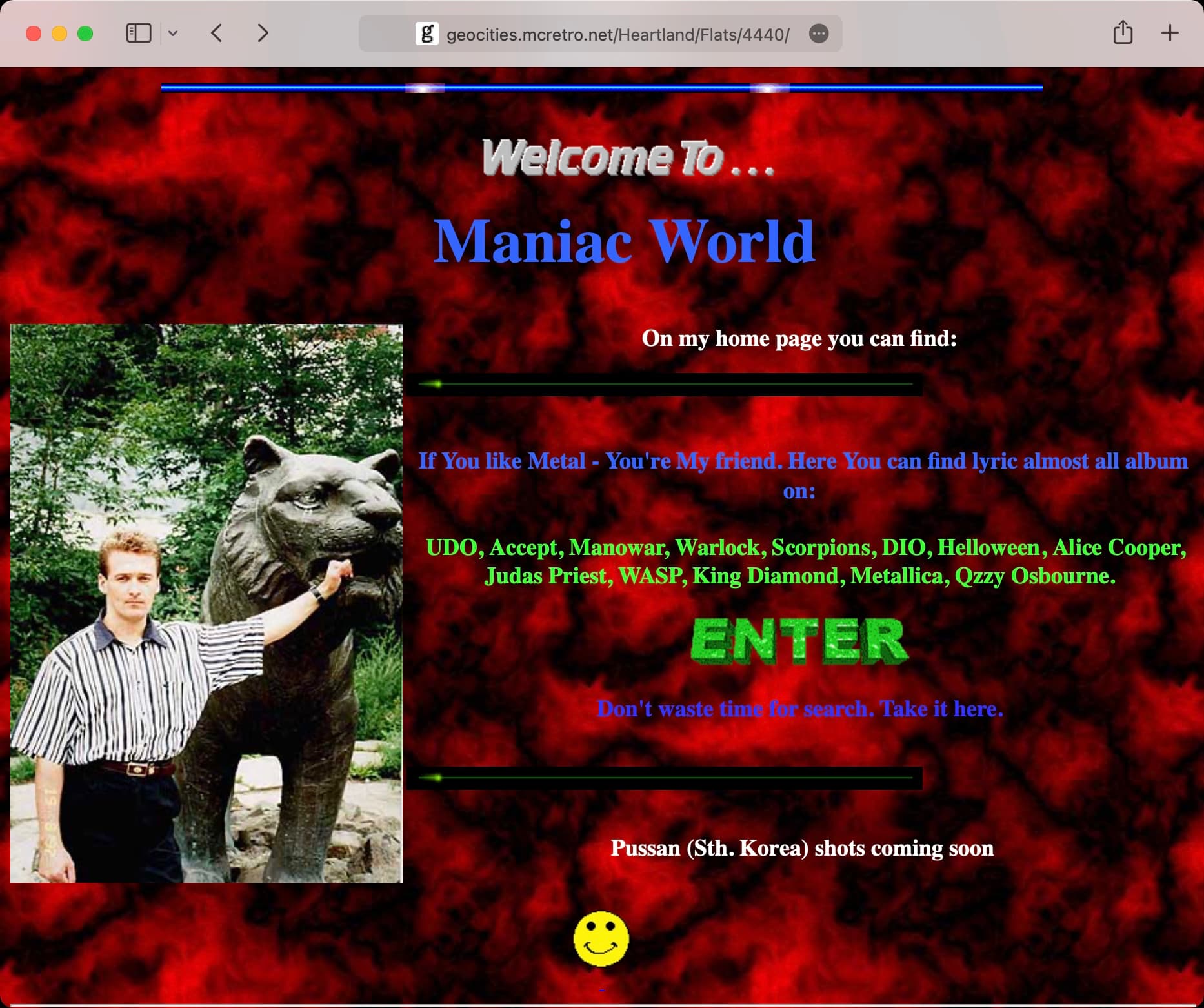
")
The above video shows the rm command running through stripping static, server-generated index.html files away. Recapping yesterday:
- Found and removed all index.html files from directory listings

- Removed 0 byte files, removed 0 byte folders (in that order)
- Started to clean up some of the redirection looped files and folders.
- Less than 1TB of data is present now.
- Symlinks were all deleted (again) - we need mod_speling to work properly.
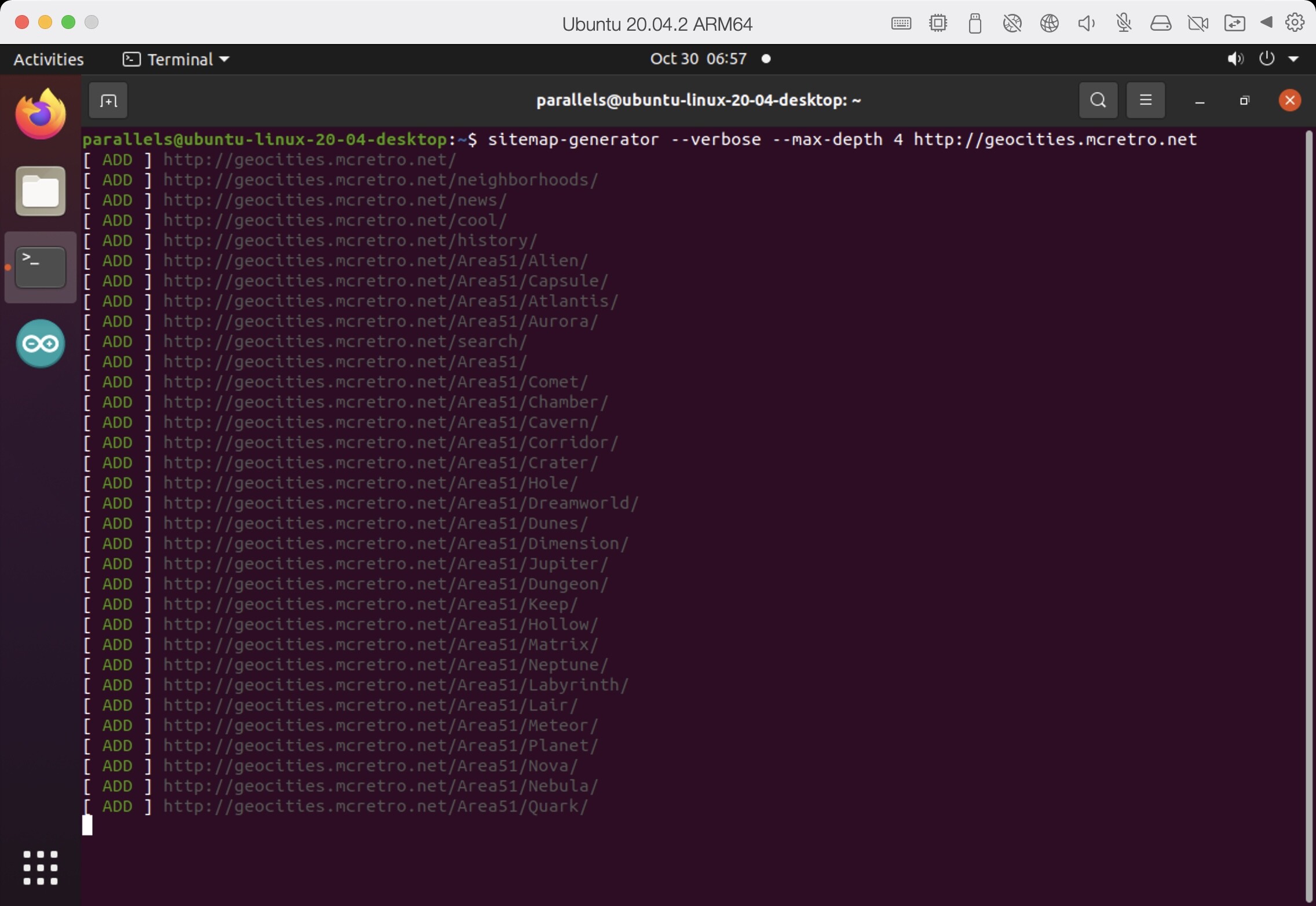
- Sitemap has been created successfully and is now split into smaller chunks.
- The jump script now covers all neighborhoods and is a fair bit quicker.
Onto number three in the list. Cleaning up files and folders that suffered from redirection loops when being harvested by Archive Team.

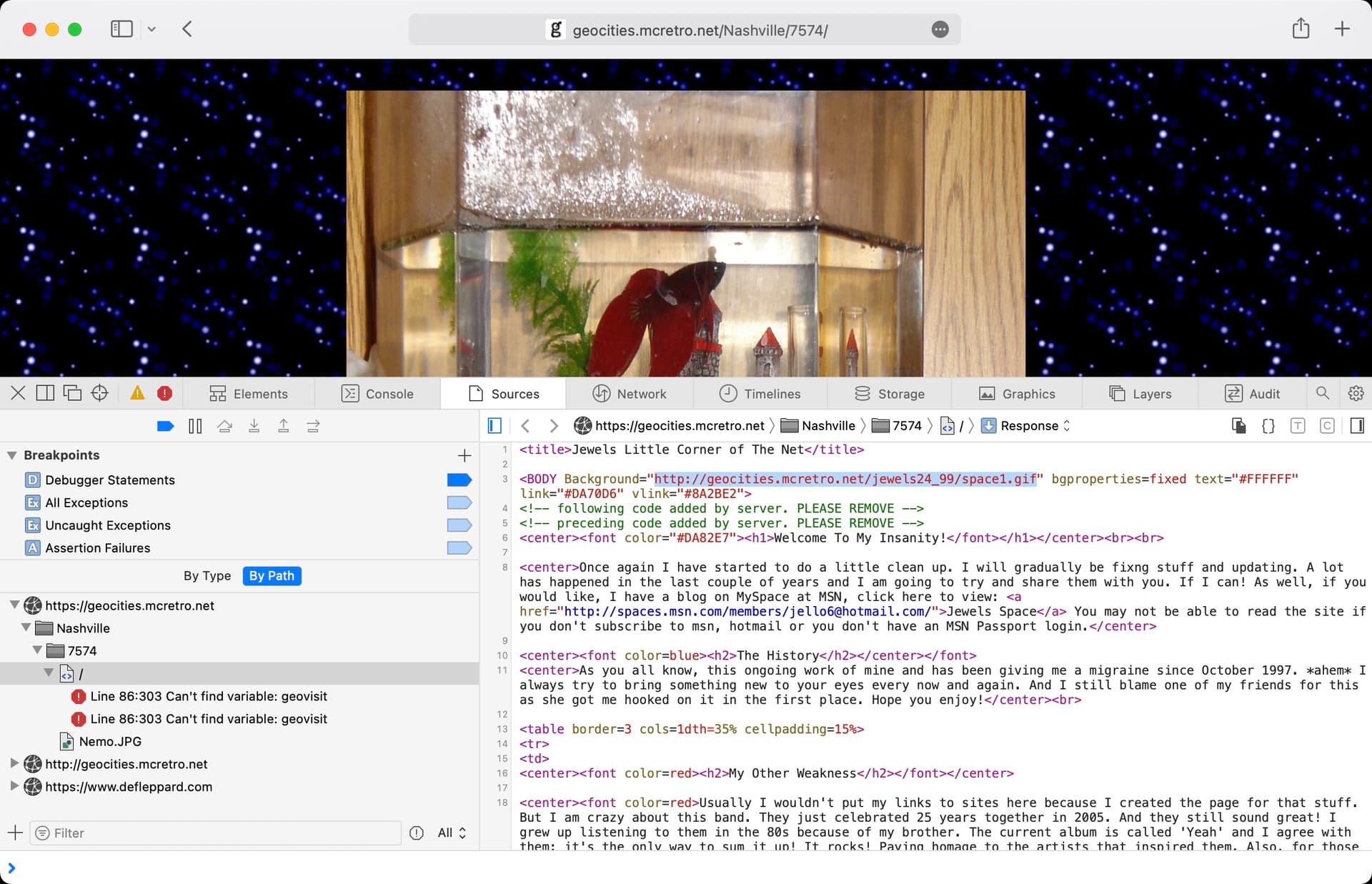
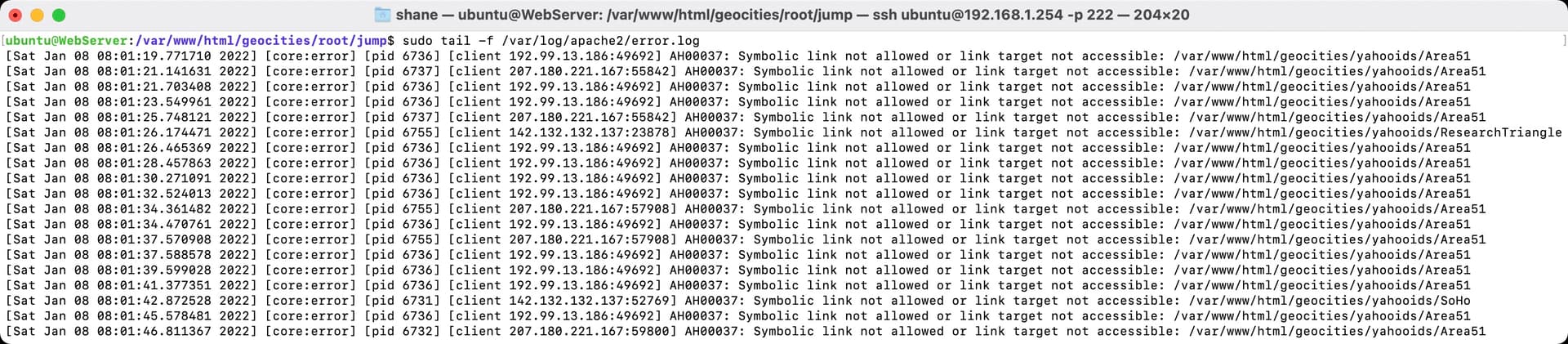
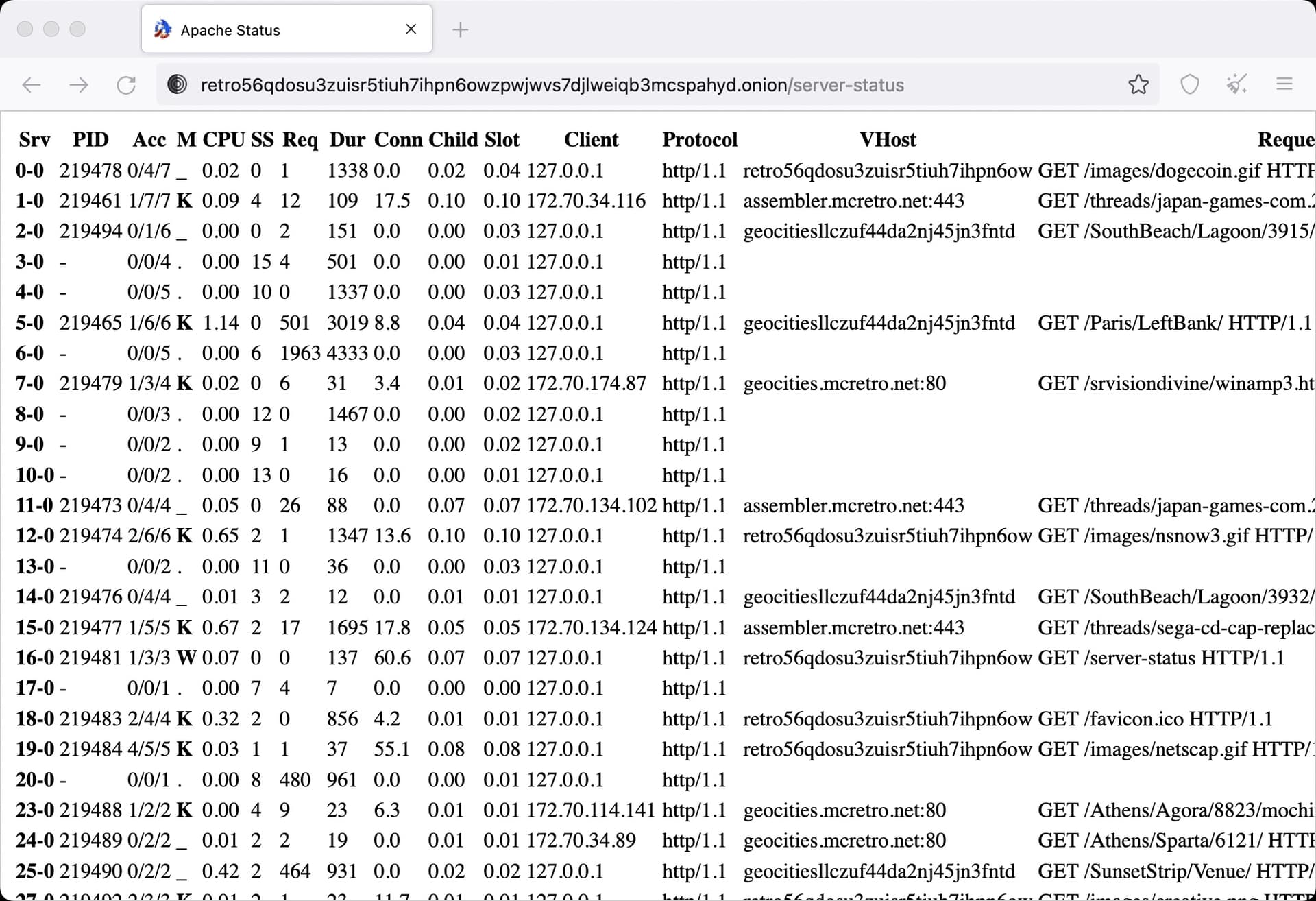
While looking for empty directories, the longest of the long path lengths appeared. The above image shows an example of this output. The redirection loops (recursive loops) get a little extreme sometimes. For the purposes of this project, as long as they keep below the maximum path length, we are OK.

The above image shows an example of what a typical loop would look like in Finder. At the time of writing the longest one we have is around 220 characters which is more than acceptable. The web crawler / spider would have been going a little insane finding a link within a link that was a link to itself inside a link, inside another link, linked to another link, etc., etc.
Running the following command will show the 10000 longest pathnames:
find . | awk '{print length($0), $0}' | sort -n | tail -n 10000
I’ve run this command a few times now and fixed the loops by deleting duplicated data. One interesting error I’ve come across is seen in the next image.
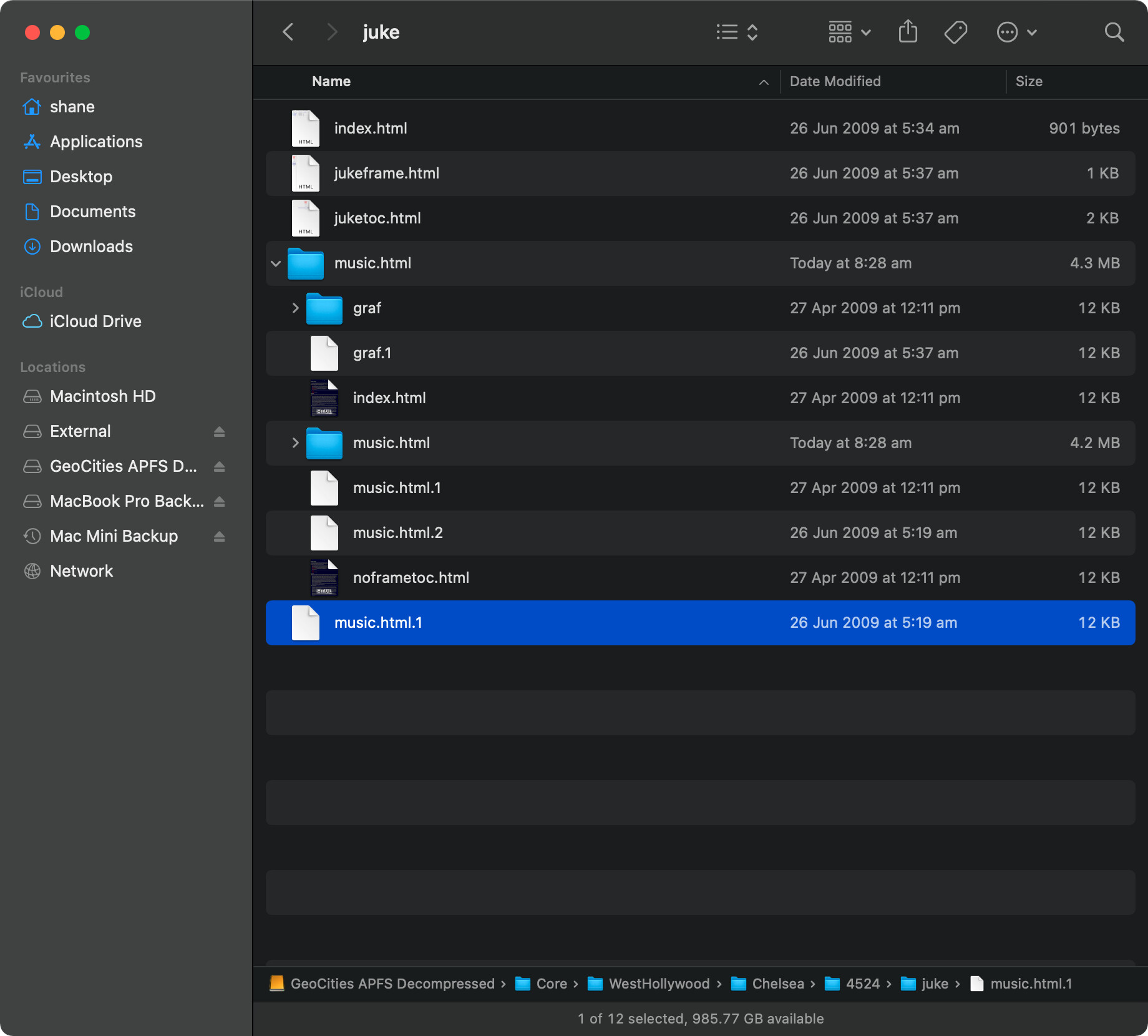
In particular, take note of;
- The file names music.html and it’s variations and,
- The file sizes.
The correct music.html is the file named music.html.1. However, all the files in the music.html folder are also the same music.html.1 file. It doesn’t seem to happen on every recursive loop, but has happened enough for me to take note on how to fix it.
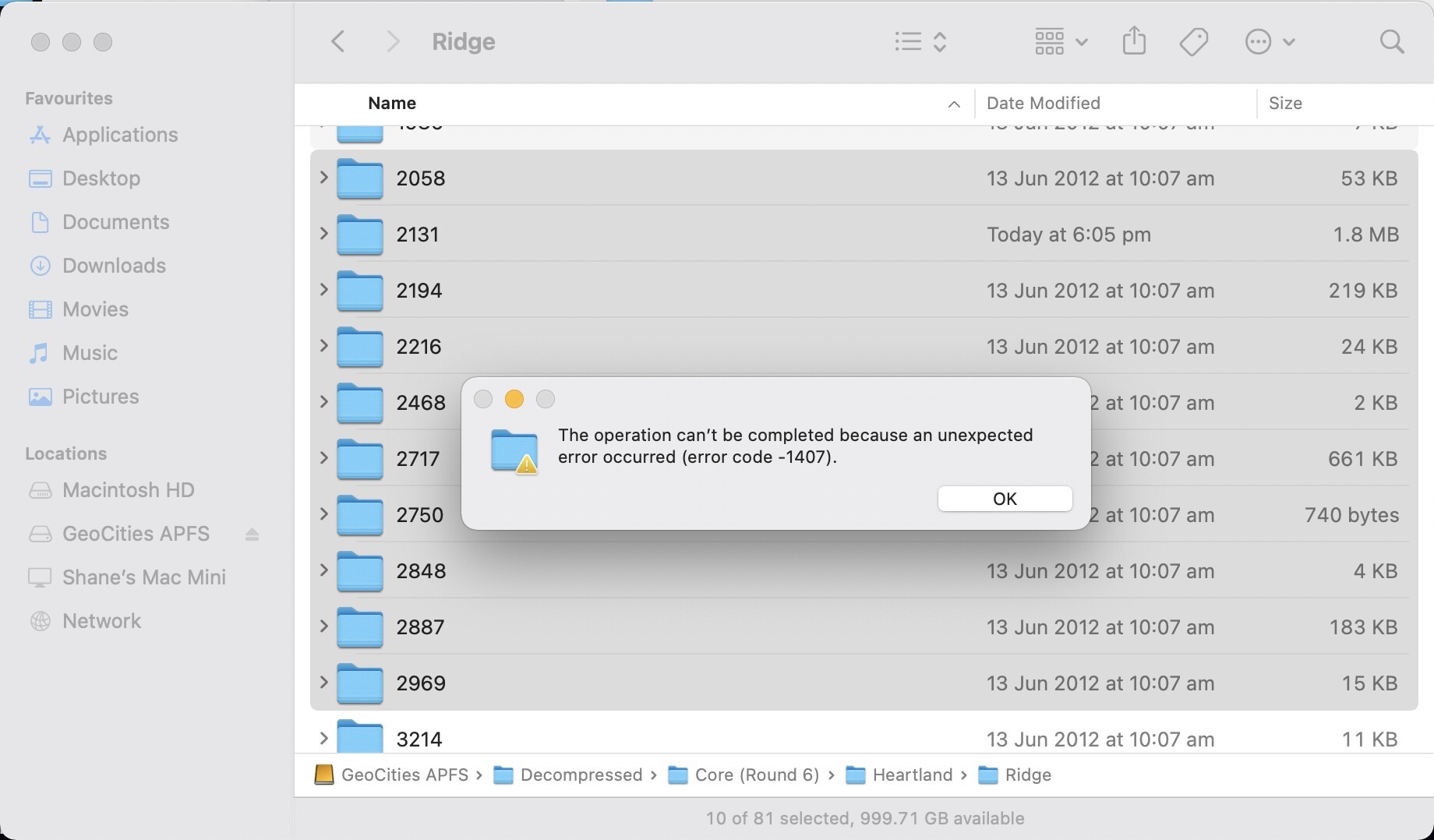
Deleting these has helped dip the entire decompressed data set below the 1TB mark. Some of those loops were big, causing folders to inflate to gigabytes. I should really run a search on folder size to detect any excessive utilisation of hard drive space. Low priority for now. But it does mean I can backup onto a 1TB drive/partition in full now. Lucky!
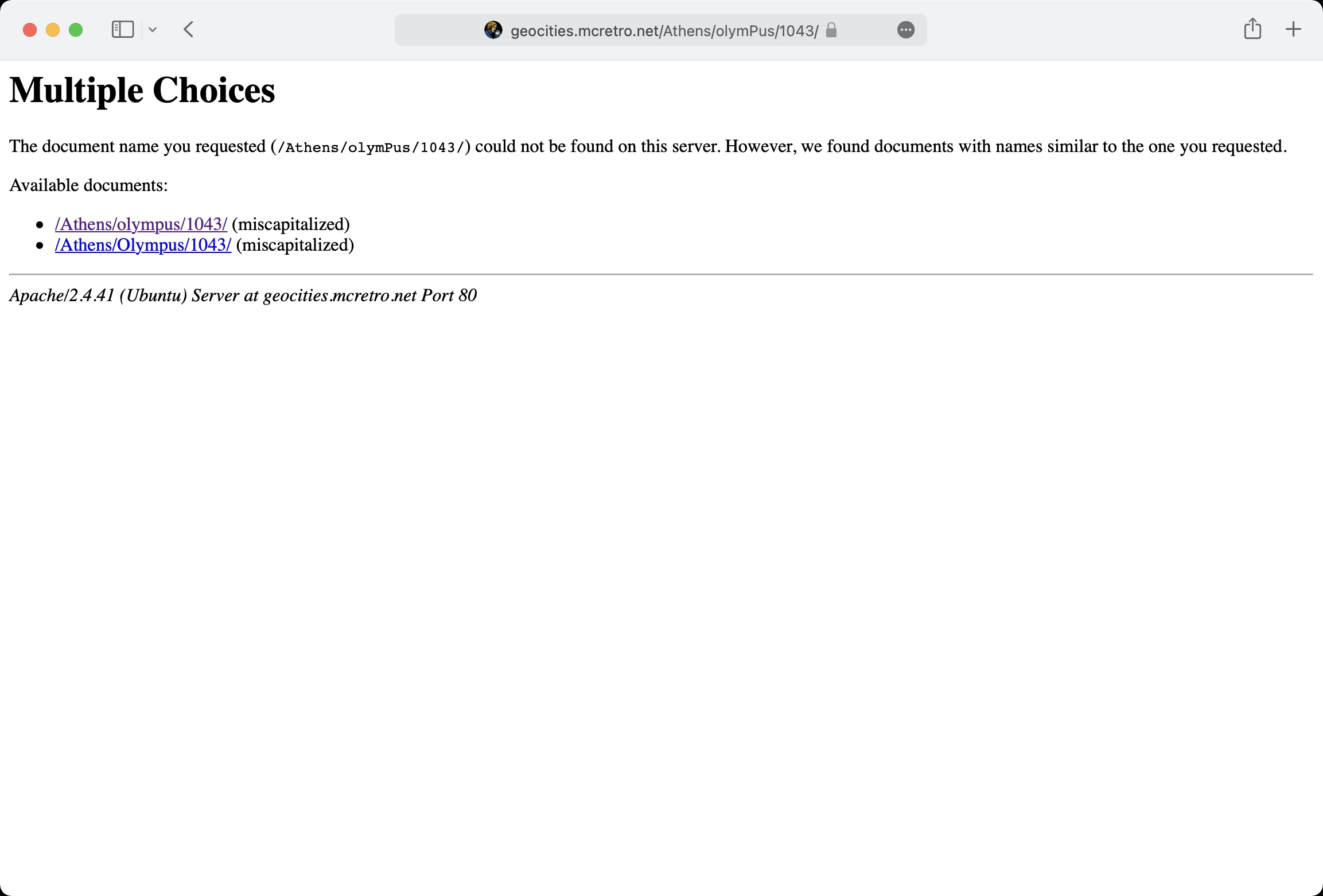
Touching on Apache’s mod_speling again, symlinks have all been removed from the local drive (not the server facing one, yet). If symlinks are present they have been confirmed to mess with mod_speling. This prevents correct redirections from happening. It’s more the nested directories that have issues. For example take:
> https://geocities.mcretro.net/Athens/olympus/1043/
> https://geocities.mcretro.net/Athens/Olympus/1043/
/Athens/olympus/ is not redirected to /Athens/Olympus/ as /Athens/olympus/ exists as a symlink. This causes issues for mod_speling as it can’t fix simple things like this as it sees two olympus folders, even though they are one and the same.
Additionally, the goal is to have everything in the correctly capitalised folders. i.e. Area51, SoHo, SiliconValley, etc. Any incorrect case will likely cause issues with mod_speling, breaking the ability to redirect correctly or locate source files - such as images and midis.
This means symlinks are off the menu again. They will only be used on the live server to fold the neighborhoods (/core/) into the much larger YahooIDs (/yahooids/). We need to give mod_speling the opportunity to thrive. We can always recreate symlinks if required as a last ditch effort.
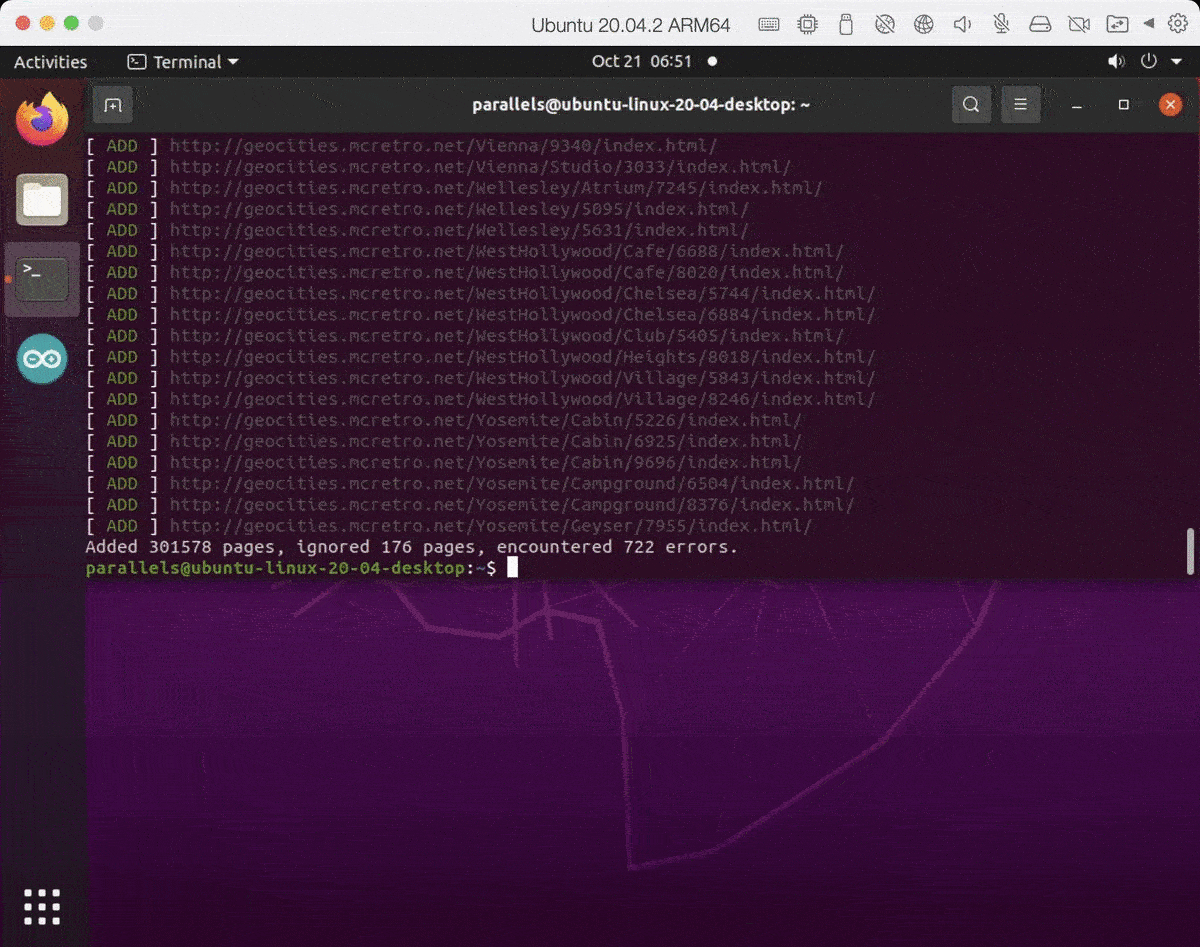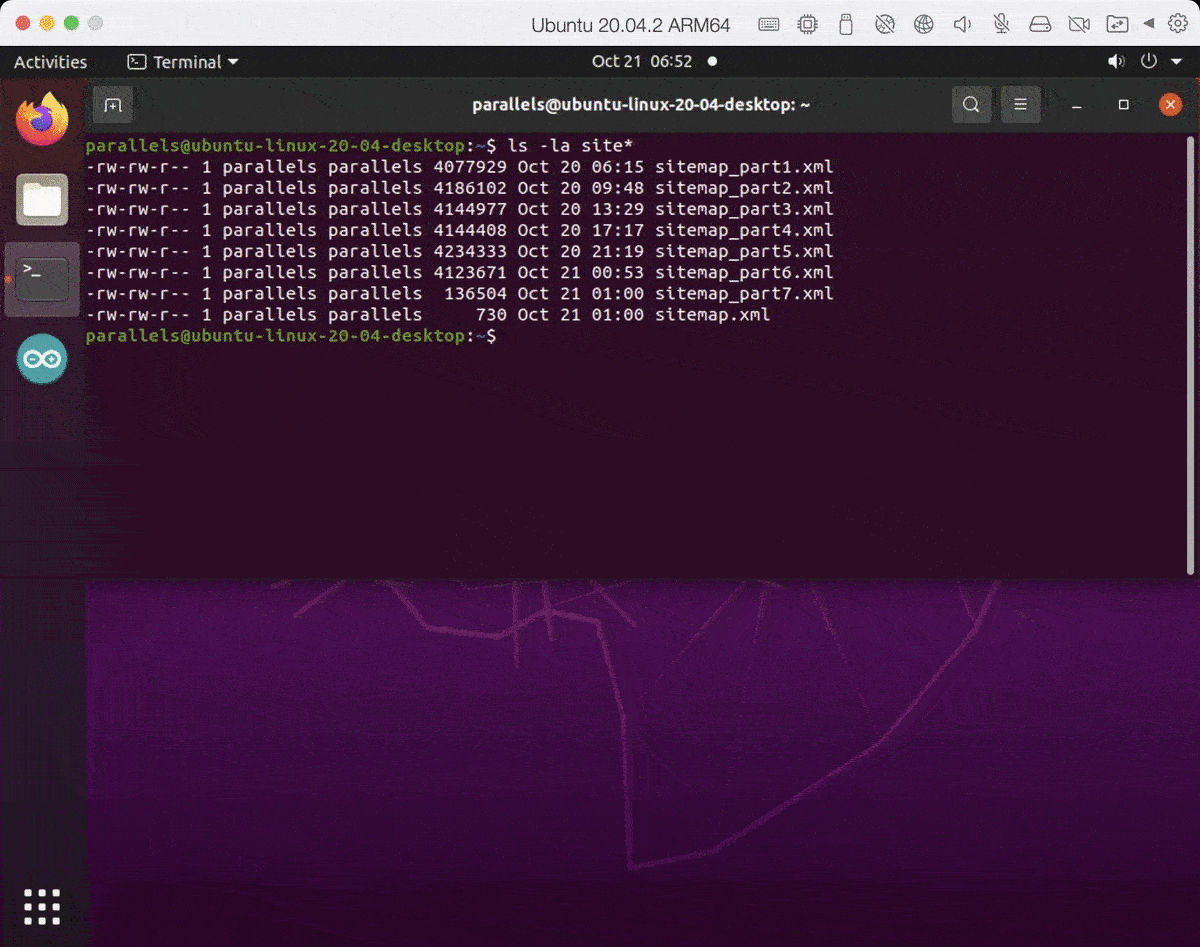
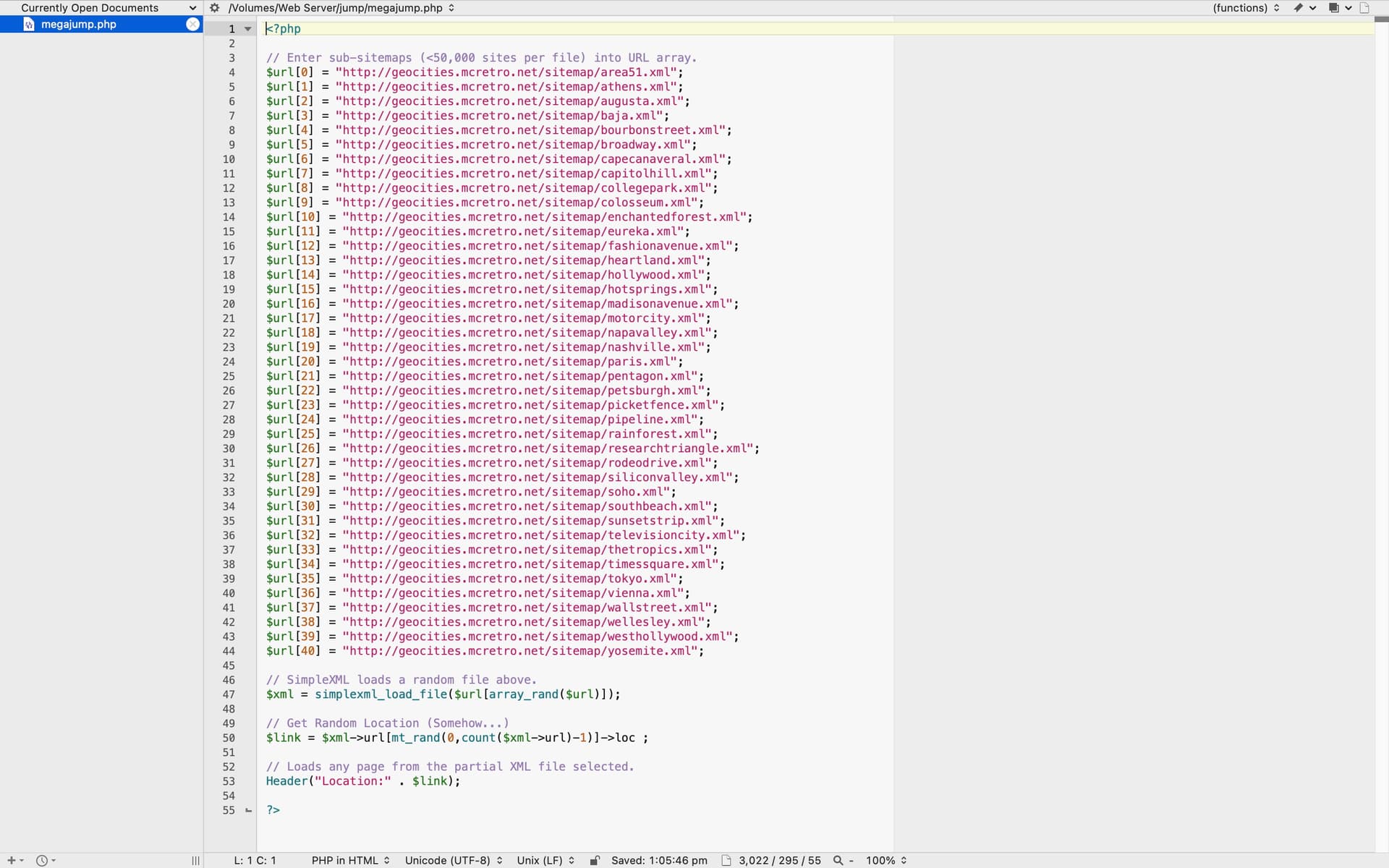
301,000 pages are now in the sitemap.xml split over seven files. That’s with a depth flag of 4. I’m scared to think how long it would take if we did the entire site. Now that the sitemap is working properly, it’s time to fix jump!
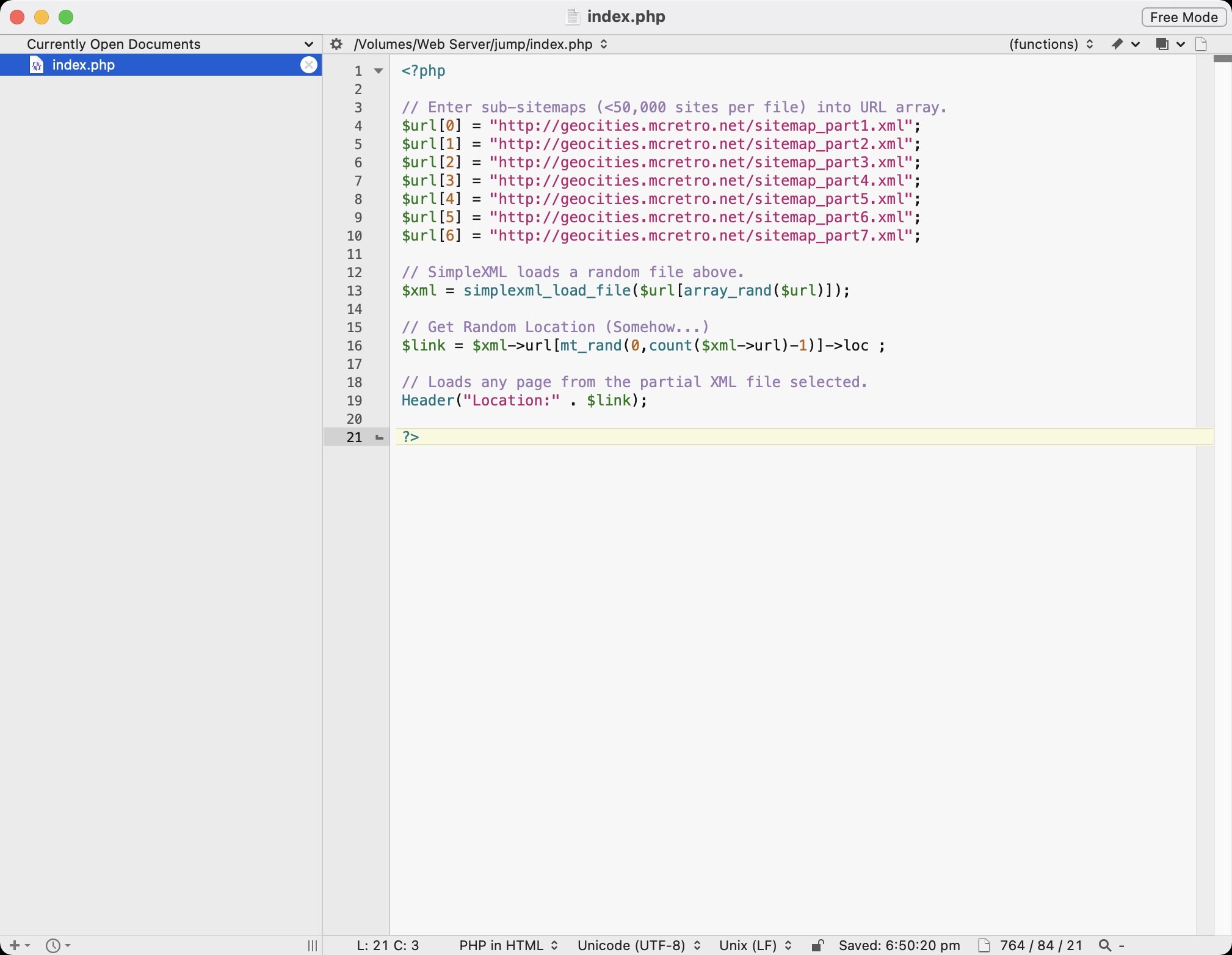
Jump definitely loads faster now and the stress on the weak Raspberry Pi CPU is clearly less when parsing the smaller sub-sitemap files. The amount of code I am running through the command line is fantastic.
I’ve been using awk, grep (and pcregrep for multiline matching), find, rsync and xargs. I think I am getting better at regular expressions (regex). Regex are extremely powerful provided you are using the right tool. I may have nearly wiped my desktop out (again) with an rm command so I was quite careful with what I was doing on the unbacked up work-in-progress.
The Future
The next steps over the week will be to continue sorting out the pictures and images from the rest of the decompressed data. I’ll be tidying up the YahooIDs to remove any core folders, such as Area51, Hollywood, etc. They can’t be left in the YahooIDs folder. That would cause pretty big issues when, for example, /core/Area51/ tries to mount at the same point as /yahooids/Area51.
I also need to continue to think about the best way to serve the images. Currently there are many locations images were stored at, including international sites. I need to work out the best way to write that into Apache’s mod_substitute. A sample of the website addresses is below:
- http://pic.geocities.com
- Yahoo | Mail, Weather, Search, Politics, News, Finance, Sports & Videos
- http://us.yimg.com
We create a simple /images folder and put the domains in our root directory and would look something like this:
/images/pic.geocities.com/
/images/geocities.com/pictures/
/images/us.yimg.com/
I think this is something like what Yahoo did when they took over in mid-1999 and again after a brand refresh in the 2000s. For the immediate future though… a backup.

Creating a snapshot of the progress so far, to rotational media, is a good idea. It should finish late tonight. I’ll then be able to work on merging neighborhood (core) data together. Not making a backup at this point could easily be disastrous. One more week and we should have a clearer picture of how everything looks.


")