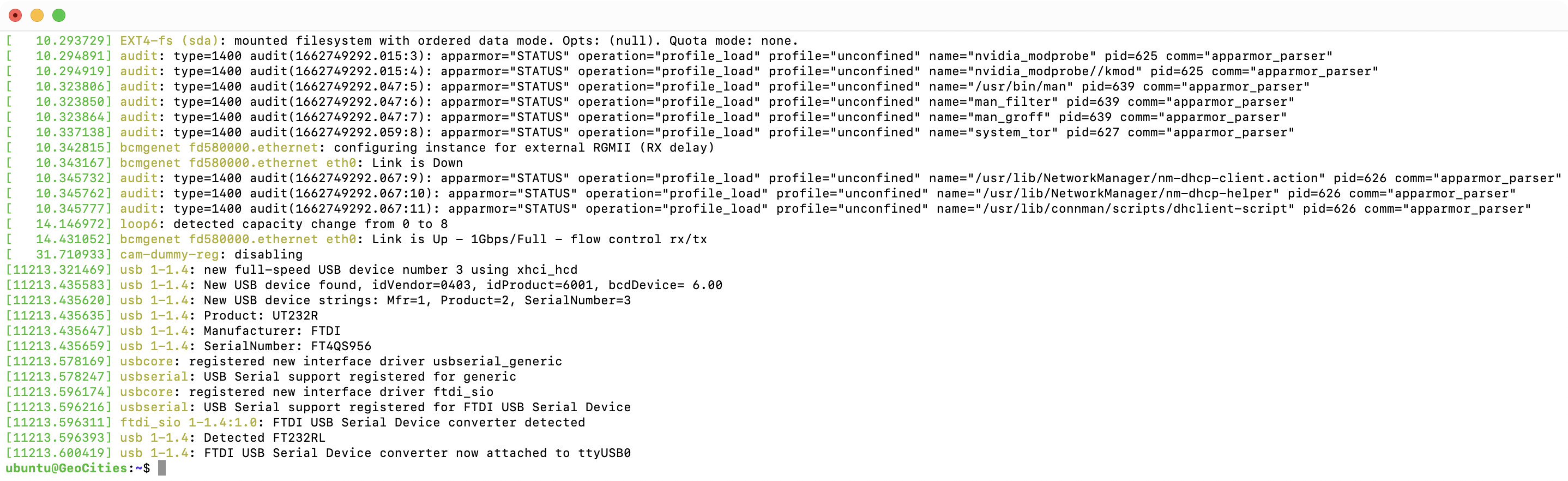
The first step troublesome step to getting online is picking the right serial adapter. I’ve had the most luck with my FTDI USB serial device converter which has a FT232RL chip. I’ve previously used Prolific chipsets with mixed results.

Next up was getting the pesky VoIP configuration setup. The above shows Asterisk running before the two SIPs activated.This indicates that the Cisco SPA8000 can communicate successfully with the Asterisk server on the Raspberry Pi.
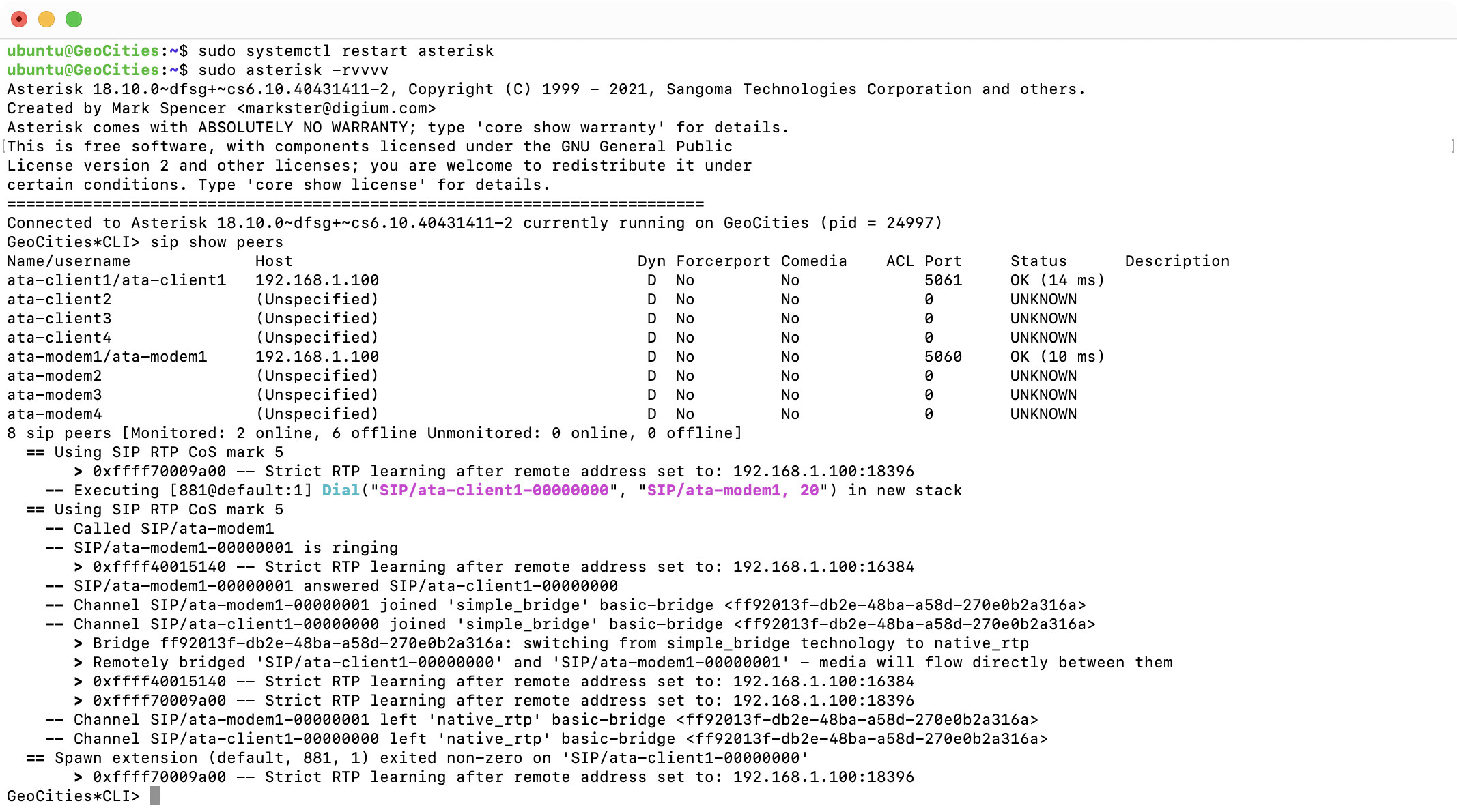
Here we have me restarting Asterisk, and I was wondering why it wasn’t working after changing the config files… tsk tsk! Once rebooted a dial from the Windows 98 in the MiSTer resulted in a successful connection and right at the end a hang-up when I was done surfin’ the net.
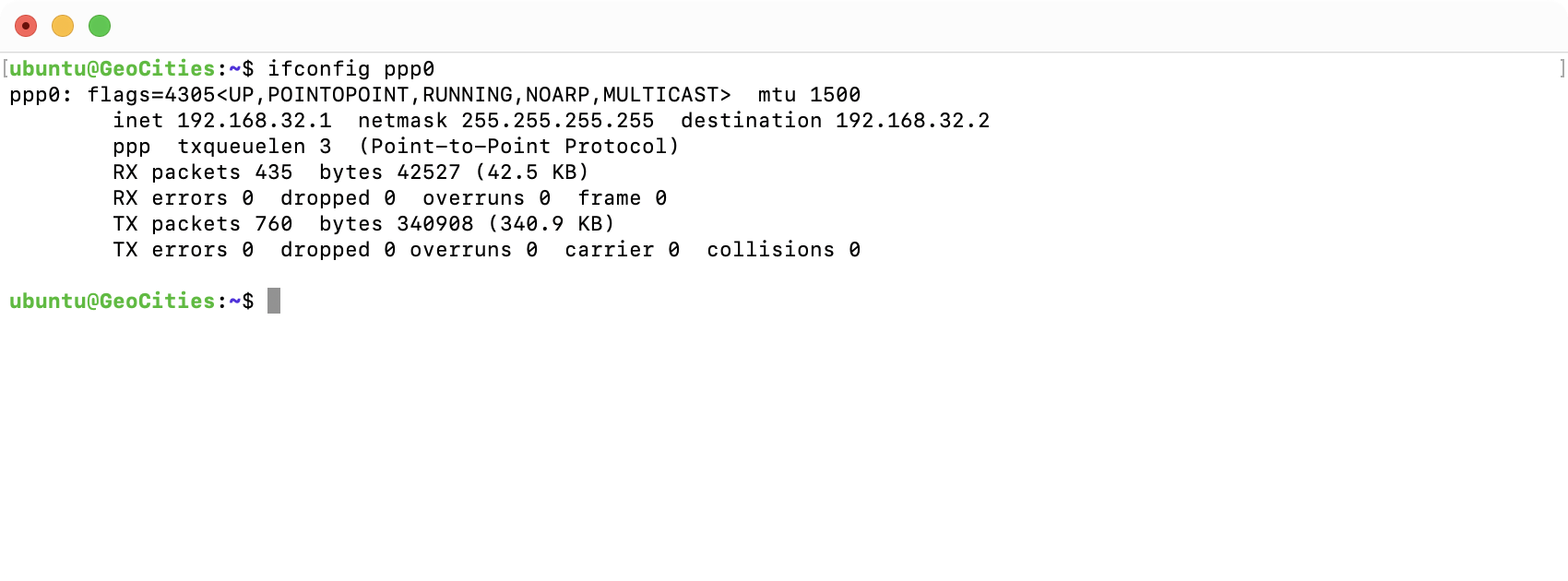
What was even better is that on the Asterisk / GeoCities server is we can see that there are no RX or TX errors after 380kB of data going back and forth. I’m setup with a 14.4k modem, and let me say it took a while to get to that amount of data! ![]()
I’ll get some video of everything happening to give an idea of how it all works. It’s been a surprising success and has put me way ahead of schedule too. Stay tuned for the video update in the next post! ![]()