Good finds! I moved the server from the Raspberry Pi 3 to the Raspberry Pi 4 this morning and in the process killed all the symlinks. This is why documenting the whole process was a great idea.
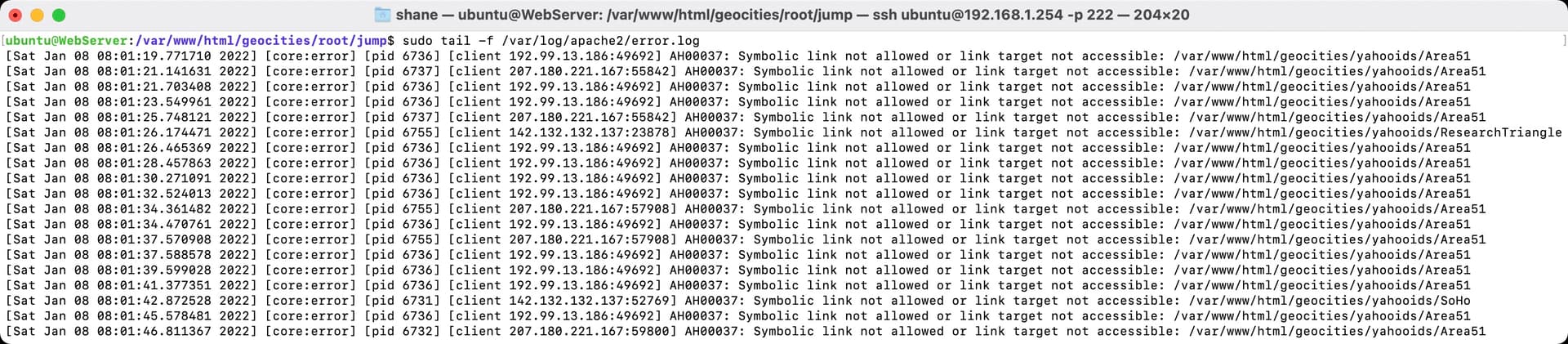
Apache (the web server software) was not happy with symlinks being broken. These are three very useful commands for debugging errors:
sudo tail -f /var/log/apache2/other_vhosts_access.log
sudo tail -f /var/log/apache2/error.log
sudo tail -f /var/log/apache2/access.log
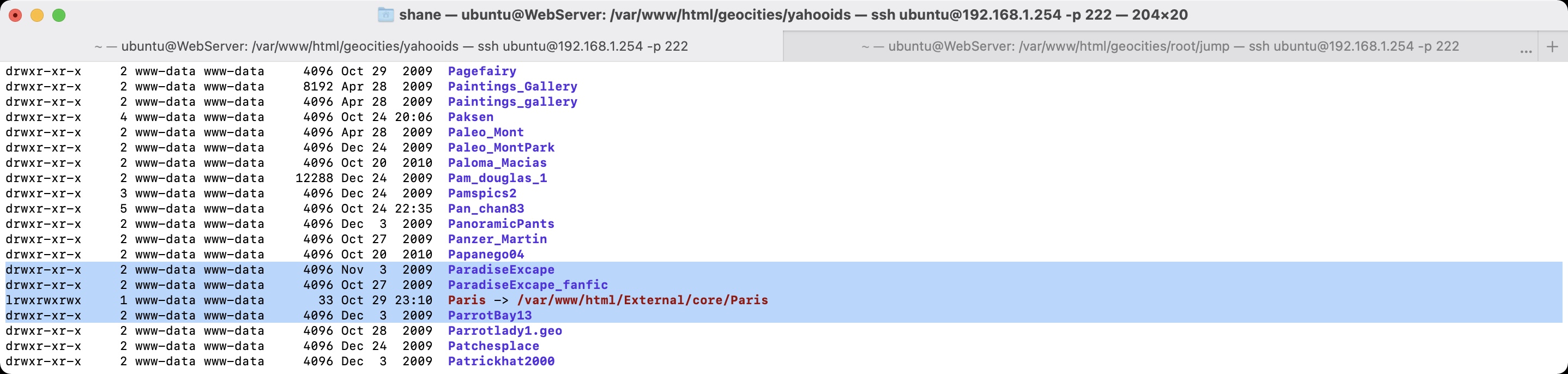
They even show up maroon! How did I manage this, I had renamed the external drive from “External” to “geocities” to help differentiate it from another project I had activated in the past week or so - The Assembler Games Archive. All my old symlinks died as a result.

I ran a test to make sure I wasn’t going to wipe out the entire internet first - i.e. without sudo tacked on the front of the command I stole from the internet. It worked, it found all the correct symlinks to remove and them I did!

Here’s the command that brought them back to life. The neighbourhoods need to be inside the yahooids subfolder for everything to work nicely.
And we’re back. You’re right @EdS, we should make a new thread with retrocomputing relevant finds from GeoCities Archive.