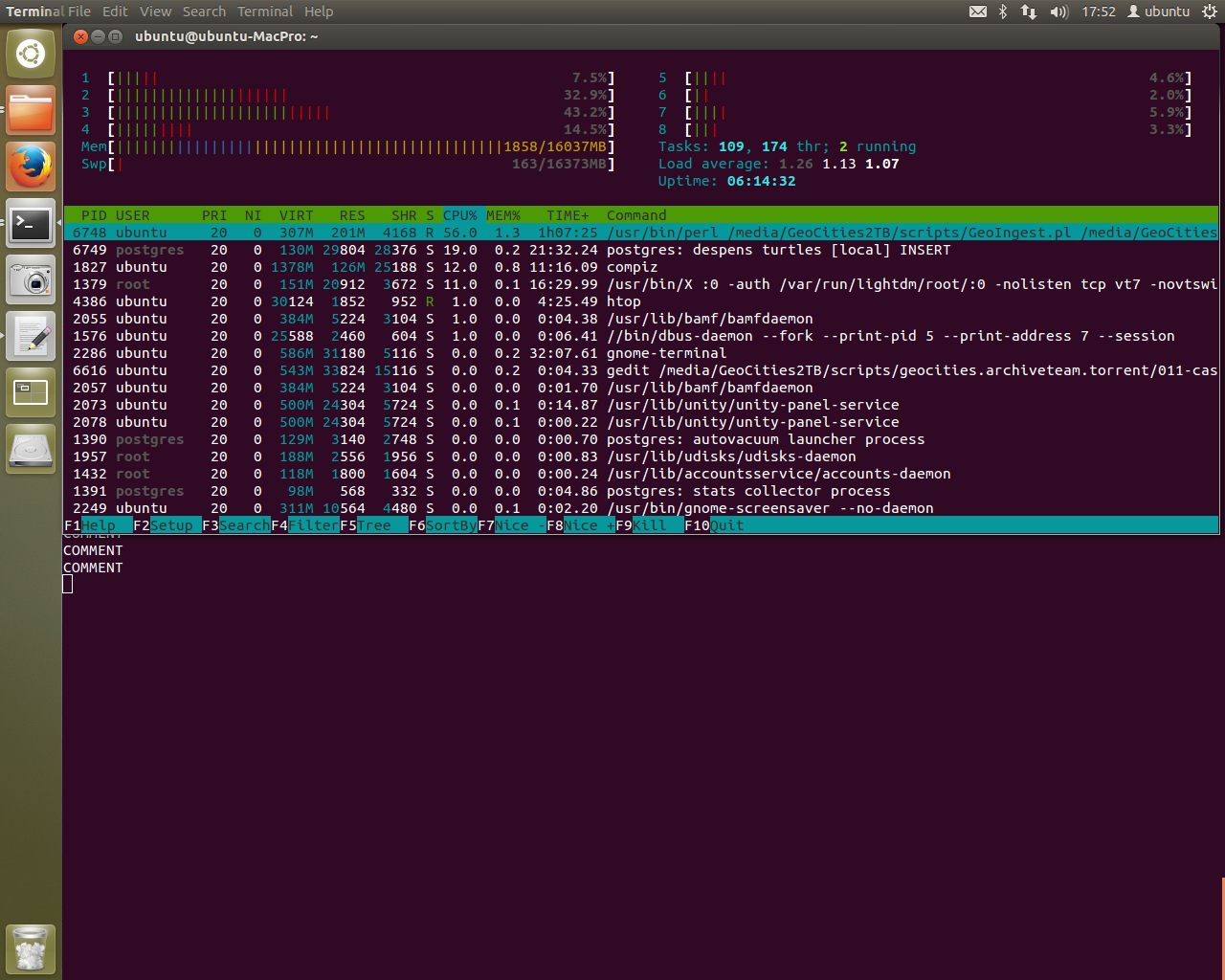
To avoid crashing the system, we now use top instead. Postgres is running crazy on one of the CPU cores. Lucky for me single core processing is where this machine excels. When I left it, we were stepping through script 009 to check for any errors. So far so good. This is the best condition I’ve seen the script in to date. If all goes well I’ll have data in the terminal window in the background.
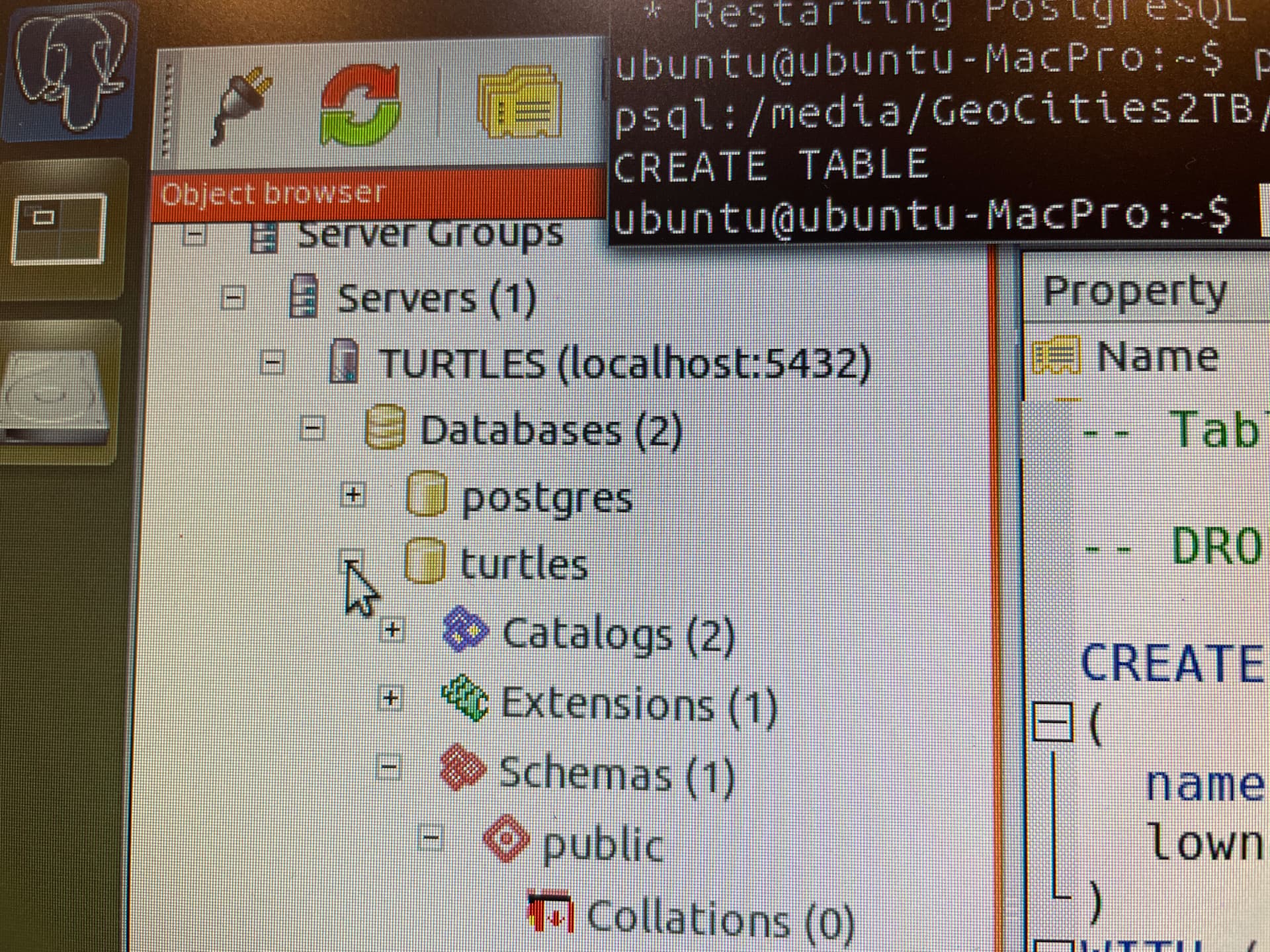
To shake things up a little, I added a database named turtles - instead of Geocities and everything just started working. Are the turtles watching over me, keeping this database safe? It’s the only thing that makes sense. 
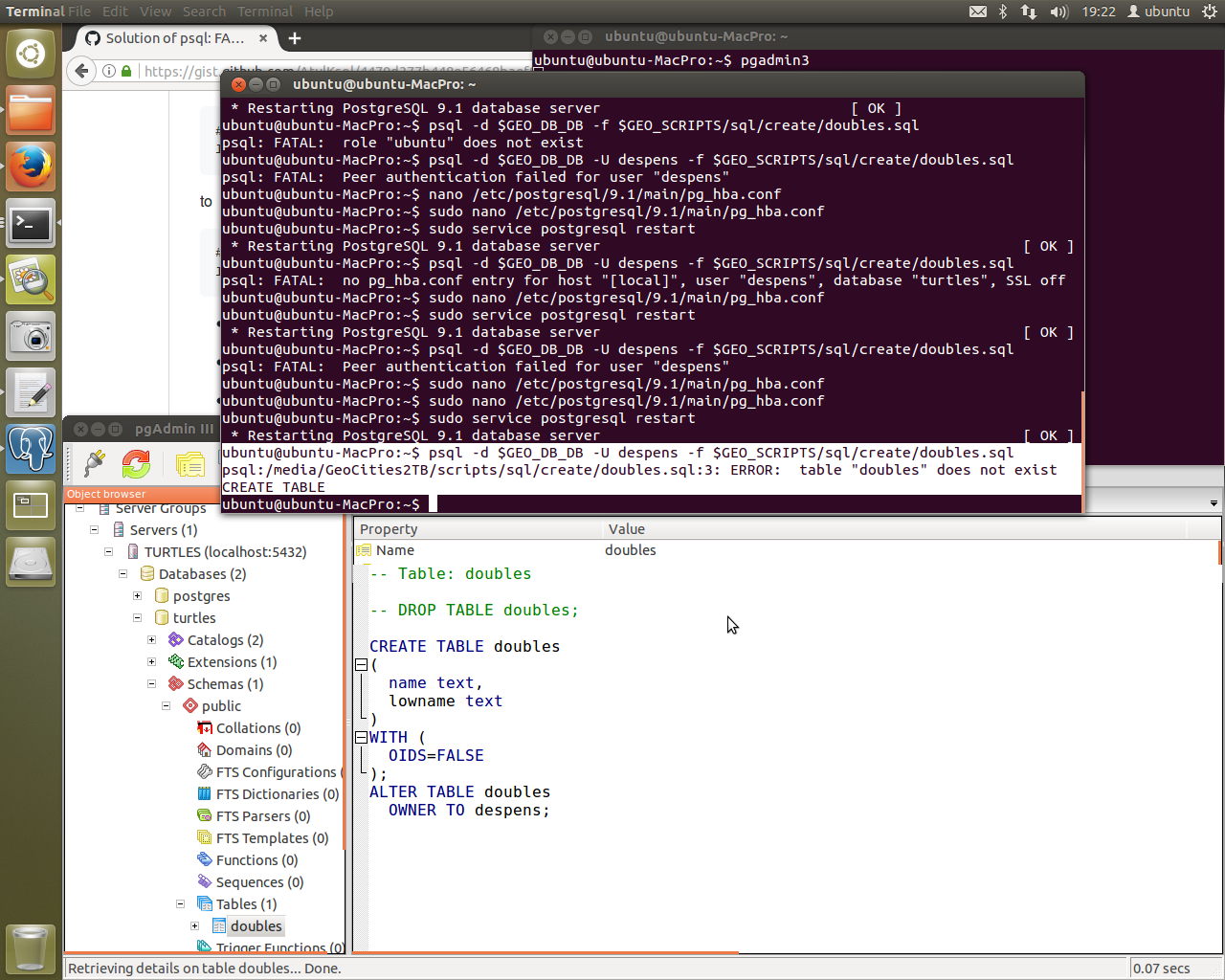
I’ve also been using pgAdmin3 (via GUI) in cahoots with psql (via CLI) to get an idea of what I am doing what I drop a database or create a table or forget to give the user any permissions. It has been extremely helpful in visualising the database structure. To install it just run the following:
sudo apt-get install pgadmin3
The final step in the 009 script is to run a ~18-24 hour script - a lot to ask for a database that wouldn’t even connect yesterday. After this there is one other large processing step, step 012 - the ingest.
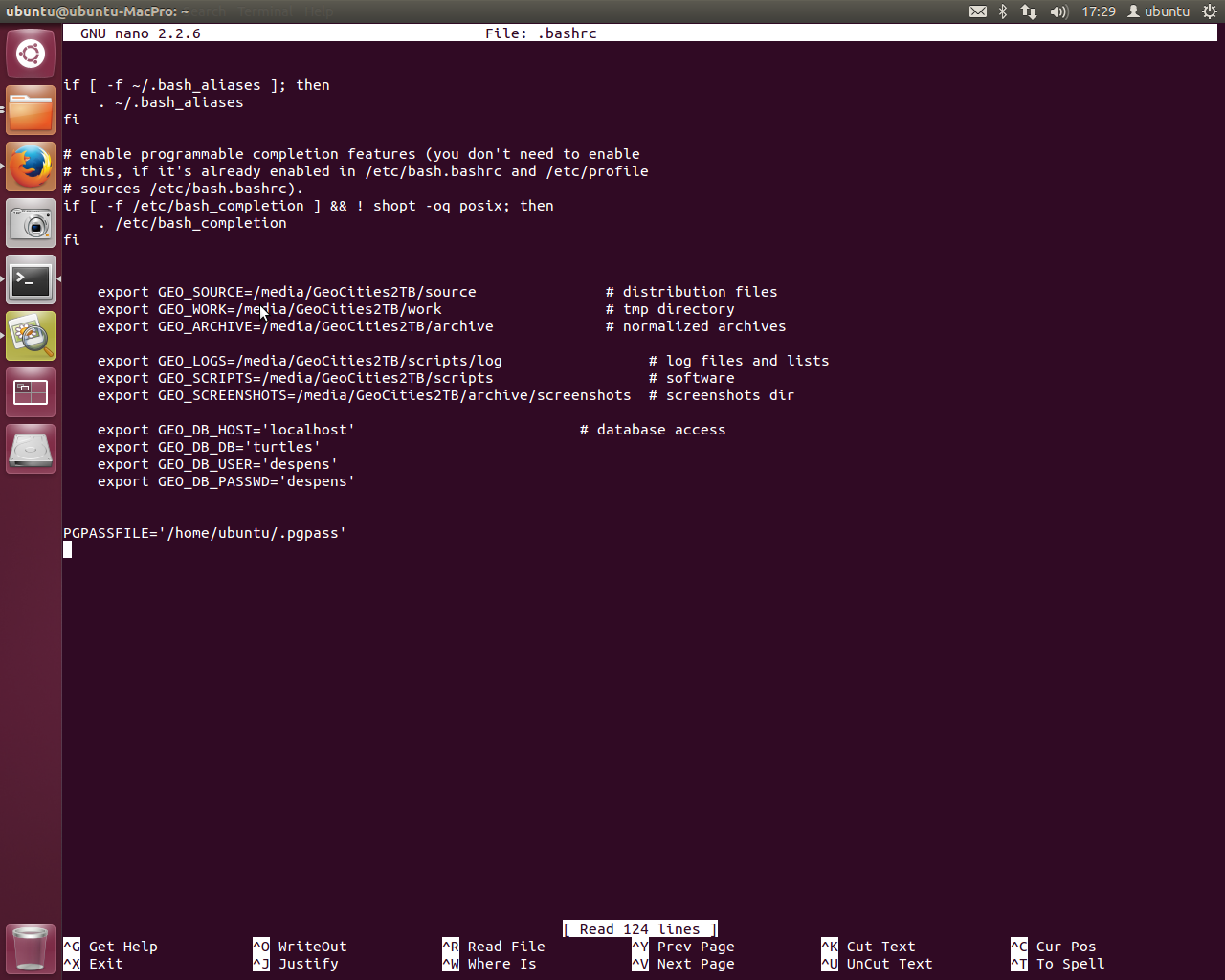
Here’s the environment variables I was using in ~/.bashrc
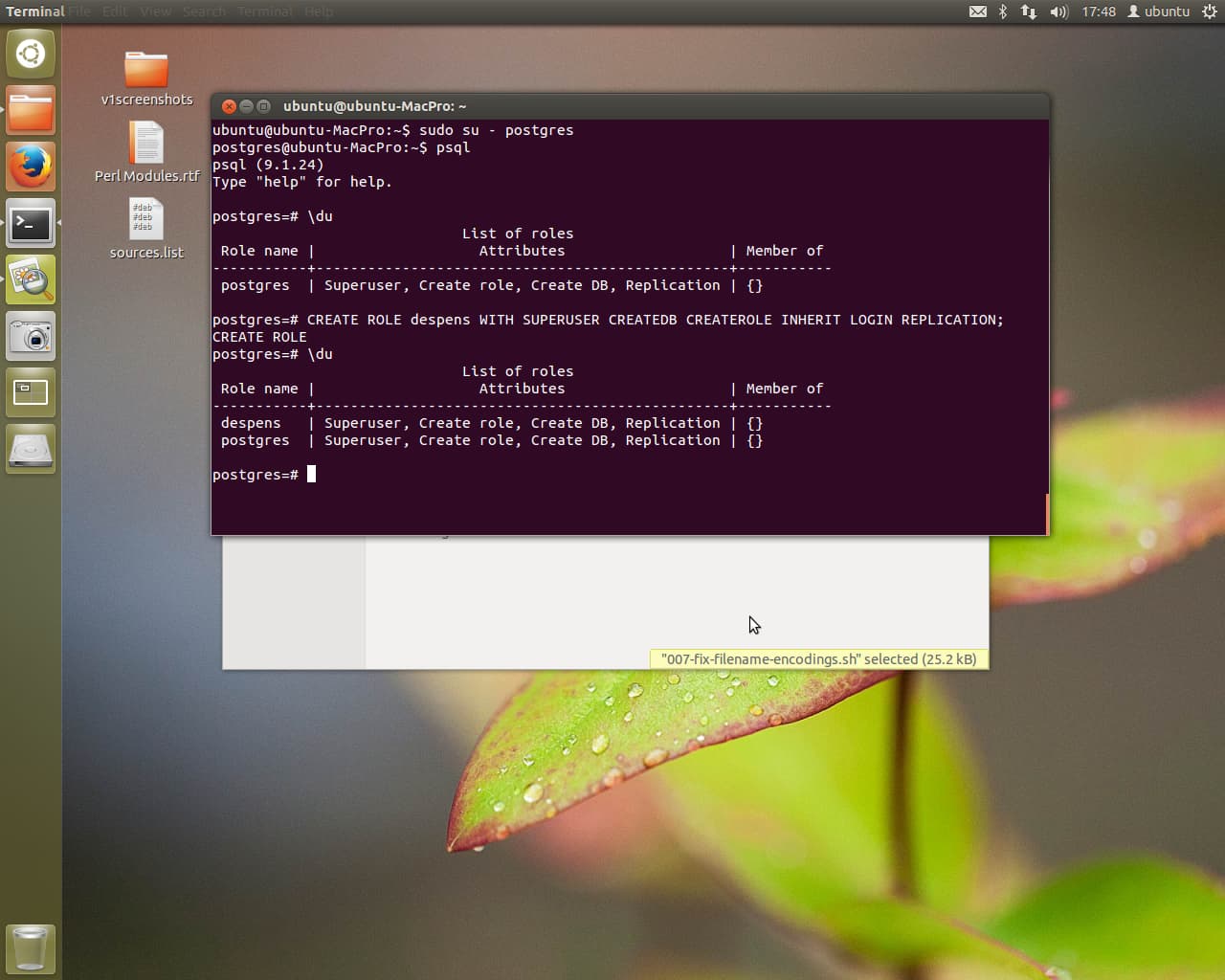
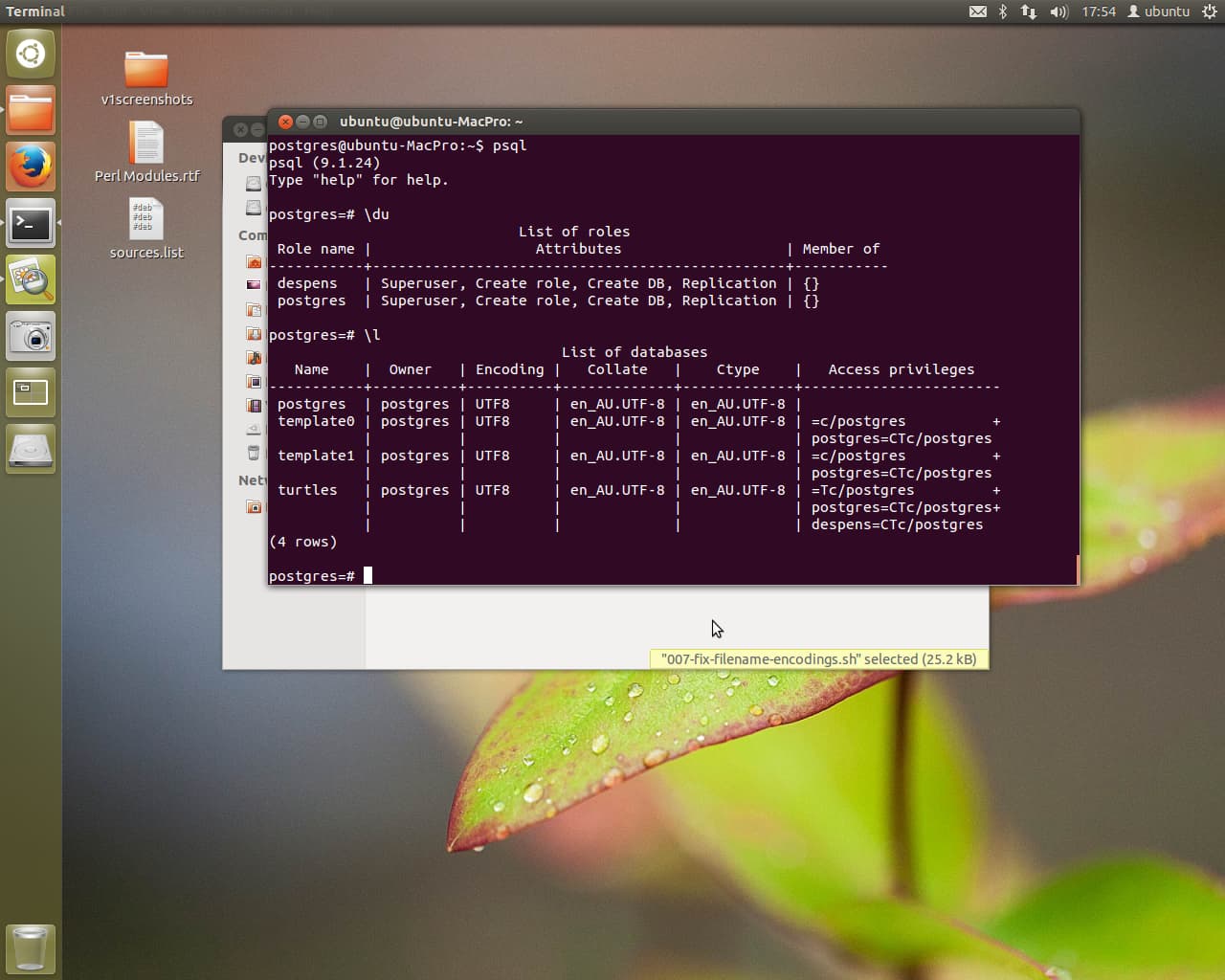
It’s important to login as postgres to edit things via sudo su -postgres. You’ll note the prompt change from ubuntu@ubuntu-MacPro:~$ to postgres@ubuntu-MacPro:~$. This allows psql to access postgres, the superuser for psql. We then create a new role for the despens user and verify the user has been created with the same permissions as the superuser postgres.
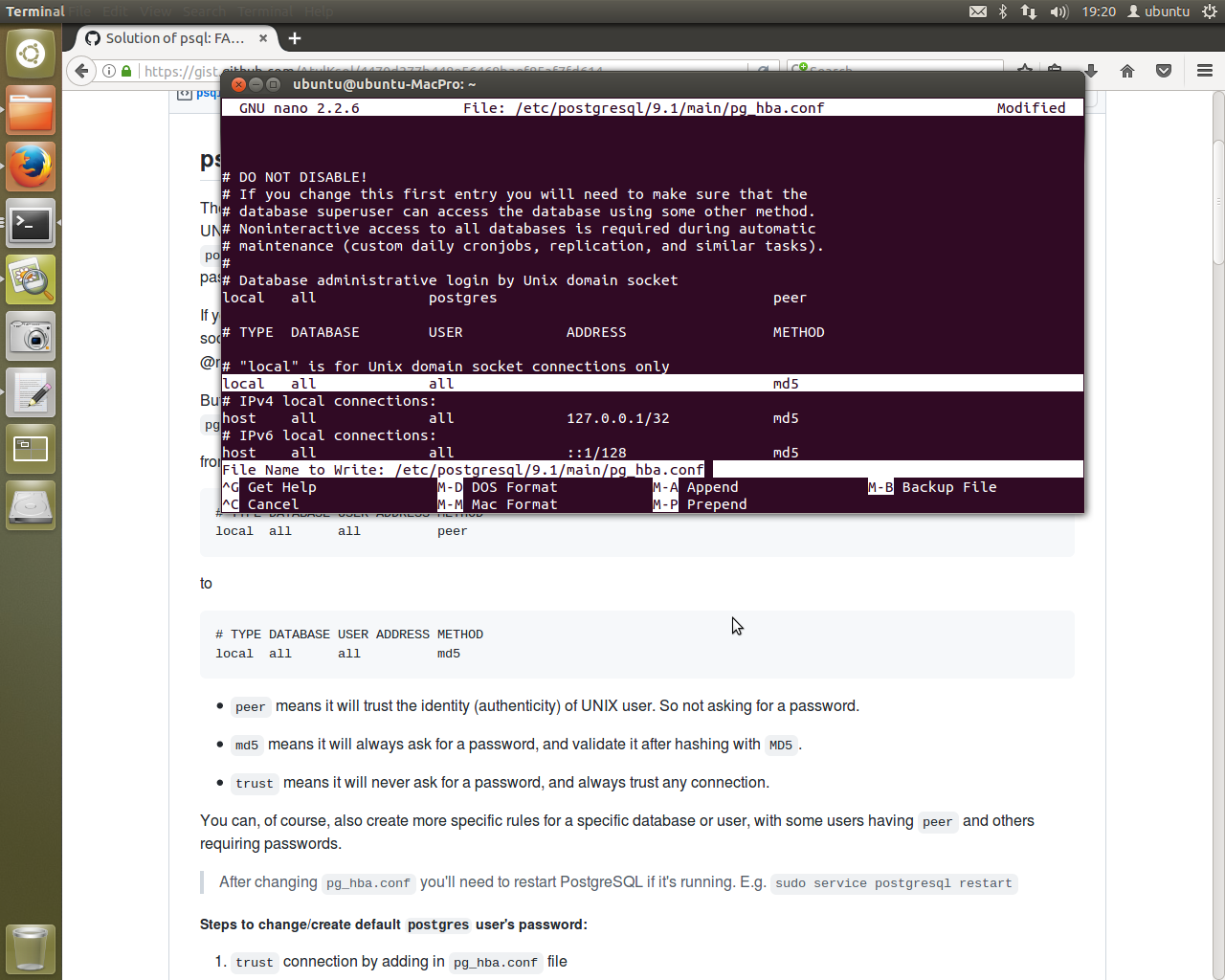
Additional work to get the database to be able to connect to the script via despens user was needed on two files followed by a services restart. Editing /etc/postqresql/9.1/main/pq hba.conf as above. This lets everything connect, however it wants. That’s fine. This isn’t going to be a production machine with an open to the internet database subject to hackers.
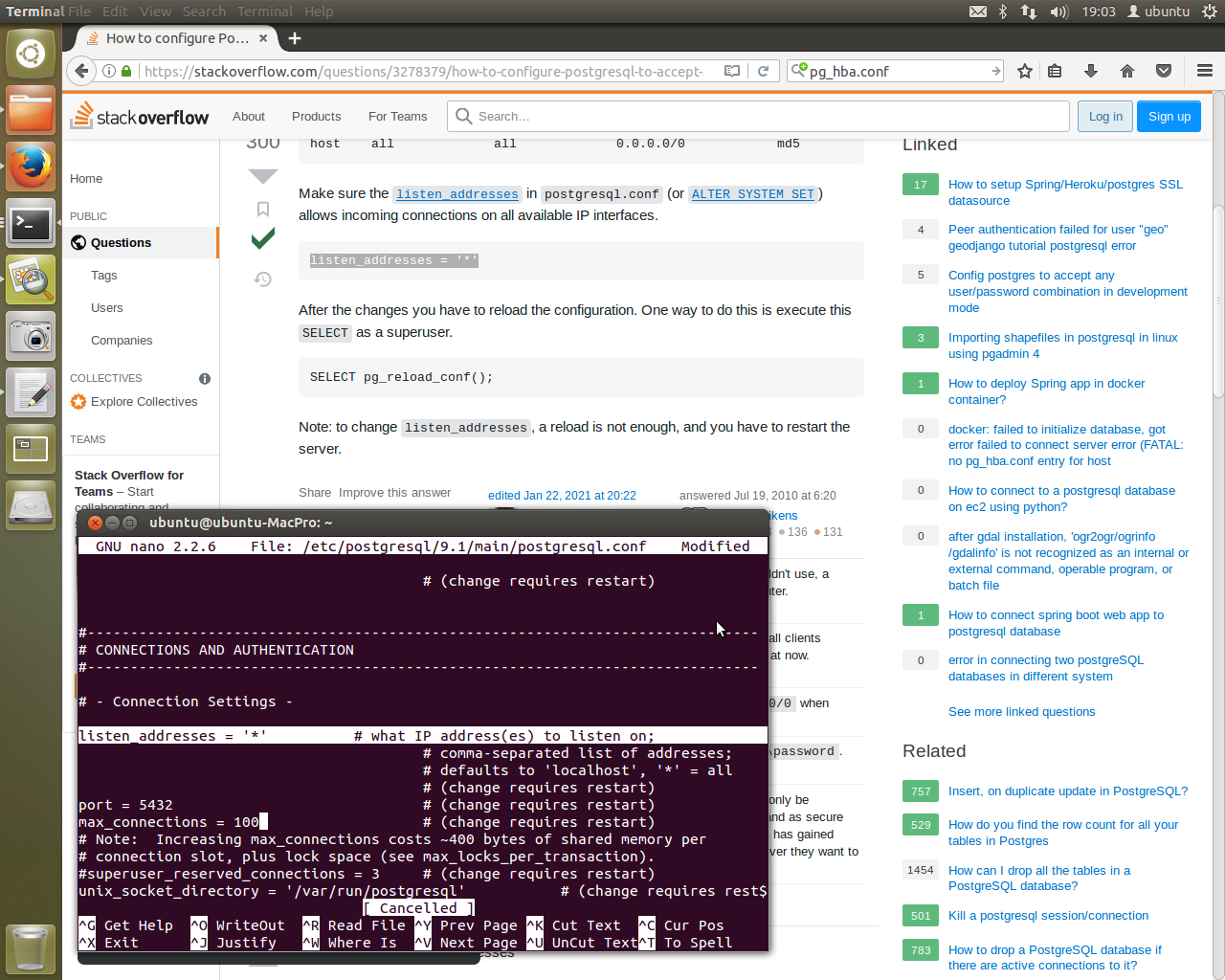
The second file, /etc/postaresql/9.1/main/postgresql.conf, needs to be edited to allow all listening on all address. Once done, a simple…
sudo service postgresql restart
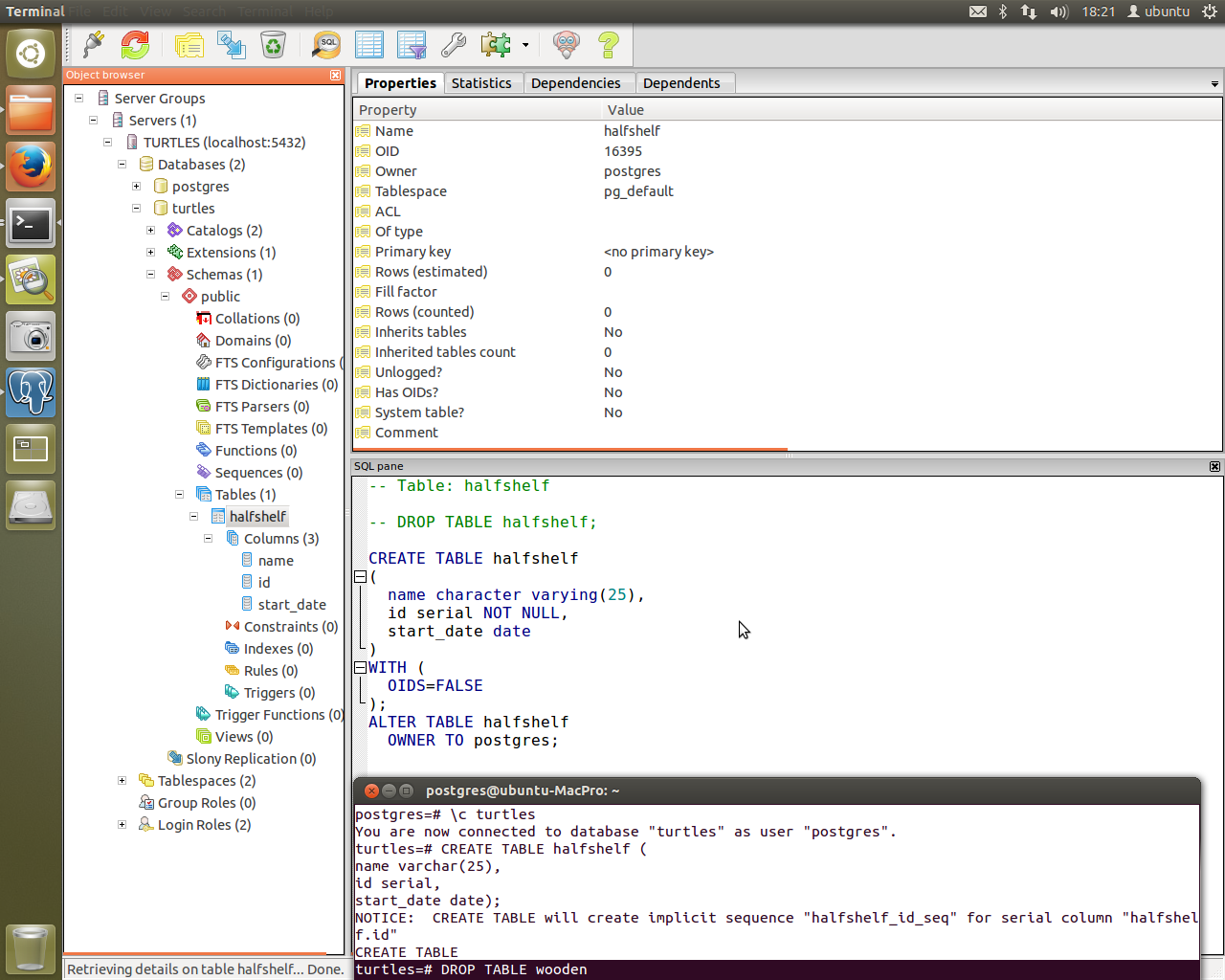
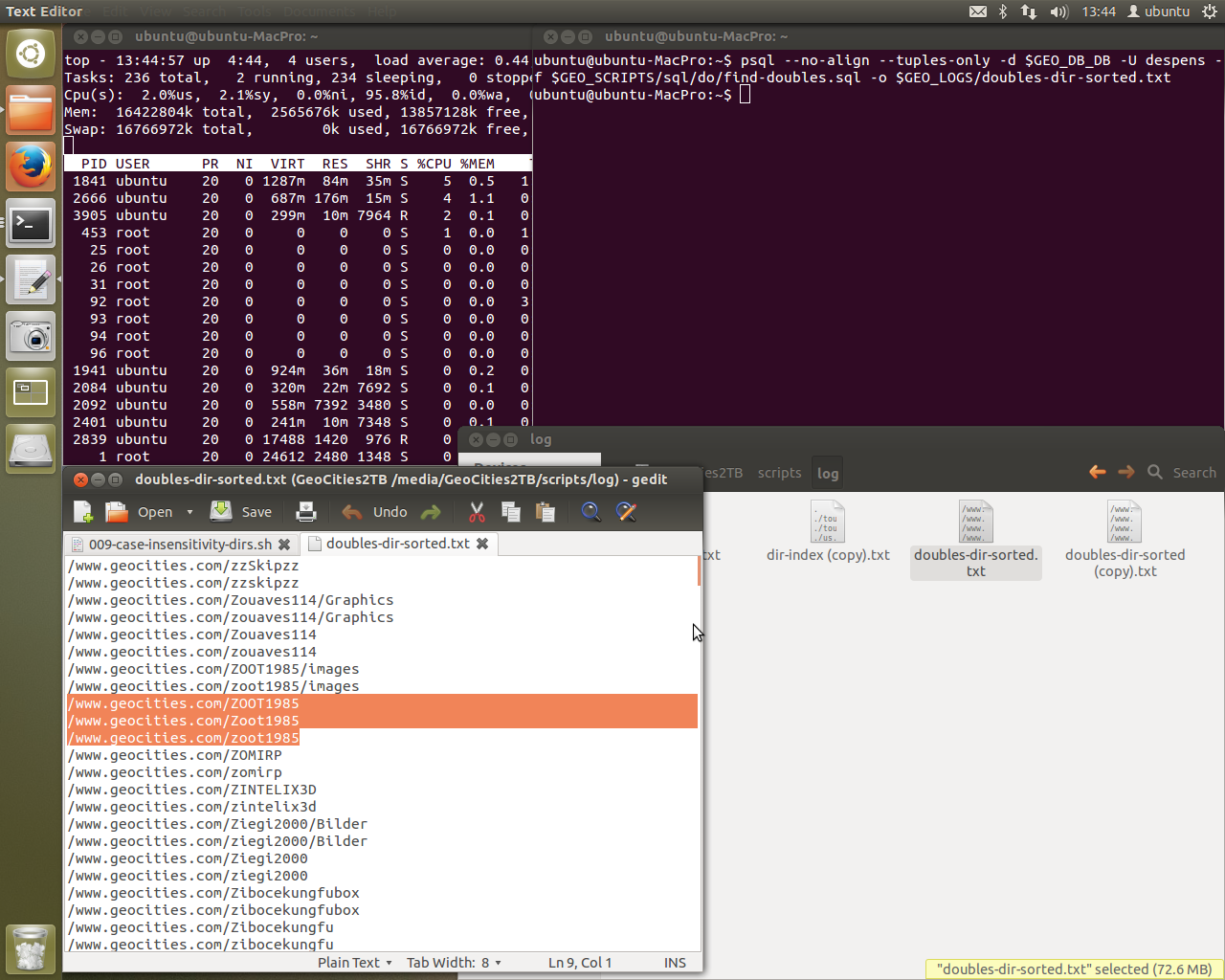
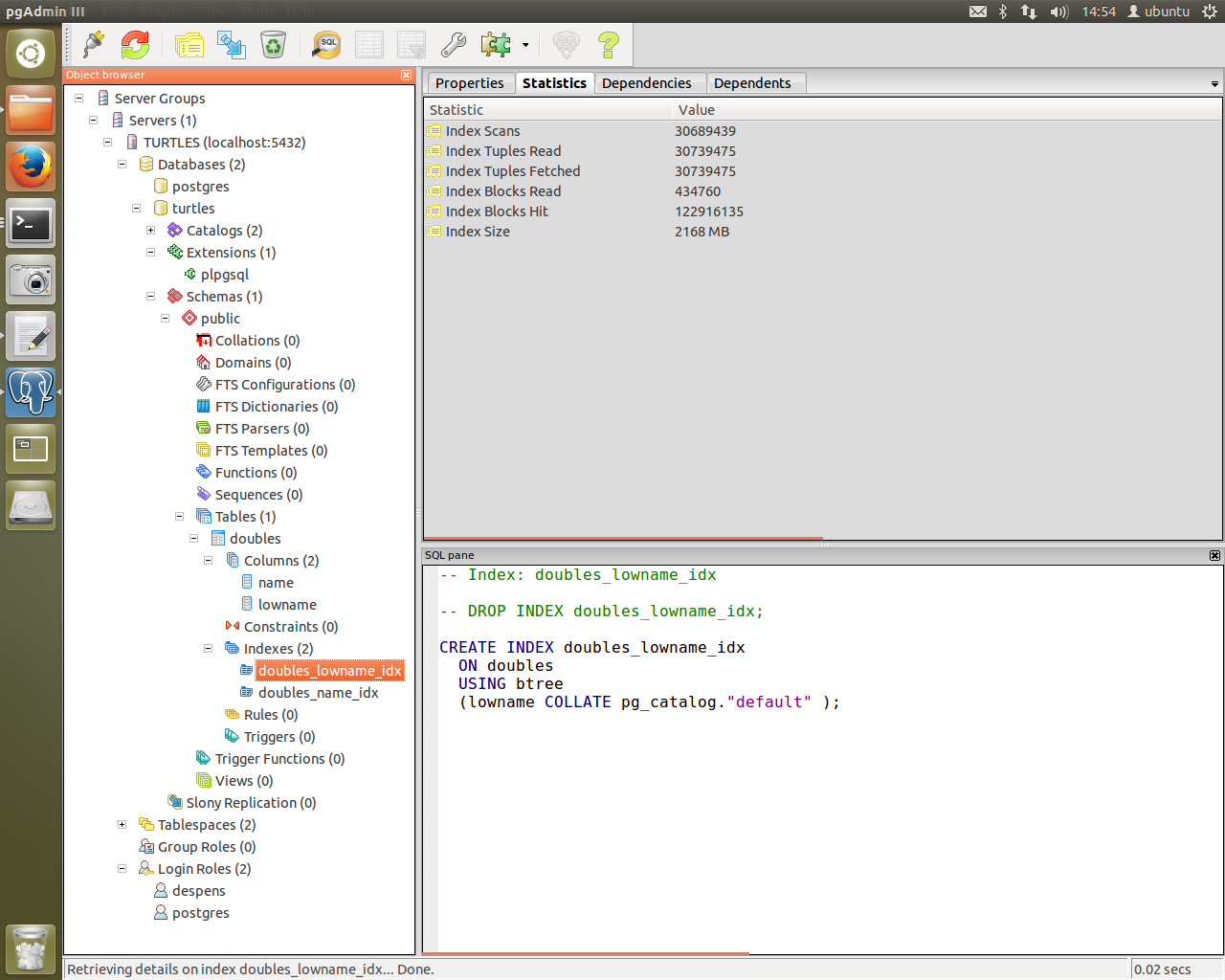
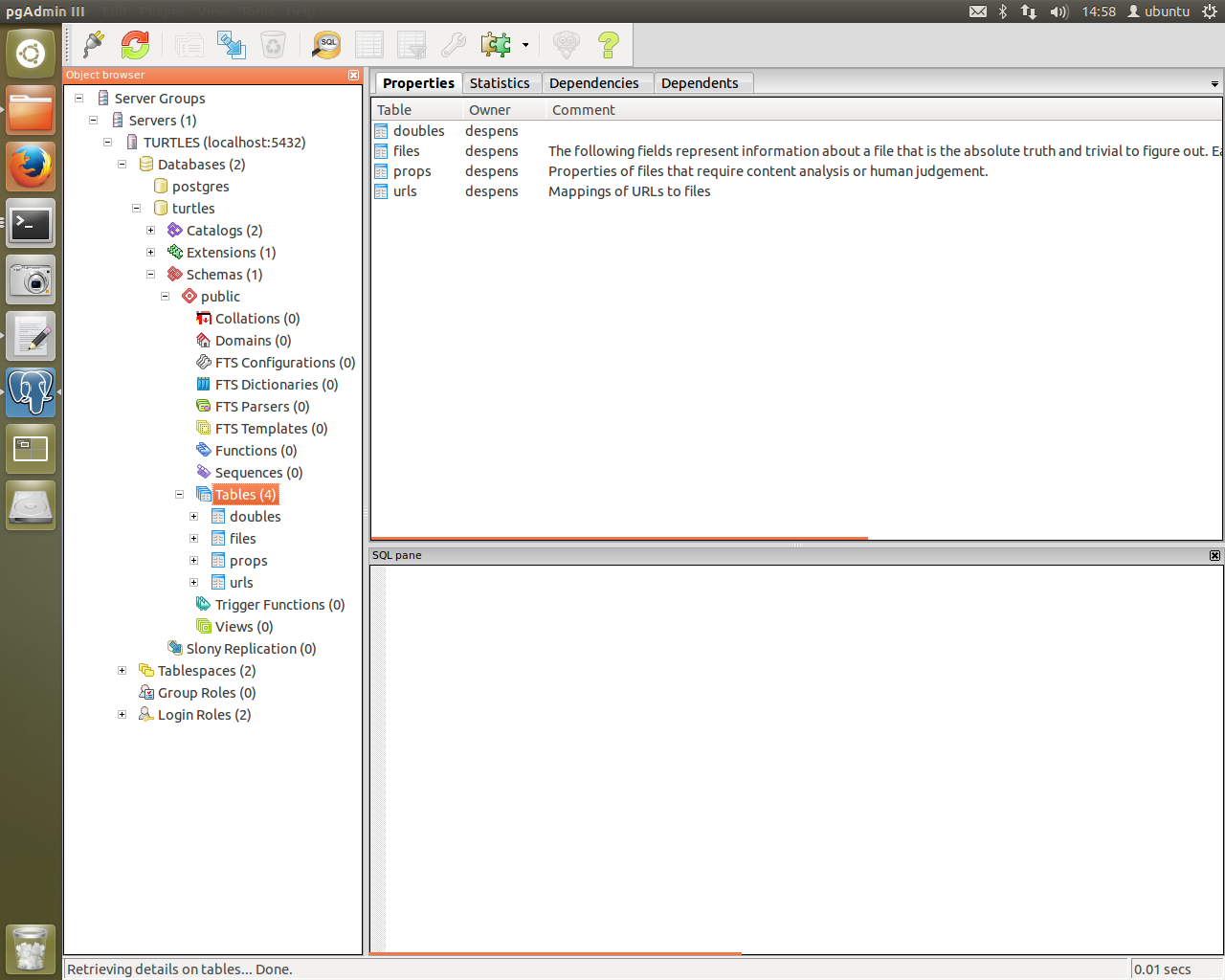
And we’re creating tables with ease. The table “doubles” didn’t exist but now it does and pgAdmin3 confirms it!
You can also see database creation through psql. It’s amazing to see it all come together. Of course, once this is up and running it can be improved upon further - as all things can. I still consider this to be at a testing stage as I am still learning how the systems in these scripts run.
After RetroChallenge 2022/10 is completed, I would like to start from step 001 to make sure I capture as much of the extra data added to the GeoCities archive after the core torrent was released. It would be great to modernise it to a newer Ubuntu system, such as 22.04, but I need to make sure I have the steps as correct as possible in 12.04 first. Regardless of what is done in the future, we’re moving forward now and that’s where we need to be!